
- (Обновлено: ) Юля Телижняк
- 10 минут
- Мануал

4. Законно ли парсить чужие сайты
В работе специалистов сферы информационных технологий часто возникает задача собрать какую-либо информацию с сайтов, например необходимо провести парсинг товаров с сайта конкурента. И она априори не может быть лёгкой.
Поэтому для автоматизированного и упрощённого извлечения и группировки данных был придуман парсинг.
В этом посте я собрала информацию о том, что это, как работает и для чего нужно, а также поделюсь методами и инструментами, с которыми парсинг станет для вас не такой сложной задачей.
1. Что такое парсинг сайтов
Процесс парсинга — это автоматическое извлечение большого массива данных с веб-ресурсов, которое выполняется с помощью специальных скриптов в несколько этапов:
- Построение запроса для получения первоначальной информации.
- Извлечение информации согласно прописанному алгоритму.
- Формирование и структурирование информации.
- Сохранение полученных данных.
Чтоб извлекались только определённые данные, в программе задаётся специальный язык поиска, который описывает шаблоны строк — регулярное выражение. Регулярное выражение основано на использовании набора определённых символов, которые описывают информацию, нужную для поиска. Подробнее о работе с регулярными выражениями вы можете узнать на посвящённом им сайте.
Инструменты для парсинга называются парсерами — это боты, запрограммированные на отсеивание баз данных и извлечение информации.
Чаще всего парсеры настраиваются для:
- распознавания уникального HTML;
- извлечения и преобразования контента;
- хранения очищенных данных;
- извлечения из API.
2. Зачем и когда используют парсинг
Зачастую парсинг используется для таких целей:
- Поиск контактной информации. Парсинг помогает собирать почту, номера телефонов с разных сайтов и соцсетей.
- Проверка текстов на уникальность.
- Отслеживание цен и ассортимент товаров-конкурентов.
- Проведение маркетинговых исследований, например, для мониторинга цен конкурентов для работы с ценообразованием своих товаров.
- Превращение сайтов в API. Это удобно, когда нужно работать с данными сайтов без API и требуется создать его для них.
- Мониторинг информации с целью поддержания её актуальности. Часто используется в областях, где быстро меняется информация (прогноз погоды, курсы валют).
- Копирование материалов с других сайтов и размещение его на своём (часто используется на сайтах-сателлитах).
Выше перечислены самые распространённые примеры использования парсинга. На самом деле их может быть столько, сколько хватит вашей фантазии.
3. Как парсить данные с помощью различных сервисов и инструментов
Способов парсить данные сайтов, к счастью, создано великое множество: платных и бесплатных, сложных и простых.
Предлагаю ознакомиться с представителями разных типов и разобрать, как работает каждый.
Google Spreadsheet
С помощью функций в таблицах Google можно парсить метаданные, заголовки, наименования товаров, цены, почту и многое другое.
Рассмотрим самые популярные и полезные функции и их применение.
Функция importHTML
Настраивает импорт таблиц и списков на страницах сайта. Прописывается следующим образом:
Пример использования
Нужно выгрузить табличные данные со страницы сайта.
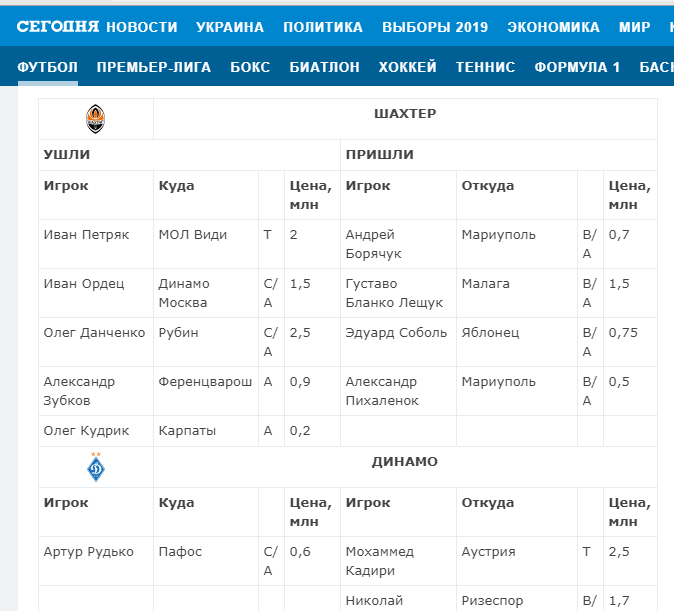
Для этого в формулу помещаем URL страницы, добавляем тег «table» и порядковый номер — 1.
