
- (Обновлено: ) Елена Камская

Мы подготовили для вас адаптированный перевод исследования Яндекса о пользовательских факторах, представленного на конференции CIKM 2013 (Бёрлингейм, в ноябре 2013). В докладе идет речь об изучении поведения пользователей после перехода на сайт из поиска и возможном влиянии этих данных на выдачу.
Предлагаем вашему вниманию перевод исследования Яндекса о поведенческих факторах, который был представлен на конференции CIKM 2013 (Бёрлингейм, ноябрь 2013). В докладе, который называется «Through-the-Looking Glass: Utilizing Rich Post-Search Trail Statistics for Web Search», идет речь об изучении поведения пользователей после перехода на сайт из страницы поиска и о том, как эти данные могут влиять на выдачу.
Авторы исследования: Алексей Толстиков (atolstikov@yandex-team.ru), Михаил Шахрай (smikler@yandex-team.ru), Глеб Гусев (gleb57@yandex-team.ru), Павел Сердюков (pavser@yandex-team.ru). Яндекс, 119021, Россия, г.Москва, ул. Л.Толстого 16
АННОТАЦИЯ
С ростом популярности различных тулбаров увеличивается и важность корректного использования данных о поведении пользователей, которые хранятся в их логах.
Информация о поведении посетителей после перехода на сайт из выдачи (пост-кликах) оказалась очень полезной при изучении пользовательских предпочтений и помогла улучшить текущую систему поиска. Однако вопрос, насколько поведенческие характеристики могут влиять на модель ранжирования, до сих пор окончательно не раскрыт.
Мы провели масштабное исследование целого ряда характеристик поисковых маршрутов в реальных условиях и пришли к выводу, что более глубокое изучение пользовательского опыта задолго до клика по результатам поиска может значительно улучшить существующую модель ранжирования.
1. ВВЕДЕНИЕ
С недавнего времени данные о поведении пользователей играют важную роль в персонализации поиска.
Самый известный способ оценки предпочтений и степени удовлетворенности пользователя – это анализ его кликов по результатам поиска. Он дает много неявной информации о предпочтениях пользователей. Но объема и надежности этих данных не всегда достаточно, ведь основная активность проявляется за пределами поисковой выдачи.
С ростом популярности инструментов для браузеров появилась возможность частично компенсировать недостаток информации о пост-кликах за счет данных о просмотренных пользователями страницах, которые хранятся в журналах их тулбаров.
Оказалось, что такой показатель взаимодействия пользователя со страницей, как dwell time (время пребывания юзера на странице по запросу – прим. переводчика), может служить надежным показателем релевантности документа.
Но последовательность передвижений посетителя по сайту с целью найти нужную информацию после того, как он перешел с результатов поиска (post-query search trail), до сих пор не изучена как фактор ранжирования страниц, попавших в его маршрут.
Мы предполагаем, что подробный анализ поисковых маршрутов поможет еще больше усовершенствовать поисковую модель, в которой используются всем уже известный dwell time.
В данной статье описывается масштабное исследование различных характеристик поисковых маршрутов, которое является продолжением предыдущих изысканий пользовательских факторов и их влияния на качество поиска.
Опираясь на результаты других исследований (Р.У. Уайта и С.М. Друкера), мы представляем поисковой маршрут в виде древовидной структуры, где в роли корней выступают клики на ссылки в результатах поиска, а ветвями являются переходы по гиперссылкам внутри поисковой цепочки. Авторы исследования присвоили древовидному маршруту такие характеристики: количество перекрестных точек, глубина, ширина, средняя длина ветви.
Кроме перечисленных качеств мы изучили и оценили еще несколько новых, включая количество шагов поискового маршрута и время нахождения пользователя в бездействии на каждой странице. Некоторые из этих факторов упоминались ранее в других теоретических работах. Но, насколько нам известно, возможность их влияния на поиск как поведенческих факторов еще не оценивалась.
Объединив результаты переходов на один документ или на домен в целом, можно значительно улучшить текущую поисковую модель за счет внедрения посткликовых факторов. Результаты исследования подтверждают упомянутое выше предположение, что детальное изучение поискового маршрута, а не только лишь использование данных о времени пребывания пользователя на той или иной странице, позволяет улучшить релевантность поиска.
