
- Дария
- 11 минут

- Что такое XPath
- Как парсить данные с помощью Google Spreadsheets
- Синтаксис XPath-запроса для Google Spreadsheets
- Распространённые выражения
- Разметка Open Graph
- Извлечь ссылки, которые содержат слово по шаблону
- Извлечь ссылки на профили в соцсетях
- Спарсить количество проиндексированных страниц в Яндексе
- Спарсить количество контента на странице
- Спарсить код ответа сервера
- Как парсить данные с помощью XPath и Screaming Frog
Занимаясь поисковой оптимизацией сайта, специалисты часто сталкиваются с необходимостью извлечь данные не с одной страницы, а с нескольких за раз. Для этого удобно использовать XPath (XML Path Language) – декларативный язык запросов к элементам XML или XHTML документа. В этой статье я расскажу о базовых элементах и покажу несколько примеров их применения.
Что такое XPath
XPath или XML Path – это язык запросов, который можно использовать для поиска узлов (элементов) в документах XML (Extensible Markup Language).
Языки разметки HTML и XML следуют аналогичным правилам структуры и формата. Поэтому XPath также можно использовать для запросов к HTML-документам.
Проще говоря, для поиска и обработки элементов в HTML-документах мы можем использовать особый синтаксис XPath, чтобы следовать структуре и иерархии страницы.
Терминология XPath и отношение узлов
В XPath есть семь типов узлов: элементы, атрибуты, текст, пространство имён, инструкции по обработке, комментарии и узлы документов.
XML-документы рассматриваются как деревья узлов. Самый верхний элемент дерева называется корневым элементом.
Связи между узлами бывают Parent, Children, Siblings, Ancestors, Descendant – подробнее о связях читайте в справке. Мы можем выделить 2 главные связи:
- Связь Parent (родитель) – у каждого элемента и атрибута есть один родитель. Так, в следующем примере элемент ‹book› является родителем по отношению к элементам ‹title›, ‹author›, ‹year› и ‹price›:

- Связь Children (ребёнок) – узлы элементов могут иметь ноль, одного или нескольких дочерних элементов. Так, элементы ‹title›, ‹author›, ‹year› и ‹price› являются дочерними элементами элемента ‹book›.
Синтаксис
Рассмотрим базовый синтаксис XPath:
| Синтаксис | Что означает |
|---|---|
| nodename | Выбирает все узлы с именем «nodename» |
| / | Выбирает из корневого узла |
| // | Выбирает узлы в документе из текущего узла, которые соответствуют выделению, независимо от того, где они находятся |
| . | Выбирает текущий узел |
| .. | Выбирает родителя текущего узла |
| @ | Выбирает атрибуты |
Существуют два вида указания пути к нужному элементу – абсолютный и относительный.
В абсолютном пути используется полный XPath-запрос от корневого тега HTML до конкретного элемента. Ключевой характеристикой является то, что он начинается с одинарной косой черты (/), обозначающей корневой узел.
Например:
Есть текст «Drappier Rose Brut» в ссылке.
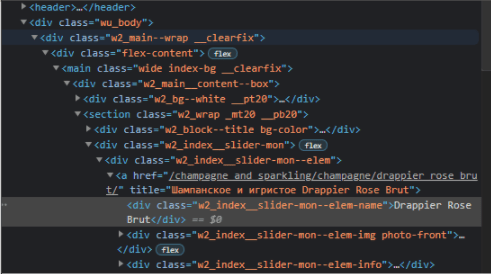
Абсолютный путь будет следующим:
/html[1]/body[1]/div[@class='wu_body']/div[1]/div[1]/main[1]/div[1]/section[1]/div[2]/div[1]/a[1]/div[1]
Относительный XPath начинается с выбранного вами узла, который не обязательно должен быть корневым.
Он начинается с двойной косой черты (//), и преимущество его использования в том, что вам не нужно прописывать абсолютный путь XPath.
Для этого же примера относительный XPath будет следующим:
//div[@class='w2_index__slider-mon--elem-name']
Как видите, выполнять запросы с помощью относительного пути намного проще, а запись намного короче.
