
- (Обновлено: ) Алина Дрига

Видеозапись и текстовая версия вебинара о том, как провести технический аудит сайта. Актуален для тех, кто хочет научиться делать такой аудит самостоятельно или освежить в памяти знания. Спикер – Евгений Аралов.
Наш SEO-аналитик Евгений Аралов провел бесплатный вебинар для тех, кто хочет удостовериться в корректной работе своего сайта или найти проблемные места и устранить их. Мы подготовили видео, презентацию и текстовую версию его вебинара:
Видеозапись вебинара (18.11.2015)
Презентация «Как провести технический аудит сайта»
Заказать аудит сайта с инструкциями по продвижению.
Текстовое содержание вебинара
Сегодня поговорим о технических ошибках.
Во-первых, технические ошибки могут негативно влиять на индексацию и ранжирование сайта.
Во-вторых, если у вас резко просел трафик со всех поисковых систем, вам также следует обратить внимание на возможные технические ошибки. Скорее всего, причина в них.
Строим нашу презентацию таким образом:
— Плохая индексация и ранжирование
- Поиск дублей и мусорных страниц
- Время и скорость загрузки сайта
- Проверка индексации важных областей страницы
— Трафик резко упал
- Проблемы с доступностью сайта
- Настройка редиректа
- Вирусы
ПЛОХАЯ ИНДЕКСАЦИЯ И РАНЖИРОВАНИЕ
1. Поиск дублей и мусорных страниц.
Почему дубли негативно влияют на ранжирование и индексацию сайта:
— Тратят краулинговый бюджет
Краулинговый бюджет – это количество страниц, которое за раз может проиндексировать робот поисковой системы. У каждого сайта свой краулинговый бюджет, влияет на него большое кол-во факторов от популярности сайта, скорости загрузки до кол-ва новых появившихся страниц.
Т.е. робот зашел на сайт, за раз он может проиндексировать, например, 10 страничек. И вместо того, чтобы индексировать нормальные страницы, он индексирует дубли. То же самое и с мусорными страницами, которые к основному контенту никакого отношения не имеют.
— Влияют на релевантность
Если у нас есть 2 одинаковые страницы, их релевантность может меняться. Т.е. по одному запросу может выходить то одна страница, то страница-дубль – мы прокачиваем одну страницу, а выходит совершенно другая. Мы не можем контролировать этот процесс, и это очень мешает продвижению сайта.
— Размывается статический вес сайта
Т.е мы строим какую-то перелинковку, у нас есть определенная структура, и лишний вес уходит на эти дубли. Чем больше дублей, тем меньше страница передает вес.
— Могут значительно снижать трафик
В Google дубли часто могут стать причиной резкого снижения трафика. Были случаи, когда трафик урезало с 15 тыс. до 1 тыс. После устранения дублей трафик восстанавливался.
Распространенные дубли:
Основные – это страницы:
- с www и без www
- с index.html и без
- страница доступна со слешем и без: site.ru/ и site.ru
Решается проблема легко – просто ставим 301 редирект. Это стоит делать в самом начале, при запуске сайта, тогда никаких проблем не будет.
Пример с www на без www:
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www\.(.*) [NC]
RewriteRule ^(.*)$ https://%1/$1 [R=301,L]
Важный момент для Яндекса: При настройке главного зеркала (когда мы выбираем, показывать поисковику домен с www или без www, обязательно указывайте в robots.txt Host – Host:site.ru (указали главное зеркало без www).
Для Google просто настраиваем 301 редирект.
Другие виды дублей:
1. Дубли страниц с GET-параметрами
Пример: site.ru/page1/?prm=fetxie
Обычно в интернет-магазинах такие дубли получаются в результате различных сортировок (по рейтингу, популярности т .д.) и фильтров. Такие страницы часто попадают в индекс.
Вопрос: Т.е. фильтры в интернет-магазине – это дубли? Если они попадают в индекс и такая информация не имеет спрос, то да. Допустим, мы фильтруем по цене – такой фильтр, скорее всего, будет дублем, фильтры по бренду – уже нет, но тогда нужно формировать отдельную страницу с нормальным ЧПУ-урлом. С фильтрами был такой пример – на сайте по аренде яхт были фильтры, получалось так, что большая часть одних и тех же лодок по фильтрам пересекалась, т.е. по факту формировались дубли. У каждого появлялся свой параметр, он попадал в индекс, плодились одинаковые страницы.
Как избавиться: добавляем GET-параметры в robots.txt: Disallow:?prm или реализуем сортировки (фильтры) через ajax – тогда не будут добавляться дополнительные параметры в URL.
2. Дубли карточек товаров
Распространенный вид – один товар в разных цветах. Например, site.ru/product-red.html; site.ru/product-green; (платье «Модель» красное, платье «Модель» зеленое)
В таких случаях рекомендую объединить карточки товаров с возможностью выбрать цвет на странице. Исключением может быть, если у запросов высокая частота. Например, вы видите по Вордстату, что для запросов «платье короткое зеленое» и «платье короткое красное» высокая частота – тогда, возможно, стоит разделять их, но хотя бы как-то уникализировать, чтобы не было таких дублей.
Еще одна распространенная ситуация – один товар находится в нескольких категориях. Например, платье находится в категории «Платья» и «Короткие платья». Ничего плохого в этом нет, но если URL формируются таким образом:
site.ru/platya/product1.html; site.ru/korotkie-platya/product1.html
, это надо исправлять.
Как исправить: переработка структуры, 301 редирект; один товар – один url (выбираем одну категорию)
Вопрос: Можно ли использовать rel=canonical в этом случае? – Если для карточек товаров вы будете использовать rel=canonical, вы можете в них запутаться – что на что направлять, но в общем проблему это решит.
3. Частичные дубли – страницы, у которых большая часть контента пересекается.
Этим страдают блоги, например, дублируются анонсы. С одной стороны в этом ничего такого нет, так устроены движки, но мы рекомендуем писать уникальные анонсы к статьям блога.