Вот что получается:
=IMPORTHTML(«https://www.segodnya.ua/sport/football/onlayn-tablica-transferov-chempionata-ukrainy-1288750.html»;»table»;1)
Вставляем формулу в таблицу и смотрим результат:
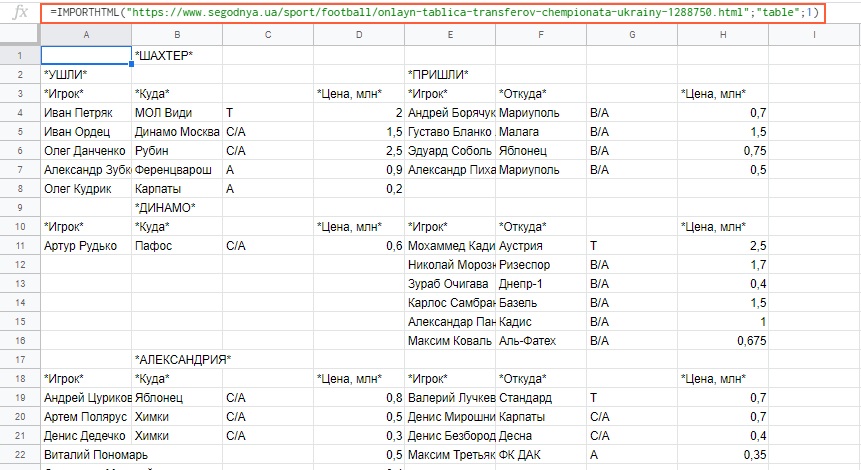
Функция importXML
Импортирует данные из документов в форматах HTML, XML, CSV, CSV, TSV, RSS, ATOM XML.
Функция имеет более широкий спектр опций, чем предыдущая. С её помощью со страниц и документов можно собирать информацию практически любого вида.
Работа с этой функцией предусматривает использование языка запросов XPath.
Формула:
Пример использования
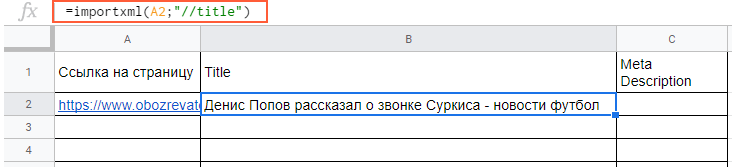
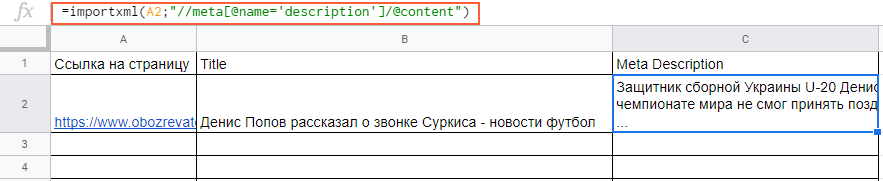
Вытягиваем title и meta description. В первом случае в формуле просто прописываем слово title:
=importxml(A2;»//title»)
В формулу можно также добавлять названия ячеек, в которых содержатся нужные данные.
С парсингом description нужно немного больше заморочиться, а именно прописать его XPath. Он будет выглядеть так:
meta[@name=’description’]/@content
В случае с другими любыми данными XPath можно скопировать прямо из кода страницы.