Предикаты
Предикаты помогают сделать выборку в наборе узлов на основе некоторого условия. Вот несколько основных:
| Предикат | Что означает |
|---|---|
| //a[1] | Выбирает первый элемент, который является дочерним элементом ‹a› |
| //a[last()] | Выбирает последний элемент из всех элементов ‹a› |
| //a[@class] | Выбирает все элементы ‹a› с атрибутом class |
| //a[@class=’offer’] | Выбирает все элементы ‹a›, у которых есть атрибут class со значением «offer». |
Полный список выражений и предикатов можно посмотреть в справке.
Как парсить данные с помощью Google Spreadsheets
С помощью функции importxml в таблицах Google можно парсить метаданные, заголовки, наименования товаров, цены, почту и многое другое. Рассмотрим самые популярные и полезные функции и их применение.
Синтаксис XPath-запроса для Google Spreadsheets
IMPORTXML(URL,"XPath_выражение")
, где
- URL – это URL-адрес страницы, включая протокол (например, http://). Значение URL должно быть указано в кавычках или быть ссылкой на ячейку, содержащую соответствующий текст.
- XPath_выражение – запрос XPath, выполняемый для структурированных данных.
Распространённые выражения
| XPath | Значение импорта |
|---|---|
| //h1 | Спарсить заголовок страницы (h2-h6 по аналогии) |
| //title | Спарсить Title страницы |
| //meta[@name=’description’]/@content | Спарсить Description страницы |
| //a/@href | Выгрузка всех ссылок с сайта |
| //link[@rel=’canonical’]/@href | Спарсить каноникал страницы |
| //meta[@name=’robots’]/@content | Спарсить значения тега robots на странице |
| //link[@rel=’amphtml’]/@href | URL-адрес AMP |
Разметка Open Graph
Open Graph используется Facebook, LinkedIn и Pinterest, так что это ещё одна причина убедиться в правильной реализации разметки.
| XPath | Значение импорта |
|---|---|
| //meta[@property=’og:title’]/@content | OG Title |
| //meta[@property=’og:description’]/@content | OG Description |
| //meta[@property=’og:type’]/@content | OG Type |
| //meta[@property=’og:url’]/@content | OG URL |
| //meta[@property=’og:image’]/@content | OG Image |
| //meta[@property=’og:site_name’]/@content | OG Site Name |
| //meta[@property=’og:locale’]/@content | OG Locale |
Пример использования – нам нужно узнать значение тега Title для разметки Open Graph.

Спарсить URL из Sitemap
Формула:
=ImportXML(URL;"//url/loc")
Пример использования:

Спарсить внутренние и внешние ссылки страницы
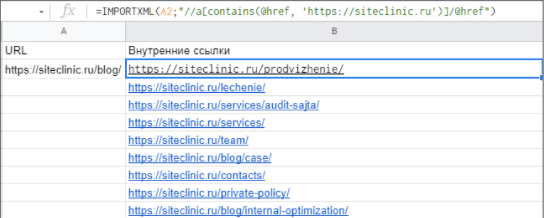
- Формула для парса внутренних ссылок:
=ImportXML(URL;"//a[contains(@href, 'доменное_имя')]/@href")
Пример:
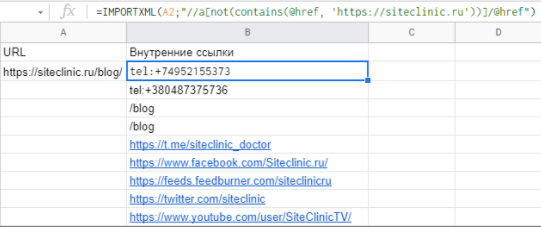
- Формула для парса внешних ссылок:
=ImportXML(URL;"//a[not(contains(@href, 'доменное_имя'))]/@href")
Пример:
Замечание!
В этих примерах на странице реализованы внутренние ссылки с относительным URL, поэтому для точного результата нужно в примере с внешними ссылками отфильтровать значения по протоколу https:// и убрать значения с относительными URL в таблицу с внутренними ссылками.
