
- (Обновлено: ) Евгений Аралов

Анализ конкурентов — важный этап при продвижении сайтов. В этой статье я покажу, какую полезную информацию можно извлечь у конкурентов для улучшения внутренней оптимизации своего сайта.
В интернете достаточно много написано об анализе сайтов конкурентов и на нашем блоге в этом году уже была подобная статья. Однако это была переводная статья, в которой своим опытом делился зарубежный специалист. Сегодня я хочу поделиться с вами своими наработками на эту тему.
Семантическое ядро
Чтобы успешно развиваться и увеличивать видимость сайта в современных реалиях, необходимо постоянно расширять семантическое ядро. Одним из лучших способов расширения является сбор ключевых слов конкурентов.
Сегодня получить семантику конкурентов не составляет труда, т.к. существует множество сервисов, как платных, так и бесплатных.
Список бесплатных:
— megaindex.ru — инструмент «Видимость сайта»
— xtool.ru — всем известный сервис, который также показывает ключевые слова, по которым сайт ранжируется
Список платных:
— spywords.ru — подходит для Яндекс и Google
— semrush.ru — ориентирован только под Google
— prodvigator.ua — украинский аналог spywords.ru
В дополнение к сервисам можно использовать и ручной метод, основанный на разбиении title и description на n-граммы, вследствие чего на выходе получается дополнительный список фраз.
N-грамма — последовательность из n элементов. На практике чаще встречается N-грамма как ряд слов. Последовательность из двух последовательных элементов часто называют биграмма, последовательность из трех элементов называется триграмма. Не менее четырех и выше элементов обозначаются как N-грамма, N заменяется на количество последовательных элементов.
https://ru.wikipedia.org/wiki/N-%D0%B3%D1%80%D0%B0%D0%BC%D0%BC
Рассмотрим данную методику по шагам:
— Выгружаем title (description) конкурентов. Можно сделать с помощью программы Screaming Frog SEO.
— В текстовом редакторе чистим получившийся список от служебных частей речи, знаков препинания и прочего мусора. Я использую в текстовом редакторе sublime text функцию «поиск и замена» (горячая клавиша ctrl+H), применяя регулярные выражения:

— Далее копируем список в сервис https://guidetodatamining.com/ngramAnalyzer/.
— Выбираем нужную n-грамму и ставим частоту не менее одного. Самый оптимальный вариант — это триграммы и 4-граммы:
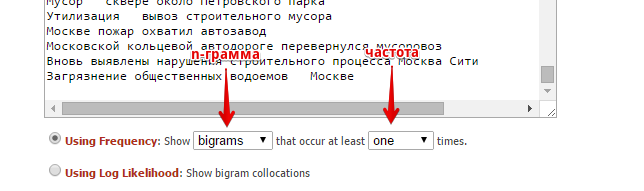
— Получаем следующий результат:
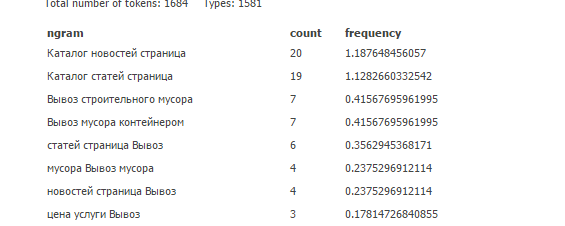
Столбец count показывает количество повторений n-грамм, столбец frequency —частоту n-граммы.
После того как мы получили список фраз, нужно его проанализировать и выбрать подходящие ключевые слова для расширения семантического ядра. Подробнее о семантическом ядре можно узнать в соответствующем разделе нашего блога.
Группировка запросов
Очень важно понимать, как группируется семантическое ядро у конкурентов, т.к. это помогает правильно распределить ключевые фразы на страницах сайта.
Для этого после того как мы сформировали полный список запросов, нам необходимо получить релевантные страницы и позиции конкурентов (можно с помощью сервиса seolib.ru), а потом сравнить со своей группировкой. Если видно, что конкурент занимает хорошие позиции и при этом его группировка отличается от нашей (например, у конкурента запросы распределены на разные страницы, а у нас такие же запросы сидят на одной), нужно обратить на это внимание и пересмотреть посадочные страницы на своем сайте.
Рассмотрим небольшой пример сравнения группировки условного сайта и его конкурента.