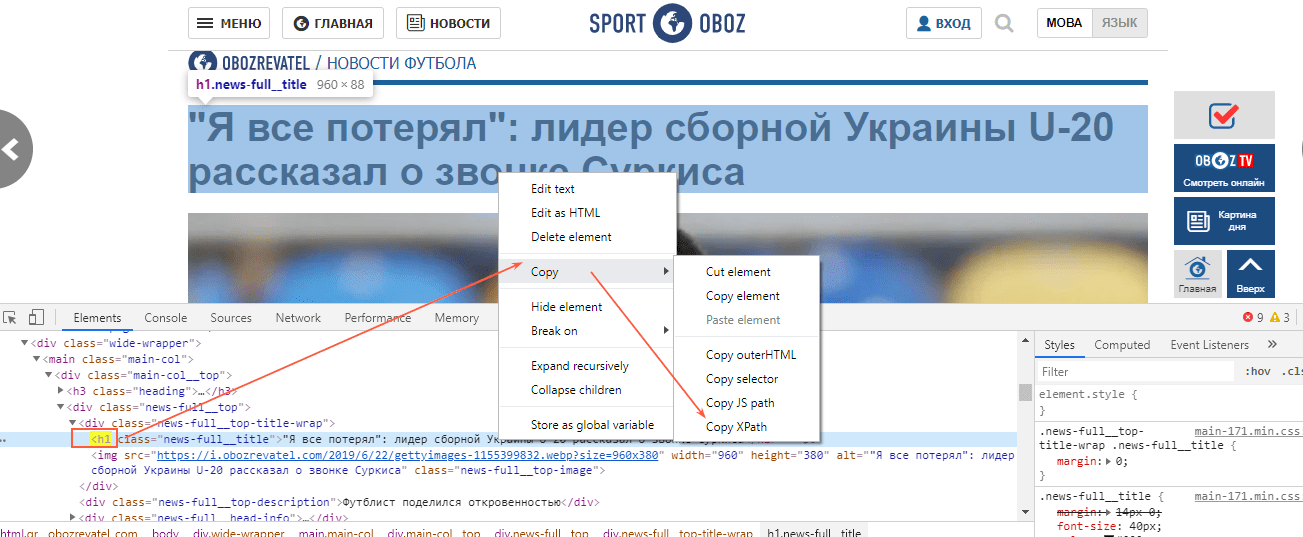
Вставляем в формулу и получаем содержимое meta description.
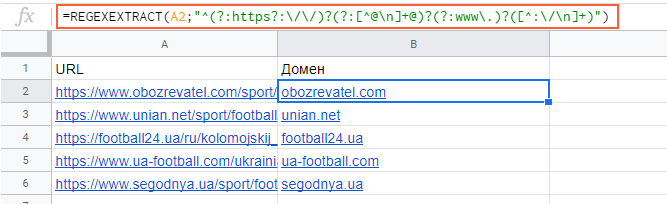
Функция REGEXEXTRACT
С её помощью можно извлекать любую часть текста, которая соответствует регулярному выражению.
Пример использования
Нужно отделить домены от страниц. Это можно сделать с помощью выражения:
Подробнее об этой и других функциях таблиц вы можете почитать в справке Google.
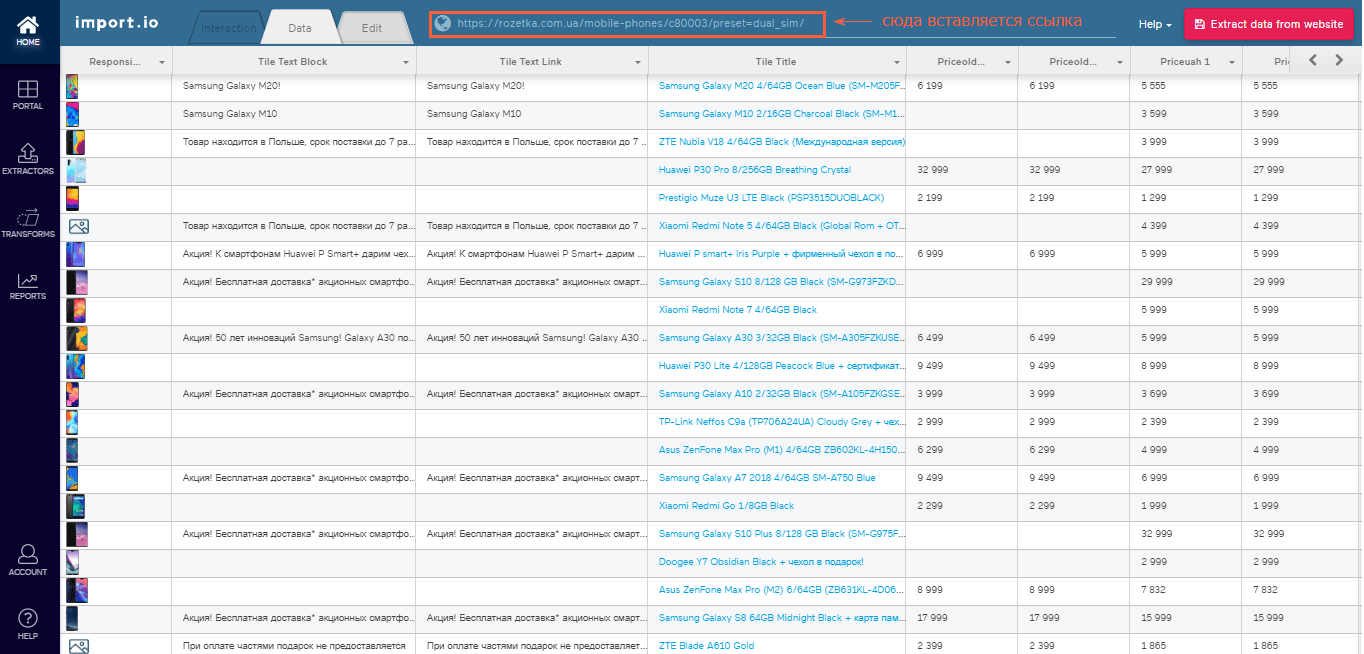
Import.io
Эта онлайн-платформа позволяет парсить и формировать данные с веб-страниц, а также экспортировать результаты в форматах Excel, CSV, NDJSON. Для использования import.io не требуется знания языков программирования и написания кода.