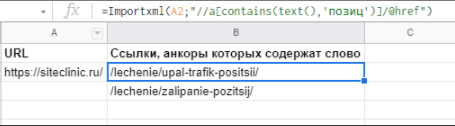
Извлечь ссылки, которые содержат слово по шаблону
Формула:
=Importxml(A2;"//a[contains(text(),'Шаблон текста')]/@href")
Пример:
Извлечь ссылки на профили в соцсетях
Формула:
=IMPORTXML(URL;"//a[contains(@href, 'vk.com/') or contains(@href, 'twitter.com/') or contains(@href, 'facebook.com/') or contains(@href, 'instagram.com/') or contains(@href, 'youtube.com/')]/@href")
Пример:

Спарсить количество проиндексированных страниц в Яндексе
Алгоритм:
Поисковый запрос такого типа [site:siteclinic.ru] показывает количество проиндексированных страниц в выдаче.
Эти данные лежат в теге ‹div› с классом serp-adv__found.
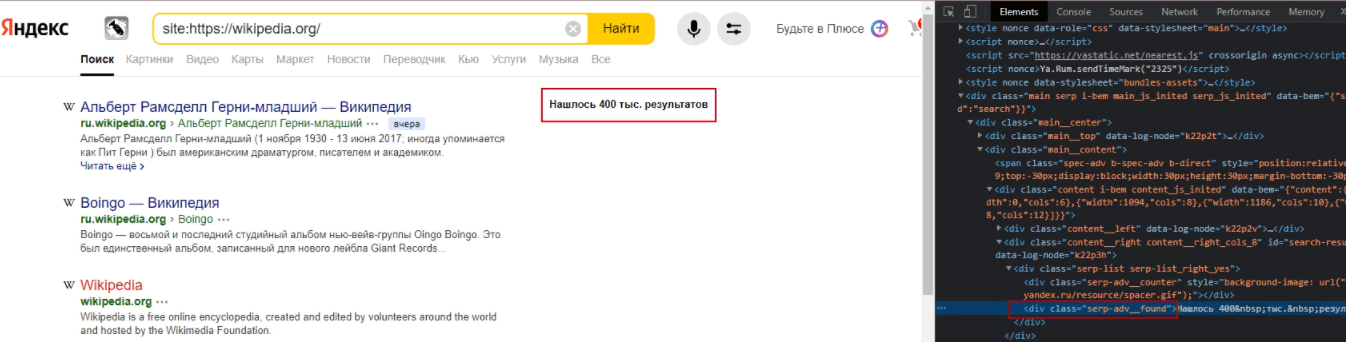
Поэтому для извлечения данных используем формулу:
=SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(importxml(CONCATENATE("https://yandex.ru/search/?text=site%3A";"ссылка на сайт");"//div[@class='serp-adv__found']");"Нашлось ";"");" результатов";"");" результата";"");" ";"");"Нашлась";"");"результат";"");"Нашёлся";"");"тыс.";"000")
Пример:
![]()
Спарсить количество контента на странице
К примеру, нужно узнать соотношение текста на странице блога к количеству кода на странице – таким образом можно узнать, какие статьи желательно доработать, так как там мало контента.
Пример:

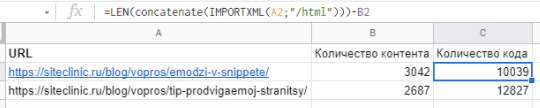
Формула:
=LEN(concatenate(IMPORTXML(A2;"//article/div";"//h1")))
– формула, позволяющая узнать количество текстового контента на странице
=LEN(concatenate(IMPORTXML(A2;"/html")))-B2
– формула, позволяющая узнать количество кода на странице, при этом в ячейке B2 мы находим количество текстового контента на странице
Спарсить код ответа сервера
Формула:
=SUBSTITUTE(importxml(concatenate("https://bertal.ru/index.php?a9132898/";A2);"//div[@id='otv']/b");"HTTP/1.1 ";"")
где A2 – это URL страницы.
Пример:

Чтобы выбрать определённый user-agent, замените первую ссылку на следующую:
https://bertal.ru/index.php?a9133026/ – Google Bot
https://bertal.ru/index.php?a9133032/ – Yandex Bot
Как парсить данные с помощью XPath и Screaming Frog
Screaming Frog SEO Spider – это SEO-краулер, при помощи которого можно парсить свой ресурс, а также ресурсы конкурентов.