Подводя итог, хотелось бы сказать, что ценность данной работы в том, что:
- мы провели масштабное исследование по изучению свойств целого ряда поисковых маршрутов и использованию данной информации для улучшения веб-поиска;
- мы выявили, что детальное изучение характеристик поискового маршрута может предоставить некоторые дополнительные данные, важные для информационно-поисковых задач.
2. РАБОТЫ ПО СХОЖЕЙ ТЕМАТИКЕ
С точки зрения поисковой системы, оптимальный способ использования данных о ПФ пользователей с существующей системой ранжирования – это создание новых показателей, которые будут отражать различные свойства взаимодействия пользователя с веб-сайтами.
Одной из первых работ, изучающей качественное влияние использования данных ПФ для улучшения ранжирования и релевантности выдачи поиска, является исследование Е. Агичтайн, E. Брилл и С.Дюме «Улучшение качества веб-поиска посредством учета пользовательского поведения», где характеристики ПФ берутся из логов тулбара.
Наряду с другими характеристиками пользовательского поведения авторы изучили основные статистические данные взаимодействия пользователя с веб-страницами, например, различную продолжительность времени пребывания посетителя на документе по запросу (dwell time).
Хотелось бы также отметить, что косвенным доказательством пользовательской активности в браузере может послужить анализ прокрутки страницы и перемещения курсора [4].
В своем исследовании мы также решили выйти за рамки показателя dwell time как основного доказательства активности пользователя, более того, мы шагнули намного дальше первой страницы в поисковом маршруте.
Другим способом использования данных о поведении пользователей является освоение формулировок начальных поисковых запросов, с которых начинается поисковый маршрут пользователя, ведущий к анализируемому документу [2].
Комплексный анализ всего поискового маршрута дает больше пользы, чем сравнение первой и последней страницы маршрута по различным критериям, таким, как релевантность, тематический охват, разнообразие тем, новизна и полезность [8].
В своем исследовании мы представляем поисковые маршруты как древовидную структуру, как это было ранее сделано в работе Р.У.Уайта и С.М. Друкера [7], также мы воспользовались некоторыми основными графами свойств из этой работы.
Бинарность кликов, которая указывает на наличие пост-кликового маршрута, использована для отладки классификатора по выявлению «шумовых» кликов.
3. ДАННЫЕ
Все эксперименты в рамках доклада основаны на данных о поведении пользователей, которые анонимно хранятся в логах тулбара поисковой системы, установленного в браузерах миллионов пользователей.
Каждая запись в таком журнале содержит в себе (анонимно) идентификатор пользователя, временную метку и такие детали активности в браузере, как: поисковой запрос пользователя, URL посещенной страницы, закрытие окна браузера.
Для своего исследования мы взяли данные логов за 3 месяца (11 декабря 2012 — 10 марта 2013). Данные включают 3 млрд запросов, 5,3 млрд поисковых маршрутов, 16 млрд переходов по страницам и охватывают 2,7 млрд различных документов.
Из полученных данных мы извлекли поисковые маршруты, которые начинаются с запроса пользователя и состоят из последовательности его визитов по страницам с целью удовлетворить свою информационную потребность.
Для того чтобы уменьшить влияние «зашумленности» и не учитывать страницы, не связанные с первоначальным поисковым запросом, мы считаем поисковой маршрут законченным в следующих случаях:
- пользователь ввел новый запрос;
- пользователь перешел на главную страницу, ввел URL в адресную строку браузера или загрузил другую страницу через закладку браузера;
- нет браузерной активности более 30 минут (таймаут активности);
- пользователь закрыл окно браузера.
Весь этот список также используется для определения поискового маршрута в работе Р.У. Уайта и С.М. Друкера [7], за исключением одного правила — «проверить электронную почту или залогиниться в сервисе». Мы считаем, что данные действия могут быть логичным продолжением поискового маршрута, т.к. пользователь в рамках своего запроса может переходить по гиперссылкам веб-сайтов, требующих аутентификации.
4. ХАРАКТЕРИСТИКА ПОИСКОВОГО МАРШРУТА
В этом разделе мы кратко опишем способ построения поискового маршрута, как это представлено в вышеупомянутой работе [7].