Чтобы начать парсить, необходимо вставить ссылку страницы, из которой вы хотите тянуть данные, и нажать на кнопку «Extract data».
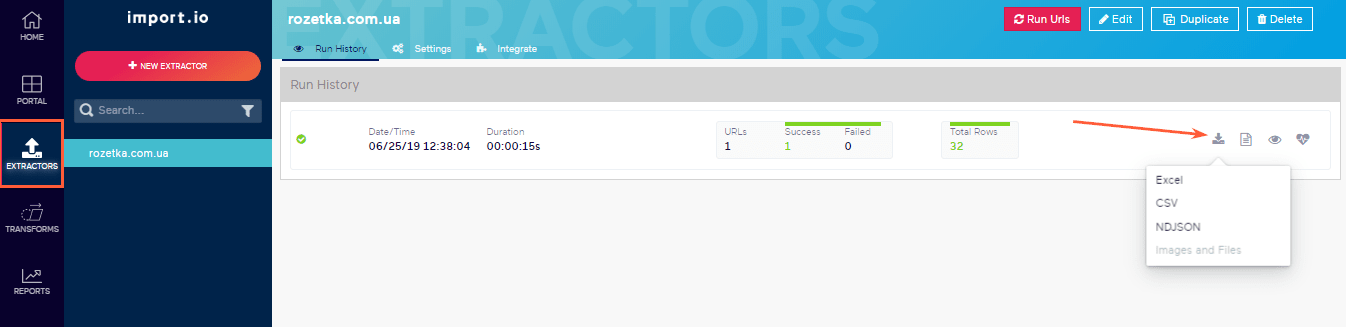
Для экспорта отчётов нажмите на иконку сохранения, затем перейдите в раздел «Extractors» и нажмите на кнопку скачивания.
Netpeak Spider
Netpeak Spider проводит SEO-аудит и позволяет проводить кастомный парсинг данных с сайтов.
Функция парсинга позволяет настраивать до 15 условий поиска, которые будут выполняться одновременно.
Чтобы извлечь данные со страниц сайта, выполните такие действия:
- Откройте страницу, с которой хотите собрать данные.
- Скопируйте XPath или CSS-селектор нужного элемента (например, цены).