После скачивания и установки программы нужно купить лицензию, так как нужная нам опция доступна только для лицензированных пользователей.
Custom Extraction – это пользовательская функция извлечения, которая позволяет вам парсить любые данные из HTML веб-страницы, используя CSSPath, XPath и регулярное выражение. Извлечение выполняется на основе статического HTML, возвращённого из URL-адресов с ответом 200 ОК, просканированных парсером. Также можно переключиться в режим рендеринга JavaScript, чтобы извлечь данные из визуализированного HTML.
После открытия Screaming Frog выполните следующие шаги для начала извлечения данных:
1. Нажмите Configuration > Custom > Extraction.
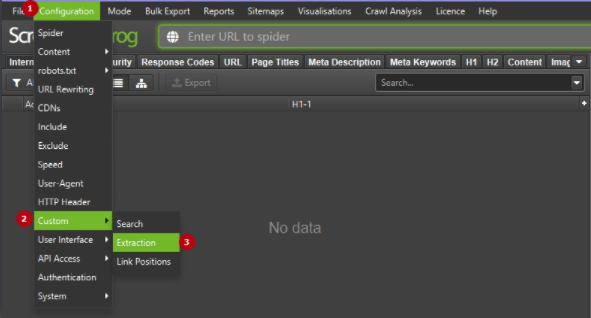
Вы перейдёте в пользовательскую конфигурацию извлечения, которая позволяет вам настроить до 100 отдельных «экстракторов»-правил. Чтобы добавить новые правила, кликните по кнопке Add – появится новое поле для задания правил.
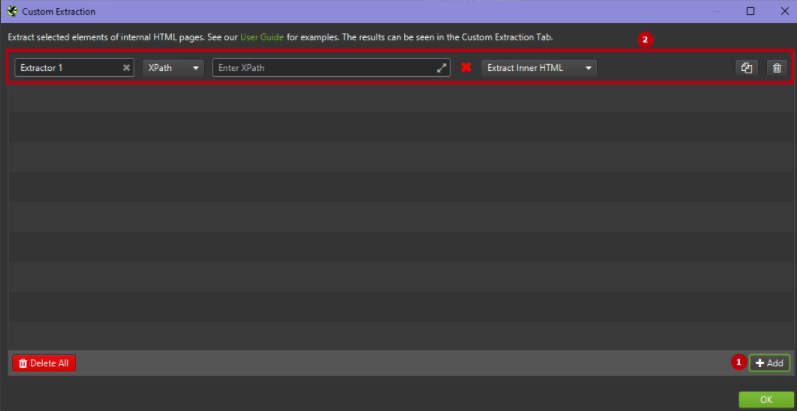
2. Выберите метод извлечения XPath.
Инструмент Screaming Frog SEO Spider предоставляет три метода парсинга данных с веб-сайтов – CSS Path, XPath и Regex. В данной статье мы будем использовать XPath.
При использовании XPath для сбора HTML-данных вы можете точно выбрать, что извлекать, используя раскрывающиеся фильтры:
- Extract HTML Element – извлекает выбранный элемент и всё его внутреннее HTML-содержимое.
- Extract Inner HTML – извлекает внутреннее HTML-содержимое выбранного элемента. Если выбранный элемент содержит другие элементы HTML, они будут включены.
- Extract Text – извлекает текстовое содержимое выбранного элемента и текстовое содержимое любых подэлементов.
- Function Value – извлекает результат предоставленной функции, например, count(//h1), чтобы найти количество тегов h1 на странице.
3. Добавьте выражение XPath.
Далее вам нужно будет ввести своё выражение XPath в соответствующие поля экстрактора. Быстрый и простой способ определить соответствующий путь XPath данных, которые вы хотите спарсить – это просто открыть веб-страницу в браузере Google Chrome и «просмотреть код» элемента HTML, который вы хотите спарсить (ПКМ по нужному элементу > Просмотреть код).