Как уже упоминалось, мы представляем каждый поисковой маршрут в виде древовидной структуры. Узлами дерева являются уникальные страницы, а ветвями – прямые переходы пользователей по гиперссылкам между ними.
Таким образом, движение пользователя по гиперссылкам отражает передвижение по ветви дерева. Если пользователь повторно заходит на страницу, которую он уже посещал в рамках маршрута, этот шаг расценивается как возврат к соответствующему узлу дерева. В свою очередь новые страницы, на которые переходит пользователь по гиперссылкам, представляют собой новую ветку дерева.
Если пользователь возвращается к странице результатов поисковой выдачи и нажимает на новый документ, мы начинаем создавать новое дерево. См. пример древовидной структуры на рисунке №1. В следующих разделах мы опишем свойства, присущие поисковому маршруту, которые можно использовать в качестве факторов ранжирования.
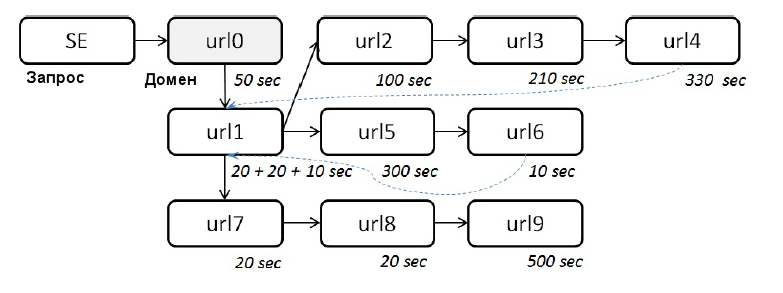
Рисунок № 1: Поисковой маршрут представлен в виде древовидной структуры.
Узлов = 10, глубина = 4, ширина = 3, длина ветви = 3, кол-во шагов = 12, кол-во возвратов = 2, время = 1590, кол-во удовлетворенных шагов = 6, кол-во длинных шагов = 3.
4.1 ОСОБЕННОСТИ ГРАФОВ
Количество узлов (Nodes Count). Это число уникальных страниц, посещенных пользователем в рамках поискового маршрута после перехода на сайт из страницы выдачи.
Большое количество узлов может говорить о том, что пользователь не находит ответ на свой запрос на первой (посадочной) странице маршрута и вынужден искать его дальше, переходя по внутренним гиперссылкам.
Но с другой стороны, большое количество узлов характерно для маршрутов по информационным запросам, которые не могут быть полностью раскрыты на одной веб-странице.
Глубина (Depth). Это расстояние между корнем дерева (поисковым запросом) и наиболее удаленным узлом. Расстояние меряется количеством отрезков (кликов) между промежуточными узлами по наиболее короткой траектории.
Глубокая структура дерева более характерна для сайтов, внутренние переходы по которым осуществляются за счет последовательных кликов по ссылкам типа «вперед», «назад».
Например, если информация разбита на несколько страниц, имеющих строгую последовательность.
Ширина дерева (Breadth). Шириной дерева поискового маршрута является общее количество его листьев (Leaves).
Листья – это целевые страницы, после переходов на которые пользователи не идут дальше по гиперссылкам. Ширина маршрута совпадает с числом ветвей, что подробно рассматривается в работе [7].
Большой показатель ширины маршрута может означать, что у запроса пользователя много значений, поэтому он ищет информацию в исследовательской манере. Но также он может указывать на то, что у сайта проблемы с удобством.
Средняя длина ветви (Average branch length). Мы разбили поисковой маршрут на отрезки, каждый из которых начинается с повторного визита ранее посещенной страницы и представляет собой цепочку последовательных переходов вперед по гиперссылке.
Длина каждой цепочки определяется количеством отрезков, из которых она состоит, — это и есть ветвь.
Мы не берем во внимание цепочки длиной в один отрезок, так как они не создают новые ветви. Выходит, что средняя длина ветви – это усредненная длина цепочек, из которых состоят разные ветви дерева. Стоит отметить, что это значение можно также рассчитать по формуле: ((кол-во узлов -1) / ширина) +1.
4.2 ОСОБЕННОСТИ ПЕРЕМЕЩЕНИЙ
Кроме рассмотренных выше количественных характеристик поискового маршрута, есть еще и ряд качественных показателей передвижения пользователя по сайту.