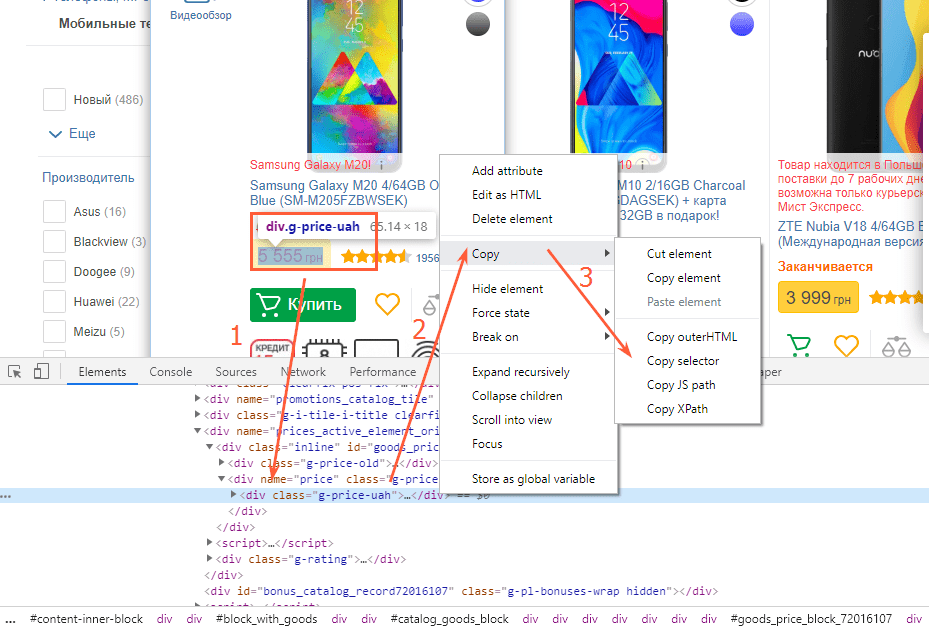
- Откройте программу, перейдите в меню настроек «Парсинг» и включите функцию (поставить «галочку»).
- Выберите нужный режим поиска и область «Внутренний текст».
- Вставьте XPath или CSS-селектор, который вы ранее скопировали.
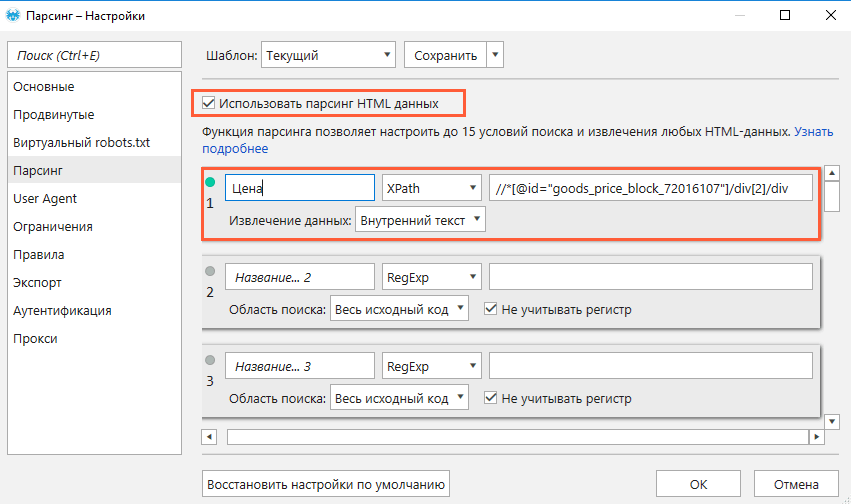
- Сохраните настройки.
- Вставьте домен сайта в адресную строку или загрузите список нужных страниц (через меню «Список URL» или горячими клавишами Ctrl+V, если список сохранён в буфер обмена).
- Нажмите «Старт».

- По завершении анализа перейдите на боковую панель, откройте вкладку «Отчёты» → «Парсинг» и ознакомьтесь с результатами.