То же самое может касаться карточек товаров. Например, у меня был медицинский сайт, на страницах разных врачей был большой блок с описанием услуг (порядка 10 тыс. символов), который повторялся, уникального описания в сравнении с этим блоком было мало – около 1,5 тыс. знаков. Получается, что все карточки являются дублями, несмотря на то, что есть какой-то уникальный контент – в таком случае надо вносить изменения.
Вопрос: Как решили проблему с дублями на медицинском сайте? Было 2 примера с дублями на медицинских сайтах. В первом примере (сайт по записи к врачам) закрывали от индексации частичные дубли либо убирали совсем – сделали так, чтобы основного уникального контента было больше. Во втором примере дублировались описания мед. препаратов (у некоторых лекарств разные названия) – под каждое название были созданы страницы. У конкурентов было то же самое, только были добавлены отзывы и была возможность купить препараты. Мы улучшили уникальность этих страниц.
Как решить: закрываем от индексации в помощью ajax или пишем уникальные анонсы/тексты.
CANONICAL:
Чтобы избежать недоразумений в виде GET-параметров и других подстановок в URL, рекомендуется использовать rel=“canonical”.
Данный атрибут показывает поисковой системе канонический URL, который нужно индексировать.
Рекомендуем добавить на все статические страницы (для страниц результатов поиска не подходит) для предупреждения появления различных дублей:
- дубли из-за разного регистра: site.ru/page1 и site.ru/Page1
- дубли из-за utm-меток: *utm_source=, /*utm_campaign=, /*utm_content=, /*utm_term=, /*utm_medium=
- различные дубли страниц сортировок: /*sort, asc, desc, list=*
Таким образом, например, для страницы site.ru/page1 rel=»canonical» будет выглядеть следующим образом:
<link rel=»canonical» href=» site.ru/page1″ />
По поводу того, что страницы иногда не индексируются с rel=»canonical» – Google достаточно хорошо все это «ест», с Яндексом бывают проблемы, но в последнее время их все меньше.
Подробнее о rel=»canonical» можно почитать по следующим ссылкам:
https://support.google.com/webmasters/answer/139066?hl=ru
https://help.yandex.ru/webmaster/controlling-robot/html.xml#canonical
КАК ИСКАТЬ ДУБЛИ?
Самой простой способ найти серьезные, полные дубли – поиск по title.
Обычно у таких дублей title одинаковые.
1) Можем зайти в Google Search Console – во вкладке «Оптимизация Html» увидим количество дублей:
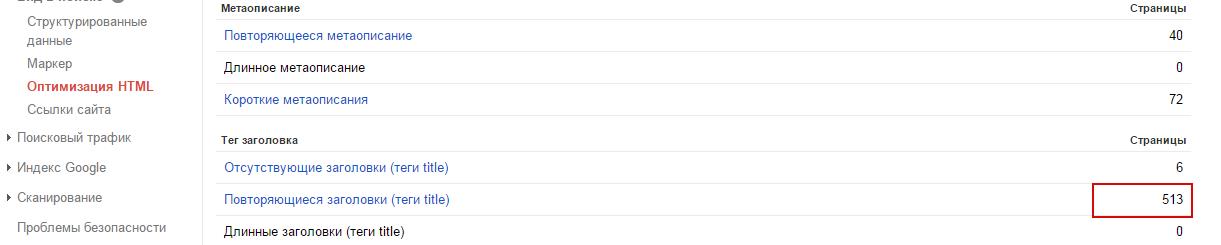
Единственное – не обязательно они в индексе, но, по крайней мере, мы точно знаем, что у нас есть какие-то дубли.
2) Можем парсить сайт с помощью таких программ, как Screaming Frog или Netpeak Spider.
По сути, они выполняют одну и ту же функцию – скачивают все странички и подсвечивают дубликаты title.

Слева – Screaming Frog (платно, бесплатно 500 урлов). Нажимаете Duplicate – и получаете все страницы с дубликатами
Справа – Netpeak Spide (бесплатно, но меньше функционала). Так же выбираете «Дубликаты» – и получаете список.
Опять же, не факт, что все эти страницы в индексе, но эти дубли могут тратить ваш краулинговый бюджет, робот на них заходит, и вы теряете время.
3) Через поисковый оператор intitle.
Допустим, вы предполагаете, что в какой-то категории у вас могут быть дубли, или вы хотите проверить – взять основные категории и, введя такую конструкцию в поиске Яндекса или Google, увидеть страницы, которые дублируются по title:

Это удобно, когда вы хорошо знаете свой сайт.
4) Через поисковый оператор inurl.
Такой способ удобен, когда вы работаете с большим сайтом и плохо с ним знакомы или знаете сайт, но никогда такого не делали.
Вводите site.ru (ваш домен) / inurl (категория)
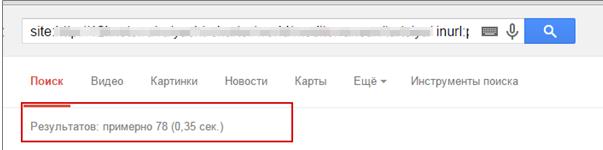
Вручную просматриваем, есть ли какие-то дубли по категориям.
Ручная работа – лучшая, потому что, просматривая каждую страницу, вы реально можете увидеть то, что в индексе, автоматизация не всегда на 100% дает достоверный результат.
Если вы знаете, что у вас есть какие-то определенные параметры, например, вы их видите, когда пользуетесь сортировками, то можете по оператору inurl вбить этот параметр, как на нижнем скриншоте, и вы получите все урлы, которые есть в индексе с этим параметром:
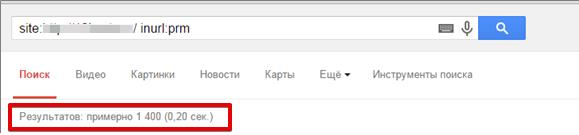
Среди них выявить дубли, если они есть, не составит труда.