Число шагов в маршруте (Number of steps). Это общее число переходов, совершенных пользователем в пределах поискового маршрута.
Данный показатель схож с количеством узлов, но отличается тем, что здесь мы учитываем повторные посещения страниц.
Количество возвратов (Revisits). Это число повторных посещений страниц, произведенных пользователем в пределах поискового маршрута. На основании этого показателя можно оценивать сложность маршрута. Например, большой показатель возвратов сигнализирует о том, что пользователь часто возвращался на одну и ту же страницу, чтобы кликнуть по другой внутренней ссылке либо потому, что с первого раза у него не получилось изучить/понять предоставленную там информацию.
Диверсификация (Diversity, отклонение). Это количество различных доменов второго уровня, представленных на страницах маршрута.
Количество удовлетворенных шагов (Satis_ed steps) и длинных шагов (long steps). Это число кликов, выполненных после задержки на странице на 30 и 300 секунд соответственно.
Таким образом, мы определяем удовлетворенные шаги маршрута аналогично тому, как обычно определяются удовлетворенные клики (см.[6]). Удовлетворенные шаги указывают на страницы, которые более других достойны внимания пользователей.
На рисунке № 1 (см. выше) показан пример поискового маршрута, под рисунком указаны значения перечисленных характеристик.
4.3 ОБЪЕДИНЕНИЕ ХАРАКТЕРИСТИК
После того как по каждому отдельному маршруту были собраны все характеристики, мы объединили их следующим образом: на уровне первого документа поискового маршрута (уровень страницы) и на уровне домена, к которому относится документ (уровень домена).
В результате мы получили образцы поисковых маршрутов, связанных либо с документом, либо с доменом.
Для каждого описанного выше показателя маршрута мы вычислили его среднее значение (AV), стандартное отклонение (STD), 10-й и 90-й персентиль (т.е. нижний и верхний дециль соответственно), минимальное и максимальное значения (MIN, MAX) и использовали их в качестве факторов ранжирования. В следующем разделе мы расскажем о результатах исследования того, как описанные характеристики зависят от тематики домена веб-страницы.
5. ЗАВИСИМОСТЬ ФАКТОРОВ ОТ ТЕМАТИКИ ДОМЕНА
В этом разделе мы покажем, как зависят характеристики поискового маршрута от различных тематик посадочных веб-страниц (т.е. первых страниц маршрута).
Мы взяли собственную базу доменов с вручную определенными тематиками и на ее основе разработали и обучили наивный байесовский классификатор. Этот классификатор анализирует все домены второго уровня, которые попали в нашу выборку поисковых маршрутов, и присваивает каждому определенную тематику.
Мы взяли типовые характеристики на уровне домена (см. блок 4.3), и рассчитали для каждой из них средние значения в рамках определенной тематики. Таким образом, для каждой тематики мы получили свой средний показатель всех ранее рассматриваемых характеристик.
Мы отсортировали все темы по среднему значению каждой характеристики и отобразили результаты в таблице № 1.
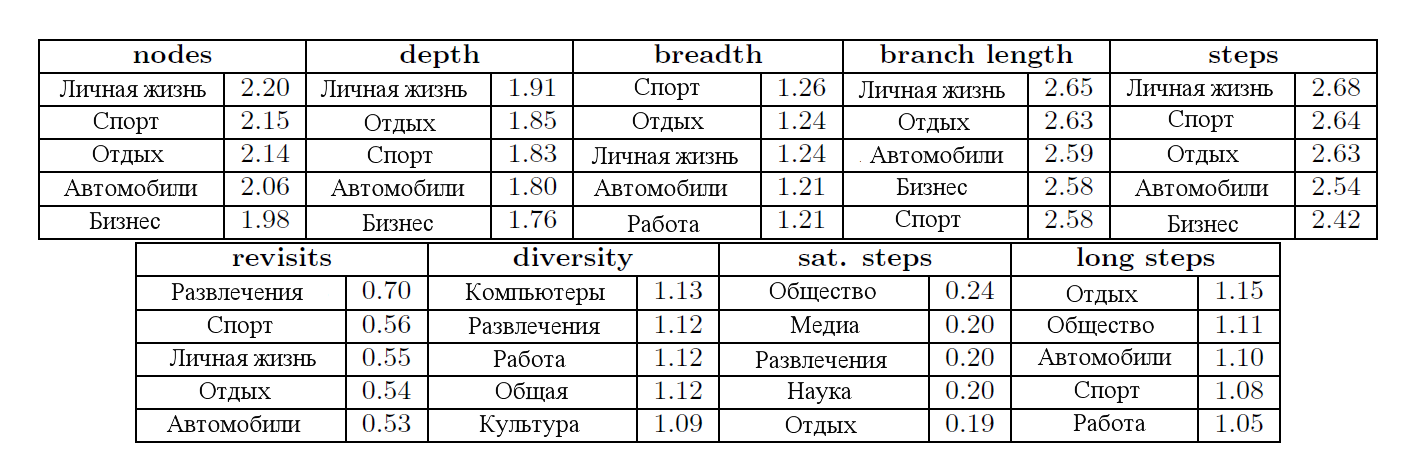
Таблица №1: тематики с наибольшим средним значением каждого основного свойства маршрута, сгруппированные по доменам.