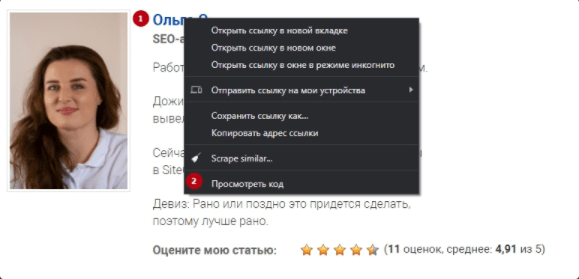
Затем откроется панель разработчика с выделенным элементом, щёлкните правой кнопкой мыши и скопируйте соответствующий путь селектора XPath.
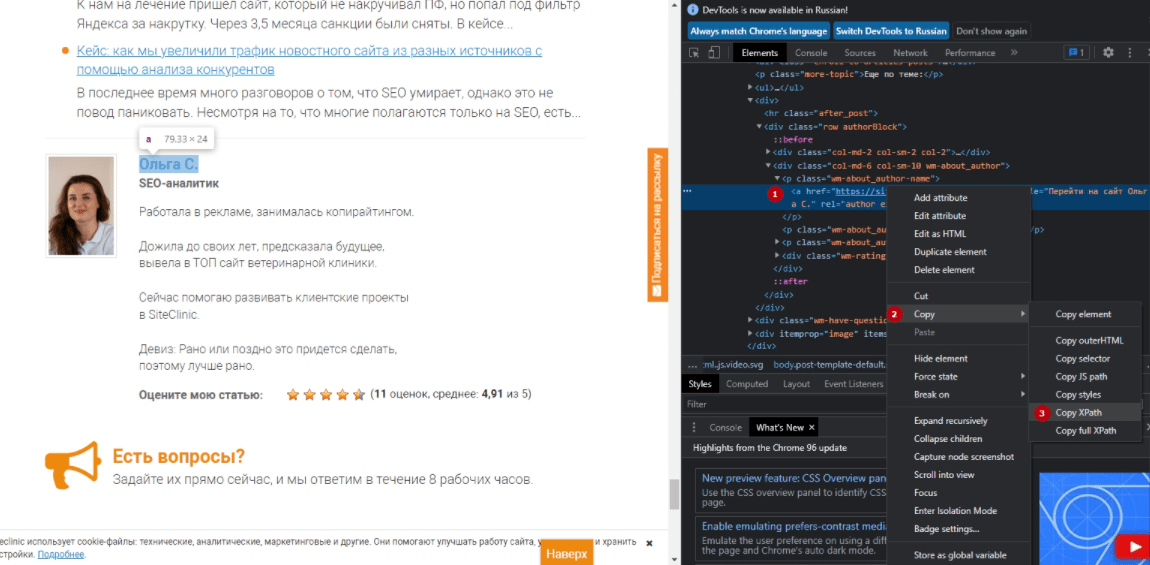
Например, вы можете начать собирать «авторов» статей в блогах и количество оценок статьи, которые они получили. Возьмём в качестве примера сайт https://siteclinic.ru/.
Откройте любой пост в блоге в браузере Google Chrome, щёлкните правой кнопкой мыши и «просмотрите код элемента» по имени автора и количеству оценок, которые находятся в инструментах разработчика. Скопируйте соответствующий путь XPath и вставьте его в соответствующее поле экстрактора в SEO Spider, укажите любое название правила.
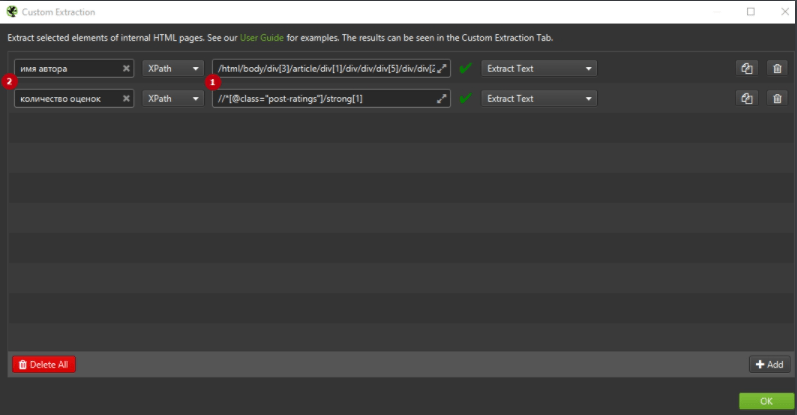
4. Запустите сканирование сайта.