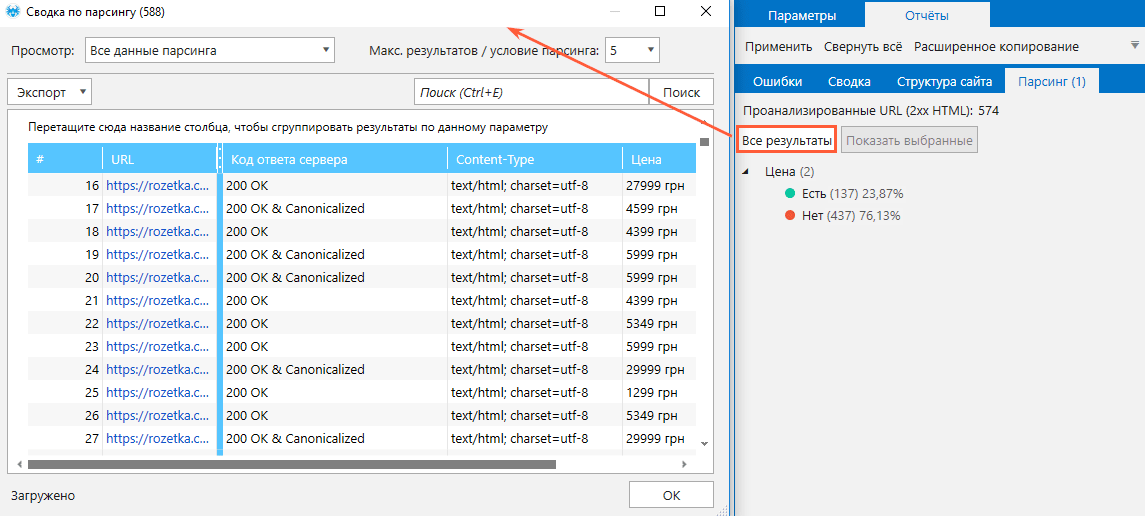
При необходимости выгрузите данные в формате Excel или CSV с помощью кнопки «Экспорт».
Netpeak Checker
Это десктопный инструмент, который предназначен для массового анализа доменов и URL и частично повторяет функционал Netpeak Spider (сканирует On-Page параметры страниц).
Netpeak Checker позволяет за считаные минуты спарсить выдачу поисковых систем Google, Яндекс, Bing и Yahoo.
Чтобы запустить парсинг, проделайте следующее:
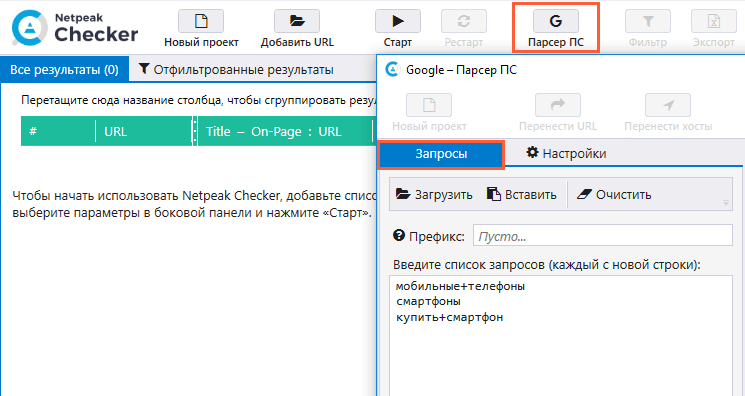
- Из основного окна программы перейдите в окно инструмента «Парсер ПС».
- Пропишите запросы, по которым будет парситься выдача. Если в запросе несколько слов, каждое слово должно отделяться знаком «+» без пробела.
- Перейдите на соседнюю вкладку «Настройки», где вы можете выбрать поисковые системы, выставить нужное количество результатов и выбрать тип сниппета.
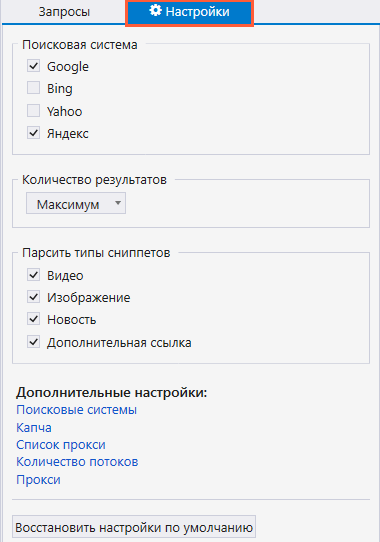
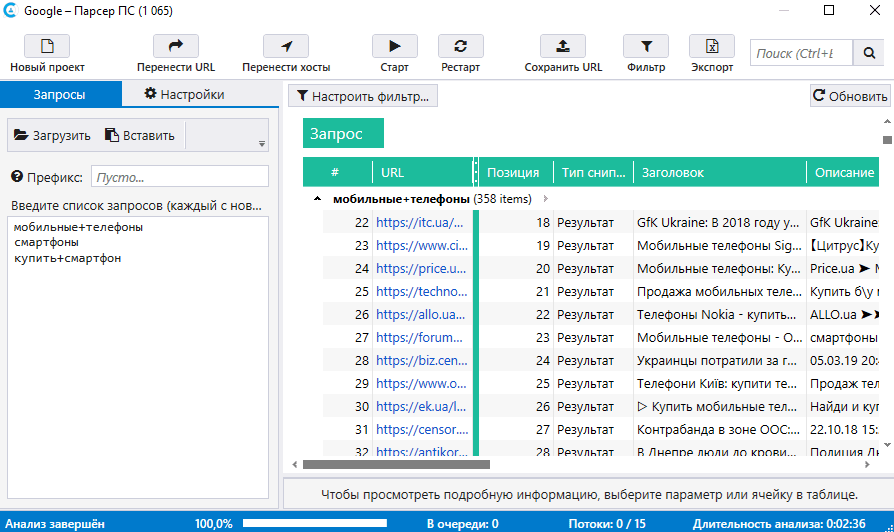
- Нажмите на «Старт», чтобы запустить парсинг.