КАК ИСКАТЬ ЧАСТИЧНЫЕ ДУБЛИ
1) Поиск по фрагментам текста
Берем фрагмент текста и вбиваем в поиск с оператором site: и сразу увидим, есть ли у нас какие-то пересечения по тексту.
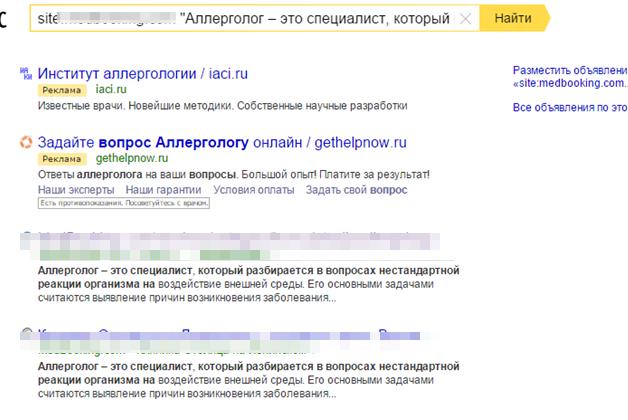
Не стоит брать только 1 фрагмент, берите несколько фрагментов со страницы, смотрите, есть ли пересечения по всем фрагментам.
2) С помощью сервиса seoto.me
Частичные дубли он находит «на ура». Находит то, что вручную не всегда можно заметить, показывает, какой процент текста и какое количество символов пересекается.

Сервис платный, но показывает около 30% всего сайта, для оценки вам этого будет вполне достаточно.
МУСОРНЫЕ СТРАНИЦЫ
К ним относятся:
— Технические страницы:
- Корзина /cart/
- Регистрация /register/
- Пользователи /user/
- Файлы /files/
По умолчанию должны быть закрыты от индексации.
— Пустые страницы (страницы с ошибками, пустые, незаполненные карточки товаров):
В принципе, любые страницы с малым количеством контента можно считать мусорными.
Как найти:
— Пробиваем по поисковым операторам inurl
— Ищем страницы с малым количеством контента (Screaming Frog) – можем оценить по количеству слов. Если контента мало, надо посмотреть, что это за страницы.
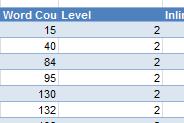
15-40 слов – это очень мало
Если это технические страницы, вы просто закрываете их от индексации, если это док-файлы, в которых нет ценной информации, то их тоже можно закрывать.
Если это важные страницы, и вы хотите, чтобы они индексировались, то закрывать от индексации их не стоит.
— Мусорные поддомены (часто тестовые дубли)
Мы на поддоменах тестируем какие-то свои движки, либо просто программист что-то делал на них, в итоге получаем поддомены, которые являются практически полными дублями всего сайта.
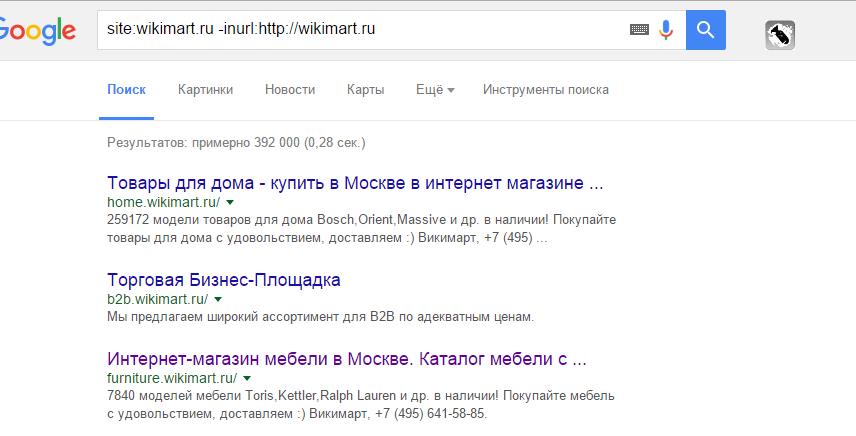
Как их найти?
 Берем основной домен, исключаем известные нам домены (как на примере: ~~ host:wikimart ~~host:appliances.wikimart). Т.е. методом исключения мы находим, нет ли каких-либо технических поддоменов.
Берем основной домен, исключаем известные нам домены (как на примере: ~~ host:wikimart ~~host:appliances.wikimart). Т.е. методом исключения мы находим, нет ли каких-либо технических поддоменов.
То же самое в Google. Пишем так:
СКОРОСТЬ ЗАГРУЗКИ САЙТА
Это фактор ранжирования сайта (Google очень щепетильно к нему относится), и он может негативно сказываться на краулинговом бюджете (если скорость загрузки сайта низкая, то и краулинговый бюджет становится меньше).
Общие требования:
— Время отклика сервера (как быстро сервер отвечает на запрос от браузера) – до 300 мс
— Время загрузки страниц – около 3-5 с
Как проверять?
С помощью инструментов:
— Google Analytics
— https://www.webpagetest.org/
— https://developers.google.com/speed/pagespeed/insights/
1. Заходим в GA – Вкладка «Поведение» – «Время загрузки»:
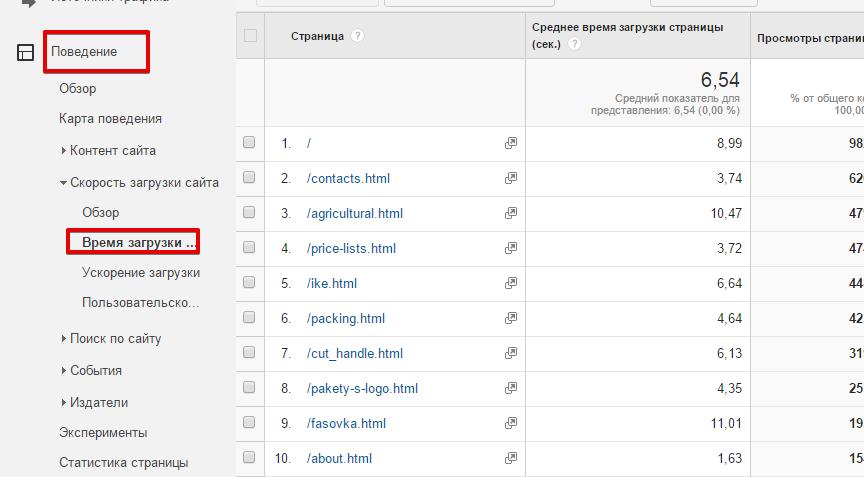
Видим, какое время загрузки у каждой страницы за определенный период времени.тут видно, что время завышено: главная страница – под 9 с, загрузка прайс-листа нормальная – 3,7 с.