Как видно по таблице, некоторые тематики естественным образом расположены внизу топа по многим показателям поискового маршрута.
Например, пользователь, который просматривает сайт по продаже автомобилей, не может заранее наверняка знать, какая конкретная машина ему подойдет. Чтобы изучить все варианты, он просматривает множество страниц с различными комплектациями и характеристиками. Подобное наблюдается и по таким показателям, как глубина, ширина и количество шагов.
Наибольший показатель удовлетворенных шагов присущ таким тематикам, как «Общество», «СМИ» и «Наука». Контент на большинстве сайтов таких тематик построен так, что пользователю приходится углубляться внутрь сайта (например, анонс статьи и ссылка «подробнее» — прим. переводчика).
Мы также выявили и другие примечательные закономерности для тематик, находящихся на нижних позициях.
К тематикам, имеющим скромный показатель удовлетворенных шагов, относятся «Частная жизнь» и «Авто», в то время как именно эти темы имеют высокий показатель общего количества шагов.
Это означает, что несмотря на большое количество посещений, пользователь, как правило, недолго задерживается на страницах сайтов данных тематик.
Согласно результатам нашего исследования, характеристики поискового маршрута несут некую информацию о тематике сайта, и это может быть использовано поисковой системой. В следующем разделе мы расскажем о том, как оценка поискового маршрута может использоваться для ранжирования.
6. ОЦЕНКА
При оценке показателей маршрута мы опирались на широкую выборку случайных поисковых запросов в популярной поисковой системе.
По каждому запросу были взяты топовые страницы из результатов выдачи лидирующего в мире поисковика.
Релевантность каждого документа оценили профессиональные специалисты по шкале: «превосходно», «отлично», «хорошо», «неплохо» и «плохо».
В общей сложности было обработано 50K запросов и поставлена оценка по 1,5 млн пар запрос-документ.
Присваивая оценки, мы использовали градиентное древо решений Фридмана (Friedman’s gradient boosting decision trees, метод машинного обучения) как модель ранжирования.
Мы сравнили полезность предложенных выше показателей с базовым набором характеристик: алгоритм BM25, PageRank, показатель CTR страниц и домена в целом, а также 7 модификаций показателя dwell time [см.1,табл.4.1]: Time-OnPage¹ — TimeOnDomain² and AverageDwellTime³ — DomainDeviation4.
Где:
1 – общее время пребывания на странице.
2 – общее время пребывания на сайте.
3 – среднее время пребывания посетителя на документе по разным поисковым запросам.
4 – отклонение от среднего времени пребывания на домене.
Данные базовые характеристики достаточно информативны, легко интерпретируются и включают в себя широкий спектр известных на настоящий момент особенностей, основанных на показателях времени пребывания пользователя на документе по запросу (dwell time).
Мы разделили всю базу запросов на две равные части, первую использовали для обучения, а вторую – для оценки.
В таблице № 2 показана производительность трех моделей обучения: (1) базовый набор характеристик; (2) базовый набор характеристик + характеристики маршрута на уровне домена и (3) базовый набор характеристик + характеристики маршрута на уровне URL.