- По завершении ознакомьтесь с полученными результатами в таблице.
ParseHub
Приложение ParseHub позволяет парсить сайты и обрабатывать JavaScript, AJAX, файлы cookie и работать с одностраничными приложениями.
Процедура извлечения данных со страниц или сайта строится таким образом:
- Создайте новый проект и введите адрес сайта или страницы, с которой вы хотите спарсить данные.
- После того как загрузка закончилась, начинайте выбирать нужные элементы (все элементы, которые вы выберете, отобразятся слева).
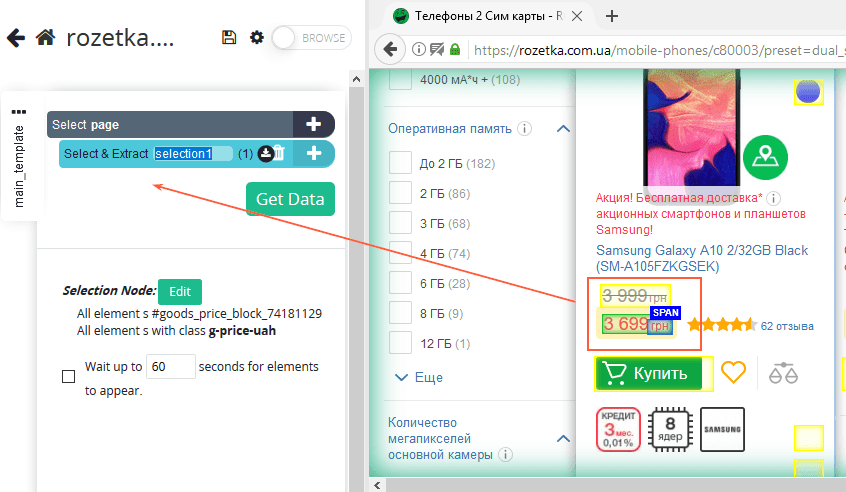
- После того как вы выбрали все нужные элементы, нажмите на кнопку «Get Data».
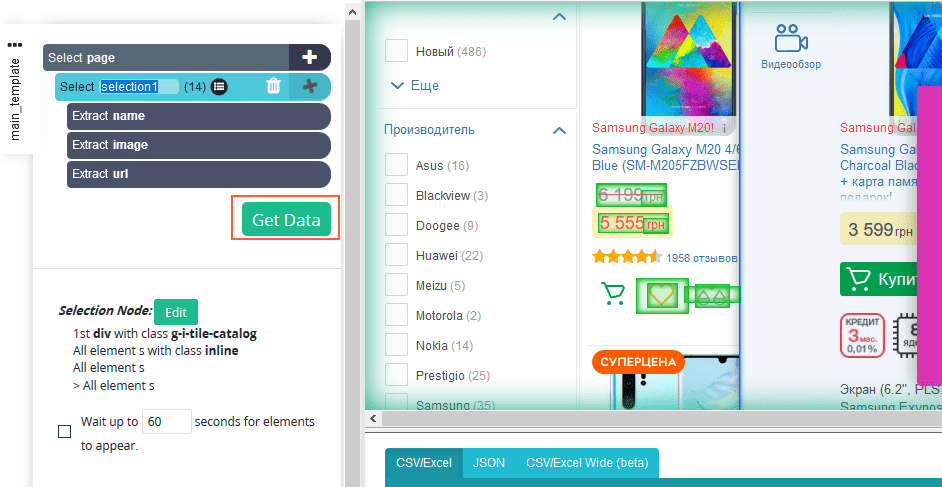
- Затем нажмите «Run».