2. Берем эти страницы и загоняем в сервис https://www.webpagetest.org/, который нам покажет, в чем причина такой медленной загрузки (возможно, много запросов, большие файлы.
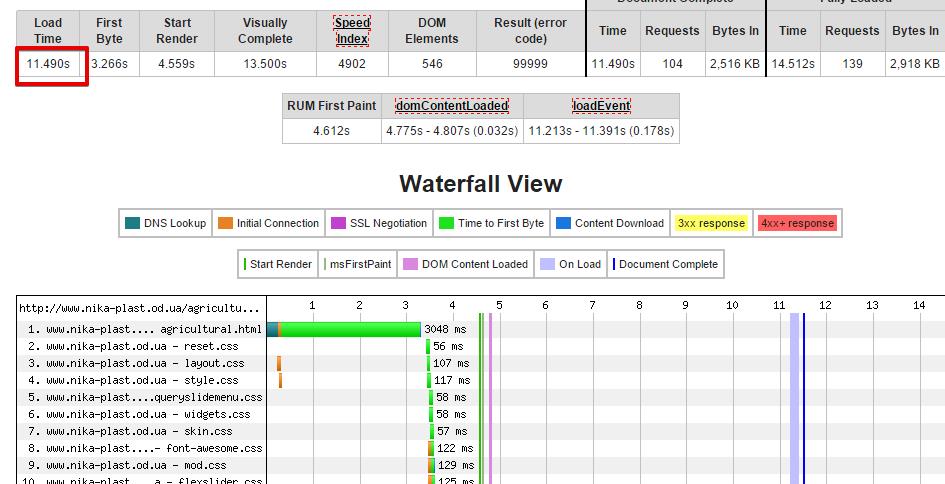
Показана полная загрузка сайта – 11,49 с, пользователь получил картинку через 13 с. Это очень много, т.е никакой конверсии с этого перехода мы не получим, скорее всего, пользователь так долго ждать не будет и просто закроет страничку, а наш сайт еще и плохо будет ранжироваться. По каждому запросу мы видим, сколько тратится времени и на что.
Что есть что:

Эти полоски разного цвета обозначают разные параметры.
- Поиск DNS (темно-зеленый) – грубо говоря, это время конвертации домена в IP-адрес. Мы повлиять на этот параметр не можем, но обращать внимание на него тоже стоит.
- TCP-подключение (оранжевый цвет) – перед тем как отправить запрос серверу, необходимо создать TCP-соединение. Должно быть создано только на первых полях (большого кол-ва таких полосок быть не должно). Иначе будут проблемы с производительностью.
- Время получения первого байта (салатовый) – сколько времени браузеру требуется для приёма первого байта, то есть получения ответа от сервера при запросе конкретного URL.
- Загрузка контента (синий) – сколько времени браузер тратит на загрузку контента.
Мы можем оптимизировать скорость загрузки по высоте и по ширине (в высоту – запросы, в ширину – скорость ответа)
Оптимизация по ширине:
– Если много оранжевого:
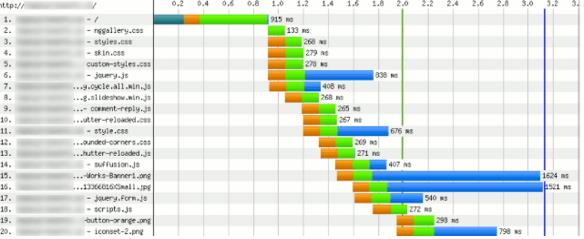
Скорее всего, у вас не включено постоянное соединение. Необходимо включить (подробнее). Хотя это достаточно редкое явление.
– Если много синего:
![]()
Этот случай распространенный. Если у вас долгие синие полосы, значит, у вас долго грузятся скрипты, картинки. Например, как видно на скриншоте, файл формата png – длинная синяя полоса, картинка подгружалась почти 1,6 с. Это много и ее надо оптимизировать.
– Если много зеленого – браузер долго ждет передачи данных от сервера.
Стоит задуматься о смене хостинга или настройке CDN (сеть доставки контента).
Подробнее – https://habrahabr.ru/company/sports_ru/blog/198598/.
Общие рекомендации:
— Оптимальный размер изображений – до 100Кб (если это возможно)
— Сжимаем скрипты и стили в gzip (все технологии в интернете описаны)
— Настраиваем CDN
Наша задача – уменьшить вес страницы. Чем меньше вес страницы, тем быстрее она будет загружаться.
Оптимизация по высоте
В этом случае нам надо сократить количество HTTP-запросов.
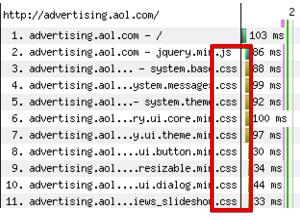
Часто можно видеть, когда 10 СSS находятся в шапке или, еще хуже, в футере сайта. При каждом обращении к каждому CSS идет лишний запрос к серверу, сервер отдает этот CSS. Если эти СSS большие, то все это очень затягивает загрузку.
Мы должны следить за этим, сокращать количество HTTP-запросов, уменьшая количество скриптов и CSS.