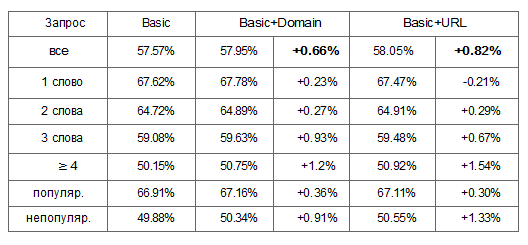
Таблица № 2: Показатели NDCG@10, полученные на основе стандартных характеристик, а также с добавлением к ним характеристик поискового маршрута, объединенных на уровне URL и домена. Формируют 45.18% набора данных, коэффициент запросов ≥ 10 в неделю считать популярным. Различия, выделенные жирным шрифтом, – это статистически значимые на уровне достоверности в 0.99%.
Как видно из таблицы, использование характеристик поискового маршрута как на уровне домена, так и на уровне страницы способствует повышению эффективности.
Модель, обученная на основе базового набора характеристик без учета 7 модификаций dwell time, обладает показателем N DCG @ 5 = 55,9%. Следовательно, показатели маршрута на уровне страницы повышают качество результата на 0,82% вдобавок к 2,9%, полученным за счет dwell time.
Мы также измерили производительность трех моделей отдельно по разным классам запросов. Было обнаружено, что характеристики поискового маршрута еще больше влияют на низкочастотные и узкоспециализированные запросы.
Это можно объяснить следующим образом: показатели маршрутов, объединённые по домену и страницам, проецируют пользовательские предпочтения на более сложные и редкие ситуации, где поведение пользователей мало изучено.
Для того чтобы подтвердить эту догадку, мы разделили все изучаемые запросы на четыре почти равные части
в зависимости от наличия данных о поисковых маршрутах (начиная с маршрутов, состоящих из минимум 2-х шагов от поискового запроса).
Полученные результаты представлены в таблице № 3. В ней видно, что факторы поискового маршрута имеют значительное влияние на сложные запросы.
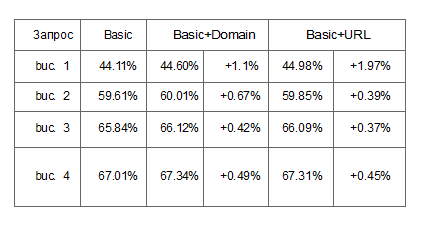
Таблица № 3: Показатель NDCG@10, полученный при четырех различных уровнях доступности данных, где buc. 1 считать наименее доступным, а buc. 4 — максимально доступным.
В таблице № 4 показан топ-10 характеристик, отсортированных в зависимости от их влияния (измеряется уровнем улучшения функции потерь на протяжении всего процесса обучения). Показатели поискового маршрута выделены курсивом.
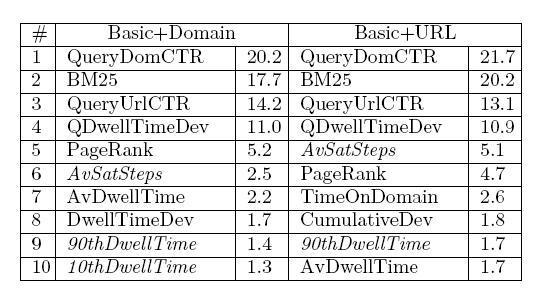
Таблица № 4: Топ-10 характеристик согласно их влиянию.
7. ВЫВОД
Мы провели масштабное исследование пост-кликовых маршрутов и выяснили, как полученные данные можно использовать для улучшения качества поиска. Был рассмотрен широкий набор характеристик поискового маршрута как потенциального источника информации о предпочтениях пользователя, которые проявляются далеко за пределами страницы результатов выдачи.
Подробный анализ показал, что учет особенностей поискового маршрута может существенно улучшить существующий алгоритм поиска. Насколько нам известно, большинство качеств поискового маршрута никогда ранее не оценивались по IR-метрикам. Мы считаем, что исследования новых качеств поисковых маршрутов и различных способов их интерпретации усовершенствует поисковую модель еще больше, чем уже известные поведенческие факторы.
8. СПИСОК ЛИТЕРАТУРЫ
[1] E. Agichtein, E. Brill, and S. Dumais. Improving web search ranking by incorporating user behavior information. In SIGIR, pages 19–26, 2006.