- После завершения анализа скачайте полученные данные в удобном для вас формате.
4. Законно ли парсить чужие сайты
Парсинг данных с чужих сайтов не является нарушением закона, если при этом:
- извлекаемая информация размещена в открытом доступе и не составляет коммерческую тайну;
- не нарушаются авторские права и условия обслуживания;
- автоматизированный парсинг осуществляется законным доступом;
- парсинг не нарушает работу сайта.
Если вы не совсем уверены в своих действиях и опасаетесь, что можете преступить закон, перед парсингом лучше проконсультироваться с юристом.
Подводим итоги
Сбор и систематизация веб-данных — это трудозатратный процесс, который может отнимать несколько (даже десятков) часов. Но стоит его автоматизировать, и дело идёт на лад: времязатраты значительно сокращаются, а извлечение информации становится более эффективным. Для автоматизации есть немало программ и сервисов, которые отлично справляются с ролью парсера: можно тестировать и выбирать на свой вкус.
Но помните, что прежде чем собирать и заимствовать какие-либо данные с чужих сайтов, необходимо убедиться, не является ли это нарушением закона.
Поделитесь своими методами автоматизации парсинга в комментариях и расскажите, возникали ли у вас какие-либо проблемы при этом?
Еще по теме:
- Как посмотреть выдачу Google в конкретной стране? Подскажите, пожалуйста, удобный вариант посмотреть выдачу Google в конкретной стране. Поставила ВПН, выбрала США и вижу все равно и рекламу своей же страны, и выдачу....
- В каких приложениях можно посмотреть на нынешний трафик сайтов и 2-3 года назад? Подскажите, какие есть сайты или приложения, где можно посмотреть на нынешний трафик сайтов и 2-3 года назад? Ответ Среди самых популярных сервисов для оценки истории...
- Какая статистика по бэклинкам более точная — Ahrefs или данные Google Search Console? В Google Search Console показывает 5 доменов и 6 бэклинков, а в Ahrefs — 35 доменов и 86 бэклинков. Кому больше доверять? И правильно ли...
- Word Keeper vs Key Collector Скорость сбора фраз Количество фраз Скорость сбора частот Точность Гибкость настроек Цена Итог Для большинства SEO-специалистов Key Collector является основным инструментом по сбору семантики. Отличную...
- Обзор кластеризаторов семантики Coolakov Кластеризатор от RushAnalytics Кластеризатор от Serpstat KeyAssort Just-Magic Key Collector Топвизор Semparser Seoquick Кластеризатор от Majento Группировка запросов от Пиксель Тулс Megaindex Заключение Наиболее...

Оцените мою статью:

 (11 оценок, среднее: 4,73 из 5)
(11 оценок, среднее: 4,73 из 5)Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.

Можно ли importXML использовать для парсинга под авторизованным пользователем? Например доступ к информации можно получить после логина. Было бы здорово посмотреть такой кейс. И еще вопрос, по автоматизации importXML разве работает автоматически? Можно ли сделать процесс importXML по расписанию, к примеру?
Здравствуйте, Пётр )
1. По логину нельзя.
2. По расписанию можно, но нужно писать скрипт)
Юля спасибо! Но главное не написали сколько все это стоит, надо было рассмотреть и найти бесплатные решение с хорошим качеством исполнения. А эти инструменты все платные. В бесплатных режимах лимиты в 1000 страниц в месяц и меньше, добавьте сводную таблицу цен и лимитов на парсинг и если найдете 2-3 хороших бесплатных инструмента .
Юрий, спасибо за комментарий 🙂 Я учту это на будущее.
Google таблицы бесплатные (кэп), у скримин фрога есть также есть бесплатная версия, но да, с лимитами. ParseLab — бесплатный инструмент, но честно,пока не пробовала его.
напишите про блокировки и прокси
Радует, что есть компании и люди, которые готовы потратить время на то, чтобы упростить жизнь и работу других. Половину тулов я знал, но вот часть реально оказалась в новинку.
Мое первое открытие было, когда я понял, что с помощью importxml можно узнать h1 на всех страницах моего сайта. Второе открытие было, когда я установил триал Netpeak Spider