Общие рекомендации по оптимизации по высоте:
— Объединяем CSS-файлы
— Объединяем JS
— В верстке используем спрайты
Пример:
![]()
Этим почти никто не занимается, поэтому особенно важно обращать внимание.
Ускорение рендеринга (ускорять загрузку страницы для пользователя, т.е. ее визуальную часть)
– Ставим CSS вверх (в блок <head>), скрипты опускаем вниз. Таким образом, когда браузер обрабатывает все данные, сразу подгружает визуальную часть, пользователь думает, что страница уже загрузилась и начинает ее просматривать, пока грузится все остальное.
– Включаем скрипты асинхронно:
<script async src=»example.js»></script>
Здесь же скрипт будет скачиваться асинхронно, не мешая обработке HTML-разметки страницы.
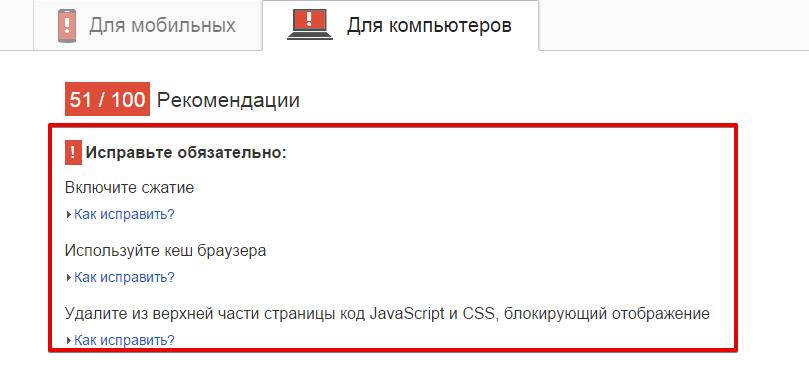
– Следуем рекомендациям сервиса Google Page Speed (как для мобильных, так и для ПК). Он сам сжимает скрипты, изображения, т.е. вы можете скачать все готовое, прогнав сайт через него.
ПРОВЕРКА ИНДЕКСАЦИИ ВАЖНЫХ ОБЛАСТЕЙ СТРАНИЦЫ
Программисты нечасто обращают внимание на SEO-оптимизацию, из-за этого часто всплывают ошибки. Буквально недавно к нам пришел сайт на аудит, на скриншоте видно, как видел страницу категории пользователь и как Яндекс:

В отличие от пользователя, который видел карточки товаров, Яндекс видел только текст. Все подгружалось скриптами, скрипты были закрыты от индексации, Яндекс скрипты до последнего времени не читал, в итоге получилось, что на коммерческом сайте есть только текст, и он не ранжируется по коммерческим запросам.
Обязательно через сохраненную копию проверяйте, как видит ваш сайт Яндекс.
То же самое и в Google – проверяем, как видит сайт GoogleBot, в Search Console:
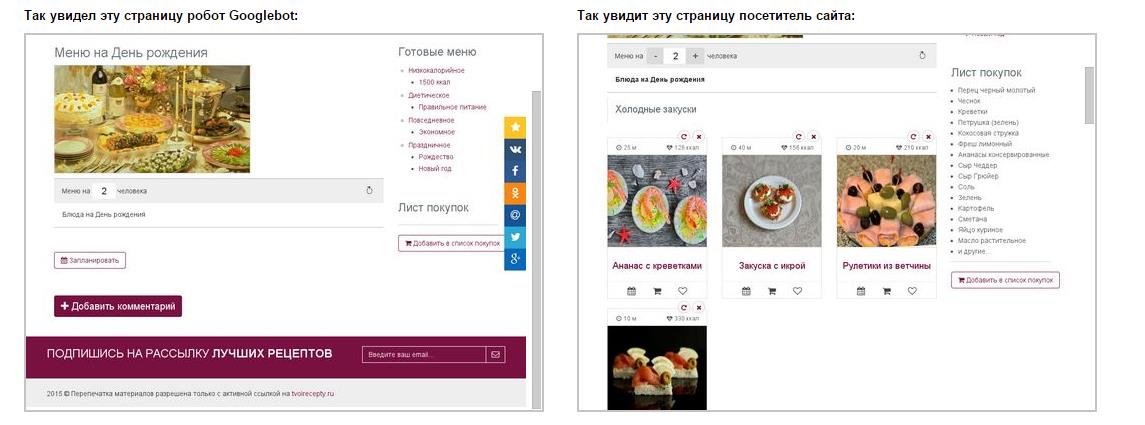
На примере пользователь видит карточки рецептов, а GoogleBot не видит, для него это просто страничка с одной картинкой (за такое можно получить бан).
ТРАФИК РЕЗКО УПАЛ
С какими техническими проблемами это может быть связано:
1. Есть вероятность, что ваш сайт недоступен или был недоступен какое-то время.