Затем введите адрес веб-сайта в поле URL-адреса вверху и нажмите «Пуск», чтобы просканировать сайт.

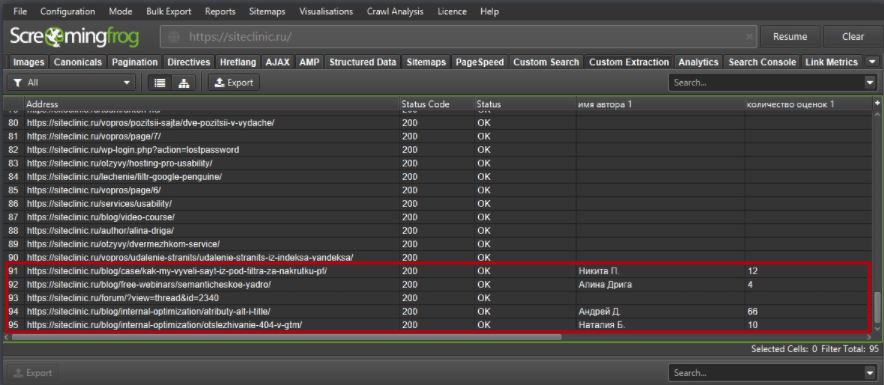
После окончания сканирования перейдите во вкладку Custom Extraction.
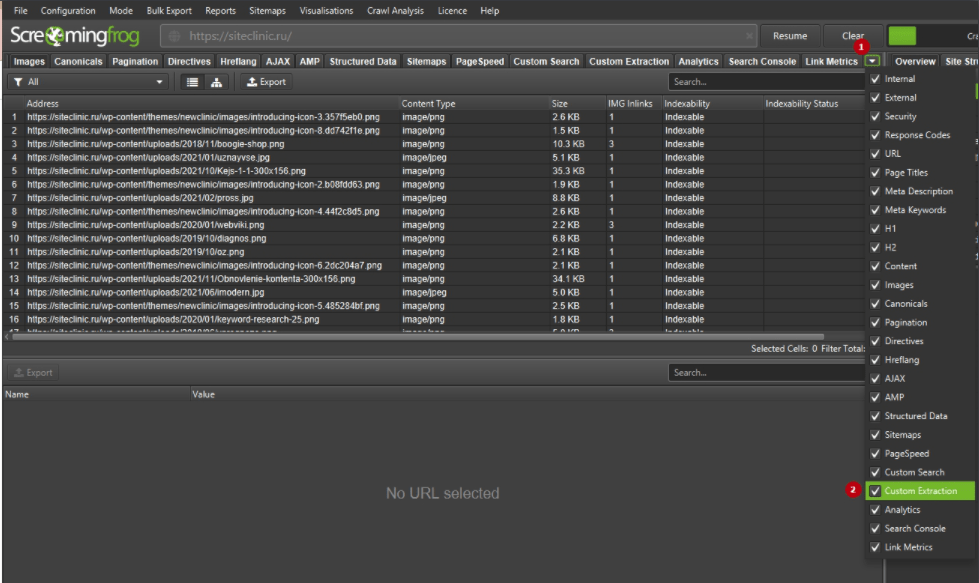
Здесь мы можем видеть, что добавились такие поля, как «имя автора 1» и «количество оценок 1». Это и есть нужные нам поля.
Несколько полезных кастомных функций Screaming Frog
1. Заголовки
По умолчанию Screaming Frog парсит только h1 и h2, но если вы хотите спарсить h3, XPath:
//h3
– спарсить все h3 на странице
/descendant::h3[1]
– спарсить первый заголовок h3 на странице
/descendant::h3[position() >= 0 and position() <= 4]
– спарсить первые 4 h3 на странице
count(//h3)
– спарсить количество заголовков h3 на странице
Примечание. В этом случае поле «Extract Inner HTML» в крайнем правом раскрывающемся списке окна Custom Extraction необходимо изменить на «Function Value», чтобы это выражение работало правильно.
string-length(//h3)
– длина строки h3 на странице
Примечание. В этом случае поле «Extract Inner HTML» в крайнем правом раскрывающемся списке окна Custom Extraction необходимо изменить на «Function Value», чтобы это выражение работало правильно.