[2] M. Bilenko and R. W. White. Mining the search trails of surfing crowds: identifying relevant websites from user activity. In WWW, pages 51–60, 2008.
[3] Q. Guo and E. Agichtein. Smoothing clickthrough data for web search ranking. In SIGIR, pages 355–362, 2009.
[4] Q. Guo and E. Agichtein. Beyond dwell time: estimating document relevance from cursor movements and other post-click searcher behavior. In WWW, pages 569–578, 2012.
[5] A. Singla, R. White, and J. Huang. Studying trailfinding algorithms for enhanced web search. In SIGIR, pages 443–450, 2010.
[6] K. Wang, T. Walker, and Z. Zheng. Pskip: estimating relevance ranking quality from web search clickthrough data. In KDD, pages 1355–1364, 2009.
[7] R. W. White and S. M. Drucker. Investigating behavioral variability in web search. In WWW, pages 21–30, 2007.
[8] R. W. White and J. Huang. Assessing the scenic route: measuring the value of search trails in web logs. In SIGIR, pages 587–594, 2010.
Авторский перевод статьи — Елена Камская.
Еще по теме:
- Инструкция по работе с новым Яндекс.Вебмастером. Обзор инструментов Подробная инструкция и советы по использованию нового Яндекс.Вебмастера – как добавить свой сайт и использовать инструменты для анализа сайта. Давайте рассмотрим, что полезного дает нам...
- Асессорская инструкция Google: оценка качества поиска (Часть 2) Вторая часть адаптированного перевода инструкции для асессоров Google - как поисковая система оценивает качество поиска. Из статьи вы узнаете об основных видах запросов и том,...
- Смотреть позиции и трафик конкурентов теперь можно с премиум тарифом Яндекс Метрики. Друзья, это первоапрельская шутка! Все данные выдуманы, а все совпадения - случайны 28 марта Яндекс выпустил довольно важное обновление Я.Метрики, значительно расширив функционал сервиса в...
- ТОП тематик, которые выросли и просели из-за коронавируса В статье рассмотрим ТОП тематик интернет-ресурсов, которые просели и выросли в связи с коронавирусом (COVID-19), основываясь на собственных наблюденях и результатах глобального исследования компании SimilarWeb....
- Резкое падение позиций – изменение алгоритмов или ошибки оптимизации? Резко упали позиции. В чем причина – в изменениях алгоритма или у вашего сайта действительно есть проблемы? Рассказываем, как можно узнать причину резких скачков позиций. ...


Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.

Круто. Яндекс молодцы
Не плохо. Вот только поиск ухудшается, а не улучшается. Яндекс учитывает время, проведенное на страницах. В топ-10 выводятся сайты каталоги, в которых собран весь мусор со всего интернета, цель которых является собрать все поисковые запросы и набрать огромную посещаемость для того, чтобы размещать рекламу на своем сайте. Пользователи попадая на такой сайт, начинают на нем долго выискивыть нужную им информацию, но, ничего не находя, покидают его, оставив очень хорошие поведенческие факторы, которые яндекс воспринимает как качественные. На самом деле пользователь не получил ответа на свой запрос и потратил кучу времени впустую, лазия по такому ресурсу.
Полностью согласен с предыдущим высказыванием. на качестве поиска все эти нововведения сказываются не самым лучшим образом.
Идиотизм эти поведенческие факторы их просто будут накручивать программками с разных ip заходитьь на сайт. Появяться конечно сервисы платные по накрутке поведенчесуих факторов. Яндекс думают что таким способом больше бабла срубят на яндекс директ так как ссылки отменят.
> На самом деле пользователь не получил ответа на свой запрос и потратил кучу времени впустую, лазия по такому ресурсу. Ну и что. Вы просто верите в декларации, не задумываясь о том, что важнее создателям не-поиска. Можно предположить такую их логику: "Шума много у всех. И в голове пользователя тоже. Важен тот маленикий процент, который кликает по контексту". Или в плане поддержания лояльности бренду: "Ну и что, что прихожане не находят того, чего искали, может этого и найти-то нельзя. Главное то, что они потратили время/внимание на нас". И обратите внимание на конкретные цифры улучшения, типа 0.82%, 1.9% — это считается достижением. А насколько увеличилась громоздкость всего, учитываемого при ранжировании?