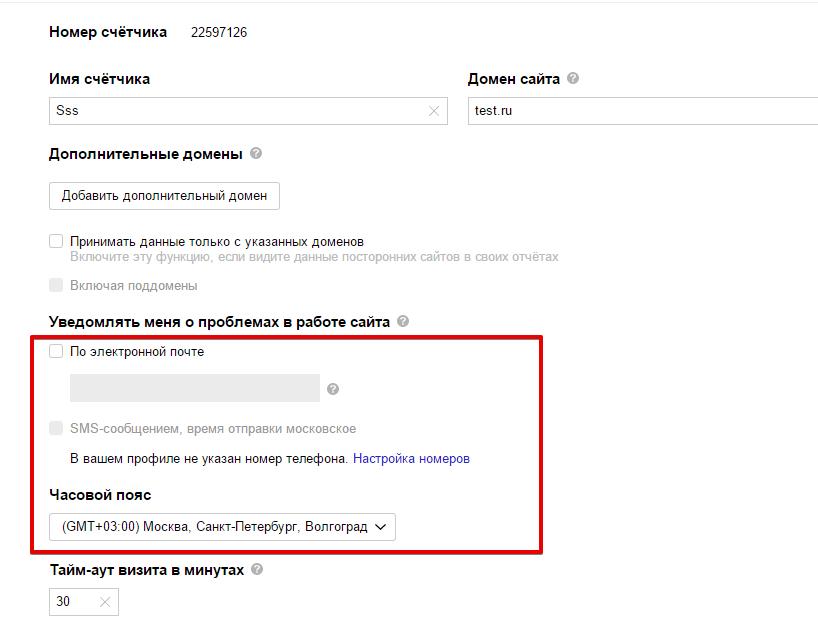
– Чтобы контролировать это, настройте в Яндекс.Метрике SMS (e-mail) уведомление о доступности сайта (Настройки – Уведомлять меня о проблемах с сайтом):
– Мониторьте Search Console – вы будете получать сообщение о проблемах с доступностью:
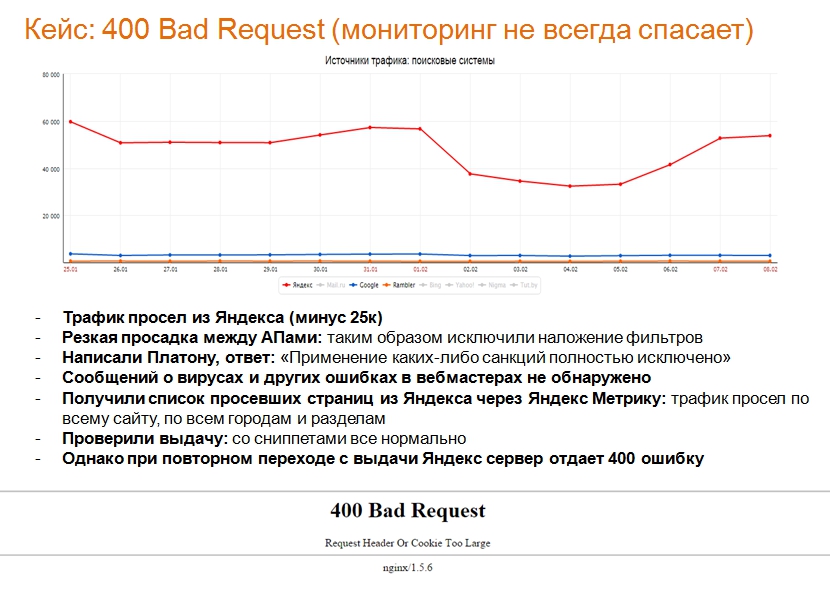
Нестандартная ситуация – сайт доступен, трафик в Яндексе падает. Наш небольшой кейс:
2. Могут быть проблемы с редиректами – владельцы переносят сайт на новый движок и забывают настроить 301 редирект. Казалось бы, очевидно, но такая ошибка встречается часто.
Отследить просто: Google Search Console – Ошибки сканирования – Ошибки 404 (у вас резко будет расти количество 404 ошибок):
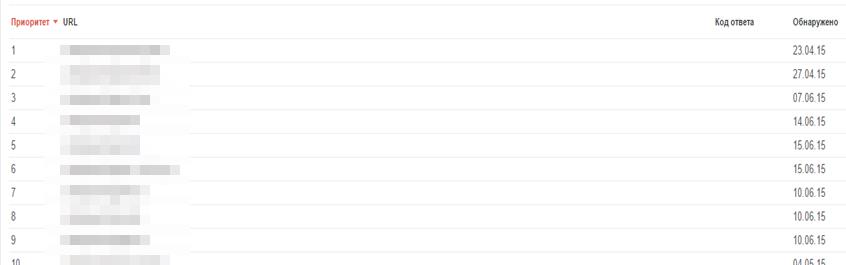
Сообщения в Яндекс.Вебмастер:

У нас был случай – владелец сайта решил переехать на другой хостинг, в редиректах просто поменяли главное зеркало с www на без www. Трафик с Яндекса просел достаточно быстро. Получилась такая ситуация – сайт-главное зеркало вылетел, перестал быть главным, на поддомене был тестовый сайт, его Яндекс проиндексировал и сделал его главным зеркалом.
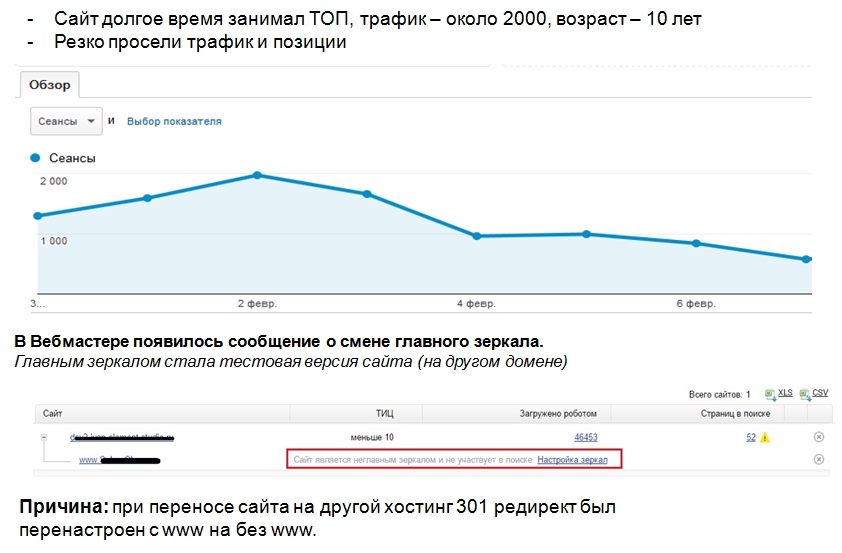
Всегда следите за сообщениями в вебмастерах и 301 редиректами.
3. Может просесть из-за вирусов.
Также мониторим сообщения в Вебмастерах:
— Яндекс:

— Google:
Можно проверить в Google по ссылке https://goo.gl/4yMdJI.