Как видно из таблицы, на сайте site.ru выбрана одна посадочная страница для всех ключевых слов. У конкурента по этим же запросам ранжируются разные страницы и занимают ТОПовые или близкие к ТОПу позиции. Исходя из этого, можно сделать вывод, что группировку на site.ru необходимо пересматривать, в частности необходимо создать отдельную страницу для ключевых фраз со словом «фасад».
Качество текстов
Первое и самое важное, на что следует обращать внимание при анализе текстов конкурентов, это не на количественную составляющую (количество вхождений, объем текста и т.д.), а на качественную или смысловую — насколько полезная информация, что предлагает конкурент и как он это делает.
Рассмотрим несколько примеров.
Допустим, вы занимаетесь доставкой цветов и на главной странице в тексте вы гарантируете их свежесть. Например, так:
Служба доставки цветов site.ru гарантирует сохранность букетов даже в холодное время года.
А вот пример у одного из конкурентов:
Заказывать ароматные композиции выгодно именно у нас, потому что мы гарантируем 100%‑ый возврат денег, если свежесть цветов вызывает сомнение.
У конкурента гарантия подкреплена деньгами, что более существенно, чем абстрактная гарантия.
Рассмотрим еще один пример — текст на странице категории «керамическая плитка» интернет-магазина:

Этот текст не несет никакой полезной смысловой нагрузки, сплошная вода. Скорее всего, человек, который пришел на сайт и принимает решение о покупке, хочет узнать преимущества товара и возможные комплектации, вместо этого он получает бессмысленный набор символов.
Теперь посмотрим на текст у конкурента:

Данный текст более полезен, т.к. лаконично сообщает о различиях плитки и помогает понять, как ее правильно выбрать.
Таким образом, сравнивая тексты конкурентов со своими, вы можете получить много полезной информации, которая поможет при составлении ТЗ копирайтерам.
Релевантность текстов
Продолжая тему качества текстов, нельзя не коснуться их релевантности. Сегодня для того чтобы текст был релевантным, недостаточно только вхождения ключевых слов. Чтобы увеличить релевантность страницы и при этом не сделать текст спамным, нужно использовать слова, связанные с тематикой.
При оценке релевантности текста запросу поисковая система анализирует не только наличие ключевых слов, но и дополнительные слова, определяя таким образом смысл текста. Например, если мы пишем текст про слона, то связанными словами можно считать: «хобот», «бивни», «природа», «зоопарк». Если текст про шахматную фигуру «слон», то такими словами будут: «фигура», «шах», «ферзь» и т.д.
Получить наиболее подходящий список слов под ваши запросы можно в текстах конкурентов. Для этого нужно проделать следующие шаги:
— Копируем все тексты из ТОП-10 по нужному ВЧ запросу в разные текстовые файлы.
— Из текстов удаляем служебные части речи, знаки пунктуации и цифры (рассматривали ранее).
— Выстраиваем слова в строку — используем функцию «поиск и замена» с регулярными выражениями. Заменяем пробел на \n.
— Далее необходимо привести все словоформы к нормальной словарной форме (леме). Для этого можно воспользоваться сервисом https://tools.k50project.ru/lemma/. В поле надо внести список слов из каждого файла по отдельности и нажать кнопку «лемметизировать и вывести в виде csv‑таблицы». В итоге должно получиться 10 файлов с лемметизированными словами.
— В каждом файле удаляем дубликаты слов.
— Объединяем слова из файлов в один список.
— Теперь нужно создать частотный словарь. Для этого полученный список добавляем в сервис https://tools.k50project.ru/lemma/ и нажимаем «построить частотный словарь в виде CSV».
— Наш список слов готов:

Если частота 10, значит, данное слово использовалось на всех 10-ти сайтах, если 8, то только у 8‑ми и т.д. Рекомендуем использовать наиболее частотные слова, однако и среди редко встречающихся слов можно найти интересные решения.
Вот таким простым способом вы можете получить список тематических слов для составления ТЗ копирайтерам.
Как видно, конкуренты являются очень важным источником информации, которая может помочь лучше оптимизировать ваши сайты. В данной статье я охватил далеко не все аспекты, и в будущем буду продолжать писать о том, что полезного и как можно извлечь у ваших конкурентов.
Еще по теме:
- Как не терять трафик из товарных карточек, если товара нет в наличии? Нередко владельцы интернет-магазинов сталкиваются с тем, что на сайте скапливается большое количество страниц с отсутствующим товаром. С одной стороны, карточка товара – это источник поискового...
- Критично ли не использовать тег canonical и закрывать страницы пагинации в файле robots.txt? Расскажите, пожалуйста, насколько критично не использовать тег canonical и закрывать страницы пагинации в файле robots.txt. Хочется выяснить больше нюансов и принять решение, стоит ли вносить...
- Как использовать символы Unicode в Title и Description для привлечения пользователей из выдачи Что такое спецсимволы Юникода и HTML Зачем они нужны в заголовке и описании страницы Правильное использование специальных символов и «всё хорошо, что в меру» Как...
- Сезонность запросов в Яндекс и Google или как развивать сезонный проект Как собирать сезонные запросы Виды сезонных запросов Инструменты для определения сезонности Как и когда собирать сезонные фразы? Сезонность запросов в Key Collector Как продвигать сайт...
- Как правильно реализовать динамический текст в теге Н1, чтобы он был доступен для индексации? Динамический текст в h1. Как правильно с точки зрения SEO реализовать появляющийся с помощью js текст (анимация печати), ведь для поисковых роботов текст не виден?...

Оцените мою статью:

 (15 оценок, среднее: 4,93 из 5)
(15 оценок, среднее: 4,93 из 5)Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.


По поводу семантики — есть интересный инструмент адводка; позволяет выгрузить органику/контекст конкурента (правда — только по 2 регионам). В общем — как вариант расширения семантики. По поводу релевантности текстов, есть хороший зарубежный инструмент — nichelaboratory.com у которого только 1 проблема — он не воспринимает русскоязычные сайты. Но для тех, кто работает с западным рынком — вариант отличный.
Классная статья , спасибо больше такого материала
А я для этих целей использую yazzle , он делает всё это сам
Подскажите, всем известный сайт — x-tools.ru вообще хоть когда-то работает? Спасибо)))
В названии сайта опечатка, https://xtool.ru/ работает, а xtools.ru нет. Исправили, спасибо.
Еще не до конца исправили. Черточку из домена уберите в самой статье. А то там сайт оборудования для телекоммуникаций открывается.
Xtool пользуется базой от мегаиндекса.
Прокоммнтируйте, пожалуйста, регулярное выражение, которое Вы используете, чтобы чистить от знаков препинания и служеьных частей речи () я не специалист в регулярных выражениях, но хотелось бы понять, что именно оно выбрасывает.
Здравствуйте.
Распишу по блокам:
— (\b[А-Я]{1,3}\b) — выбрасывает все слова, состоящие менее чем из 3-х символов
— [0-9] — убирает все цифры
— [\?\.\-\–\,\!;:\(\)] — знаки препинания
Подробнее с регулярными выражениями можно ознакомиться по ссылке.
Евгений, очень теперь все понятно, спасибо! единствено пожелание — открывать внешнюю ссылку на викпедию из Вашего коммента в новом окне, чтобы не терять сам пост