2. Hreflang
//*[@hreflang]
– спарсить содержимое всех элементов hreflang
Примечание. В этом случае поле «Extract Inner HTML» в крайнем правом раскрывающемся списке окна Custom Extraction необходимо изменить на «Extract HTML Element», чтобы это выражение работало правильно.
//*[@hreflang]/@hreflang
– спарсить конкретное значение в атрибуте Hreflang
3. Метатеги социальных сетей
Здесь мы парсим различные значения из метатегов социальных сетей, такие как Title, Description, Type и т. д.
//meta[starts-with(@property, 'og:title')]/@content //meta[starts-with(@property, 'og:description')]/@content //meta[starts-with(@property, 'og:type')]/@content //meta[starts-with(@property, 'og:site_name')]/@content //meta[starts-with(@property, 'og:image')]/@content //meta[starts-with(@property, 'og:url')]/@content //meta[starts-with(@property, 'fb:page_id')]/@content //meta[starts-with(@property, 'fb:admins')]/@content //meta[starts-with(@property, 'twitter:title')]/@content //meta[starts-with(@property, 'twitter:description')]/@content //meta[starts-with(@property, 'twitter:account_id')]/@content //meta[starts-with(@property, 'twitter:card')]/@content //meta[starts-with(@property, 'twitter:image:src')]/@content //meta[starts-with(@property, 'twitter:creator')]/@content
4. Почта E-mail
//a[starts-with(@href, 'mailto')]
– парсит все email-адреса на странице
5. Iframes
//iframe/@src
– спарсить содержимое всех тегов iframe на странице
//iframe[contains(@src ,'www.youtube.com/embed/')]
– извлечёт содержимое только тех тегов iframe, в которые встроено видео YouTube
6. Ссылки
//a[contains(.,'SEO')]/@href
– извлечь все ссылки на странице, в анкоре которых написано «SEO»
Примечание. Предыдущее выражение регистрозависимо, поэтому если у вас есть ссылки с анкорами «SEO» и «Seo», тогда используйте следующее выражение:
/a[contains(translate(., 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'),'Seo')]/@href
Выводы
Таким образом, мы показали, как можно спарсить практически любую интересующую информацию с сайта. Эти формулы будут полезны как для короткого постраничного анализа, так и для извлечения нужной информации на больших проектах.
Если вы хотите получить полный список ошибок и более глубокий анализ состояния сайта, обращайтесь к нам ↓
Еще по теме:
- Какие есть сервисы для отслеживания ссылочного профиля, трафика и позиций конкурентов? Какие сервисы посоветуете для отслеживания конкурентов (их ссылочного профиля, например, трафика, позиций)? Если можно и платные и бесплатные. Ответ Сервисов для отслеживания конкурентов достаточно много....
- Доступны ли к индексации страницы, если лягушка показывает, что они закрыты x-robots-tag? Лягушка не сканирует метатеги и показывает, что страницы закрыты x-robots-tag, но в индексе, если проверять страницы через site: поисковики выдают эти страницы - почему так?...
- Обзор сервисов для съёма позиций сайта Критерии оценки https://seolib.ru/ https://topvisor.com/ru/ https://seranking.ru/ https://ahrefs.com/ https://allpositions.ru/ https://ru.megaindex.com/ https://www.rush-analytics.ru/ https://www.semrush.com/ https://serpstat.com/ https://tools.pixelplus.ru/ https://line.pr-cy.ru/ https://serphunt.ru/ https://www.wincher.com/ Результаты Несколько месяцев назад, отвечая на вопрос в Телеграме, я...
- Какие действия после взлома сайта и как проверить наличие скрытого кода? Какие действия предпринимать, после восстановления доступа к сайту (до этого его взломали)? Как можно проверить сайт на наличие появившегося скрытого кода или текста? Ответ После...
- Как долго ждать результата от Disavow Tool? Подскажите, как быстро срабатывает Disavow Tool? Как быстро ждать результата от таких действий, может есть какие-то кейсы? Ответ Время, необходимое для того, чтобы Google учел...

Оцените мою статью:
 (15 оценок, среднее: 5,00 из 5)
(15 оценок, среднее: 5,00 из 5)Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.