Если вирусы есть, лечиться можно с помощью антивируса Manul от Яндекса.
ДРУГИЕ РЕКОМЕНДАЦИИ:
- В robots.txt для каждого робота пишите директивы отдельно:
User-agent: Yandex
Disallow: /admin/
Host: site.ru
User-agent: Googlebot
Disallow: /admin/
- Формируйте sitemap.xml (желательно в автоматическом режиме)
- Код ответа страницы 404 не должен быть 200, только 404 Not Found (это важно)
- Подзаголовки (h1-h6) не участвуют в верстке
- CSS и JS выносите в отдельные файлы
- Страницы пагинации не закрывайте от индексации:
Единственные требования, которые надо соблюдать – для таких страниц прописываем уникальные title: Телевизоры / Страница 2; Телевизоры / Страница 3. Текст должен индексироваться только на основной (первой) странице. Модифицируем пагинатор, понижаем уровень вложенности:
Правильно (робот будет быстро перемещаться по страницам):
![]()
Неправильно:

ПОЛЕЗНЫЕ ССЫЛКИ:
Сервисы и программы:
SEOlib (отслеживание позиций, обновление алгоритмов и т.д.) – seolib.ru
Screaming Frog – https://screamingfrog.co.uk/seo-spider/
Google Search Console – https://www.google.ru/webmasters/
Яндекс.Вебмастер – https://webmaster.yandex.ru/sites/
Google Analytics – https://www.google.com/analytics/
Яндекс.Метрика – https://metrika.yandex.ru/
Google Page Speed – https://developers.google.com/speed/pagespeed/insights/
Web Page Test – https://www.webpagetest.org/
Яндекс Манул – https://yandex.ru/promo/manul
Почитать:
Блог SiteClinic – siteclinic.ru/blog
Подробная статья об оптимизации скорости загрузки – https://habrahabr.ru/post/178561/
ВОПРОСЫ НАШИХ СЛУШАТЕЛЕЙ:
– Пагинация – это же дубли?
Пагинация – это не дубли, карточки товаров на страницах пагинации разные, соответственно, и контент разный. Единственное – часто дублируется текст и тайтлы, а это ошибка, лучше ее не допускать.
– Считается ли страница дублированной, если я в тайтл добавил артикул, удалил дискрипшин, но описание на странице осталось такое же?
Если это описание – большая часть контента, то да.
– Какой текст тогда закрывать на пагинации и как закрывать?
Если у вас интернет-магазин, листинг товаров и внизу текст на 1000-1500 символов, этот текст на страницах 2,3,4 нужно закрывать либо удалять. Для Яндекса можно закрыть тегом no index либо подгружать его скриптами, закрытыми от индексации. Главное в robots.txt закрыть от индексации скрипт, который выводит этот текст.
– А можно использовать пагинацию не в стандартном исполнении, а аяксом подгружать?
Можно, но в таком случае желательно, чтобы была html-версия этой страницы, чтобы структура пагинации все равно сохранялась. Т.е. пользователь переходит как по странице пагинации, а поисковику мы «отдаем» html.
– Насколько корректно прописывать странице canonical на саму себя? Распространенная история в вордпресе.
Обязательно это нужно делать, таким образом мы избегаем появления большого количества различных дублей.
– Как закрывать от индексации с помощью аякс? Я где-то читал что скриптами закрывать нельзя, гугл уже видит скрипты….
У нас выхода нет – есть блоки, которые нам нужно закрывать, да, делать это нельзя, но если будет закрыт один скриптик, я не думаю, что за это будут применяться какие-то санкции.
– А зачем пагинация в индексе?
В данном случае нам важно, чтобы хорошо индексировались карточки товаров. Мы можем прописать на странице пагинации метатег «noindex, follow», который закроет контент от индексации и оставит индексацию ссылок, но не всегда это корректно работает. Поэтому для хорошей индексации карточек товаров, страницы пагинации лучше оставлять в индексе.
– А как можно проверить асинхронно загружаются скрипты или нет?
Анна Себова: Скрипт асинхронно загружается, если:
1. При подключении скрипта указан атрибут async или defer
2. Либо в коде подключения указан параметр async= true
Как, например, у кода Google Analytics:
_gaq.push([‘_trackPageview’] );
(function() {
var ga = document.createElement(‘script’); ga.type = ‘text/javascript’; ga.async = true;
ga.src = (‘https:’ == document.location.protocol ? ‘https://ssl’ : ‘https://www’) + ‘.google-analytics.com/ga.js’;
var s = document.getElementsByTagName(‘script’)[0]; s.parentNode.insertBefore(ga, s);
})();
– Есть несколько десятков тысяч событий, каждое событие – 1 страница. 90% событий –прошедшие. Стоит ли закрывать эти страницы, редирект делать или что-то еще? Проблема в том, что трафик с ПС идет на прошедшие события и это раздражает людей.
Можно делать 301 редирект на страницу категории, к которой относится это событие.
– Если делать 301 редирект с прошедших событий, не просядет ли трафик в дальнейшем, по идее страницы вылетят из индекса.
Страницы вылетят из индекса, но вы можете прокачивать основные категории. Мы так делаем на страницах по недвижимости, например, – со старых карточек делаем 301 редирект.
– Насколько важна проверка на валидность html-кода?
Важна, но не критична. Если у вас совершенно невалидный код, большой и с грубыми ошибками, то, наверное, при прочих равных условиях это будет минус по сравнению с конкурентами. Но чтобы это сильно влияло на рейтинг сайта, я не замечал. Конечно, лучше, чтобы он работал хорошо.
– (robots.txt) – надо ли писать отдельные директивы для мобильного робота гугла и яндекса?
Надо, сейчас мобильным версиям уделяют много внимания.
– В поиск по конкретным товарам в выдачу Яндекса попадает страница раздела, а не карточки товаров.