Спасибо за интересный материал, который разложил все по полочкам. Есть над чем подумать, в предверии возможной отмены влияния ссылочного на позиции.
По моему тогда же Яндекс рассказал и о принципах расчета поведенческих факторов в своей писковой системе? Правда я только по данным devvver о них знаю.
Вся эта бередятина от Яндекса на самом деле никому не нужна и пользы для пользователей интернета от их исследований абсолютно никакой нет и не будет. На сегодняшний день от деятельности этой группы фанатов-яндексоидов, возомнившими себя повелителями интерента, наблюдается только вред. Своей алчностью и гонкой за прибылью они душат большое количество вполне нормальных сайтов, выдавая в ТОП откровенные ГС, на которых присутствует их ср…й яндекс-директ. Они просто охамели, оборзели, а мы (пользователи инета) становимся заложниками этих фанатиков. Очень жаль.
Будем работать с тем, что есть. Выбирать особо не приходится… Клиент-то хочет топа в Яндексе
Яндекс идет планомерным путем и данные нововведения без сомнения положительно скажутся на качественном результате выдачи, я про это писал еще до отмены ссылочного ранджирования, все к этому и шло, и это правильно!
Я вот думаю, что не стоит недооценивать маленький процент улучшений от поведенческих факторов, который заявлен в статье. Мол, 0.88% — это мало. Например, Волож совсем недавно говорил, что эра значительных скачков в качестве выдаче уже давно прошла. И улучшение выдачи на всего на 0,5-1% — это успех. Тем более, как для одного из многих факторов. Даже если всего факторов ранжирования всего 200, то усредненно на каждый припадает по 0,5% (грубо, для наглядности). И еще момент, в последней табличке, по влиянию на релевантность документ параметр "количество удовлетворительных шагов" обошол PR. Вот вам и замещение попытка снижения значимости ссылок. А если посмотреть на перводе "дерево маршрута" и вместо ячейки "поисковый запрос" поставить "переход по ссылке" (с вашей купленной статьи) то и получается все тот же маршрут…Проще говоря, замена PR передаваемого ссылкой на ПФ передаваемого ссылок, вполне реально и обоснована.
Dwell time — здесь on page или on site?
1. Почему в исследуемом случае глубина равна 4, а не пяти, если определение явно говорит о количестве отрезков между промежуточными узлами от корня дерева до последнего узла?
SE-URL0 0+1=1
URL0-URL1 1+1=2
URL1-URL7 2+1=3
URL7-URL8 3+1=4
URL8-URL9 4+1=5
Пять, а не 4. Я так понимаю почему то решили исключить самый первый узел, но почему, если определение говорит о как раз его учете?
2. Почему средняя длина ветви равна 3? Если мы посчитаем по альтернативной формуле на основании ранее полученных данных:
((кол-во узлов -1) / ширина) +1.
То у нас получится ((10-1)/3)+1=9/3+1=3+1=4. Средняя длина ветви по альтернативной формуле равняется не 3, а 4.
И вообще можно поподробнее как рассчитывается средняя длина ветви?
Из определения неясно например нужно ли считать:
а) первую ветвь, т.к. она не начинается с просмотра УЖЕ ПОСЕЩЕННОЙ страницы
б) включается ли в количество элементов ветви элементы, после которых произошел возврат на ранее посещенную страницу или в момент совершения возврата длина ветви кончается?
И даже при ответе на эти вопросы несовсем ясно как это считать.
Далее будут еще комментарии:)
Павел, спасибо за комментарий.
Данные вопросы лучше задать авторам исследования.
Здравствуйте!
Спасибо за перевод! Подскажите, пожалуйста, а вот следующие строки, которые есть в тексте, это часть перевода или авторское дополнение?
Где:
1 – общее время пребывания на странице.
2 – общее время пребывания на сайте.
3 – среднее время пребывания посетителя на документе по разным поисковым запросам.
4 – отклонение от среднего времени пребывания на домене.
Подробнее:https://siteclinic.ru/blog/veb-analitika/analiz-povedeniya-polzovatelya-yandex/
Никита, приносим извинения за задержку с ответом. Это часть перевода.