Индивидуальный вопрос – может быть, у вас плохо оптимизирована карточка товара, может, закрыта от индексации, может, появилась недавно – вариантов может быть очень много – надо смотреть. Хочу сказать, что если релевантность периодически меняется, это могут быть и эксперименты Яндекса.
– Какой % различного содержания должен быть на странице, чтобы не считать ее дублем?
Например, в медицинской тематике вполне допустимы 80% одинакового контента, в строительной, скорее, лучше меньше – процентов 30-40. Если не знаете ответ, смотрите по ТОПу. Если в ТОПе много страниц с такими дублями, то, скорее всего, это допустимо,
– Как отслеживать дубли?
Чтобы отслеживать и контролировать ситуацию, советую раз в месяц проводить мини-аудит страниц через Screaming Frog, смотреть на Search Console,
– Трафик с Яндекса в 2 р. меньше, чем трафик с Google.
Это распространенная ситуация, доли трафика разные, иногда ранжирование отличается, например, Google реагирует на какой-то небольшой перспам, региональность у него совершенно другая, коммерческость он определяет по-другому. Так что это нормальная ситуация.
Если у вас есть какие-то вопросы, обязательно задавайте их в комментариях!
Еще по теме:
- Запись и текст вебинара: Как проанализировать сайты конкурентов Запись, презентация и текстовая версия вебинара на тему "Как проанализировать конкурентов" с Никитой Простяковым. Вы узнаете, какую информацию можно почерпнуть на сайтах своих конкурентов и...
- Правила формирования title и description (видео и текст вебинара) Видеозапись и текст вебинара, тема: "Как правильно составлять title и description". Евгений Аралов рассказывает о правилах формирования, ошибках, том, чего нельзя делать при составлении title...
- Юзабилити на практике – улучшаем конверсию, позиции и трафик (видео с вебинара) Во время вебинара Владимир Столбов рассказал, как с помощью юзабилити можно улучшить конверсию и трафик интернет-магазина или другого коммерческого сайта. Смотрите видеозапись вебинара, презентацию и текстовое...
- Запись вебинара «Как создать эффективное семантическое ядро» Видеозапись вебинара, о том, как улучшить видимость сайта в выдаче за счет правильного составления семантического ядра, презентация и текстовая версия с вопросами слушателей. Евгений Аралов...
- Добавочная ценность. Как не попасть под АГС и увеличить посещаемость информационного проекта Подготовили для вас запись вебинара - 28 января Александр Явтушенко во время бесплатного вебинара рассказал, в чем заключается добавочная ценность сайта, в каких случаях можно попасть...

Оцените мою статью:
 (7 оценок, среднее: 5,00 из 5)
(7 оценок, среднее: 5,00 из 5)Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.

Обязательно приму участие в вебинаре. Освежу знания, модет нового чего узнаю или поделюсь своими знаниями. Ведь технический аудит тем, хорош, что позволяет подокаться практически до всех косяков мешаюших успешному продвижению сайта.
Записываюсь-)
Пытаюсь зарегистрироваться. Выдает вот ошибку, что якобы моего ящика не существует. Хотя имейл рабочий. Подскажите, в чем проблема?
Добрый день, Евгения! Проверила у себя — форма регистрации работает.
Напишите, пожалуйста, почту, которую вы указываете, в комментарии (могу не публиковать). Я попробую добавить ее вручную и уточню у сервиса рассылки, в чем может быть проблема.
Евгения, еще раз здравствуйте! Воможную причину узнала, прислала Вам на почту.
А как можно посмотреть запись вебинара? Тем кто не записался, будет доступно?
Ева, посмотреть можно будет, но чуть позже. Тем, кто регистрировался на этот вебинар, я уже отправила письма с записями, скоро должны прийти. А остальным запись будет доступна на этой странице. Постараюсь выложить до конца дня.
Добрый день!
Вы пишете «Поэтому для хорошей индексации карточек товаров, страницы пагинации лучше оставлять в индексе.»
А разве sitemap.xml не справляется с этой задачей? Т.е. Вы предлагаете еще и пагинацией роботов нагружать только ради этого?
Добрый день. Если бы для хорошей индексации хватало только sitemap.xml, то никаких бы проблем не было. Как показывает практика, sitemap.xml не сильно на нее влияет.
Соглашусь с Вами, что лишние страницы в индексе с точки зрения поисковых систем — не очень хорошо. В таком случае можно закрывать страницы пагинации мета-тегом META NAME=»ROBOTS» CONTENT=»NOINDEX, FOLLOW», в таком случае робот будет переходить по ссылкам, но не будет индексировать контент.
Однако мы оставляем страницы пагинации в индексе.
Спасибо! Попробуем поэкспериментировать.
Здравствуйте! По поводу распространенных дублей:
доступность с сайта с / и без /, а также с index.php. Редирект должен быть настроен на всех категориях или только главной?
Подскажите, какой метод избавления от дублей фильтра более эффективен: тег noindex, nofollow или размещение параметров фильтра в robots.txt?
И в вашей статье не совсем понятно как искать страницы с малым количество контента: каким образом это можно сделать через оператор inurl и каким образом через screaminfrog. Заранее спасибо за ответ.
В случае со слешом для всех категорий. По index.php, в тех случаях, когда страницы доступны по таким адресам. Также обязательно проследите, чтобы все внутренние ссылки вели на правильные адреса (без редиректов).
1. Если дубли уже попали в индекс, то более эффективен noindex, nofollow. Если просто зарыть страницы в robots, то Google может не исключить их из индекса.
2. На мусорных страницах полезного контента мало или нет совсем, поэтому поисковикам сложно сформировать нормальный сниппет для подобных страниц. С помощью оператора inurl Вы сможете посмотреть список сниппетов интересующих вас страниц. Такого визуального осмотра иногда бывает достаточно, чтобы найти мусорные страницы попавшие в индекс.
В screaminfrog есть показатель количества слов — «Word Count» (показан на скриншоте в статье). С помощью него найдете подозрительные страницы.