
- (Обновлено: ) Ольга С.
- 12 минут
- Решение задачи

Проверка состояния посадочных страниц
- Счётчик товаров на странице, выгрузка значений в Google таблицу
- Подсчёт количества товаров на странице
- Проверка индексации
Юный SEO-оптимизатор на старте карьеры обычно помогает старшим SEO-специалистам, получая от них объёмные и часто рутинные задачи. У начинающего оптимизатора много работы, она не всегда интересная, требует много внимания, сил и времени. Это может убить весь энтузиазм Junior. Если применять маленькие хитрости, часть задач можно выполнить в десятки раз быстрее. В статье я расскажу, какие приёмы и инструменты использовать для автоматизации работы, как сэкономить время.
Работа с семантикой
Сбор ядра – обязательный пункт курса молодого SEO-бойца. Во время обучения на работу с семантикой отводится от 3 до 5 дней. Этого времени может не хватить, если не знать, с чего начать, какой последовательности придерживаться.
Ниже расскажу о том, как ускорить работу с ядром за счёт использования неочевидных функций в знакомых программах.
1. Сбор маркеров
Сбор ядра начинается с анализа своего ресурса и сайтов конкурентов. Чтобы охватить всю семантику, по которой можно собирать трафик, стоит уделить внимание сбору маркеров. Именно они будут базой, на основании которой Key Collector подберёт хвосты.
Key Collector даёт возможность достать фразы всех уровней и их словоформы. Упустить несколько маркеров – уступить конкурентам свой трафик. За это оптимизатор, заказавший ядро, точно не поблагодарит.
Приступаем к сбору маркеров: изучите главное меню на сайтах конкурентов, посмотрите метатеги, анкоры внутренних ссылок, заголовки H. Это основные элементы страниц, которые оптимизируют ключами. Там и стоит искать маркеры.
Просмотрите эти элементы на своём сайте. Важно использовать синонимы, которые подскажет Яндекс.Вордстат или любой онлайн-словарь синонимов.
Как ускорить
Serpstat
Сервис покажет, по каким запросам ранжируются сайты конкурентов, долю запросов, по которым ранжируетесь вы, что было упущено. Дыра в семантике не даёт возможности сайту занять лидирующие позиции. Именно запросы, по которым видны конкуренты, помогут быстро найти нужные маркеры.
Запросы, по которым виден сайт (в том числе и конкурентов), показаны в отчёте «Ключевые фразы». Отсеяв витальные запросы, вы сможете найти ключевые слова для продвижения сайта.
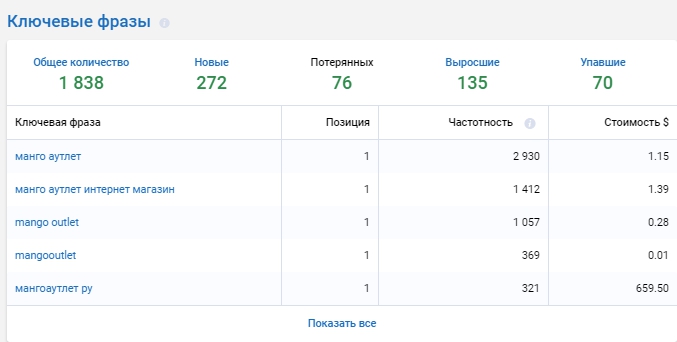
Системы Метрик
Этот метод подходит для поиска запросов, по которым уже были переходы. Он поможет не упустить эти ключевые фразы в новой семантике.
Запросы, по которым уже были переходы, можно просмотреть в GSC. Этот функционал есть в новой версии, отображаются данные за 16 месяцев.
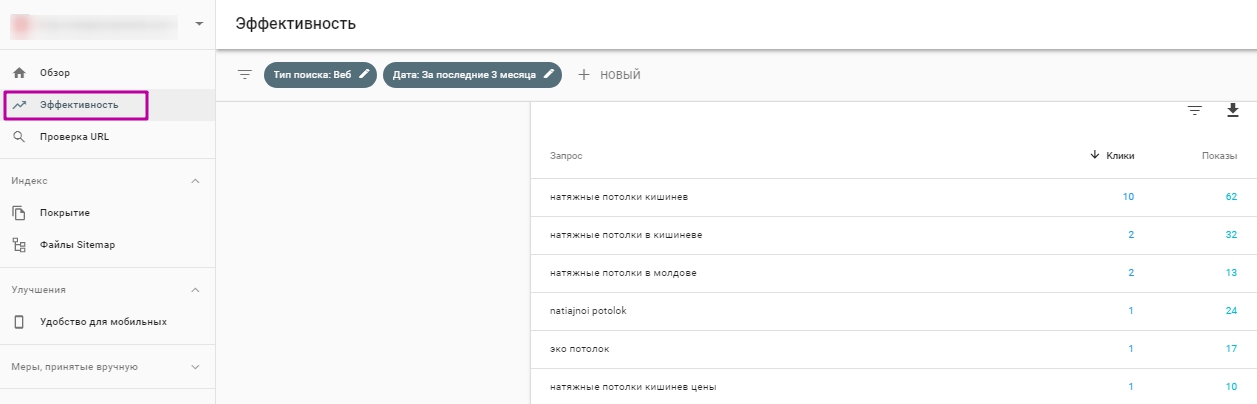
Посмотреть запросы, по которым были переходы на сайт, можно и в Яндекс.Метрике. Для этого переходим в «Отчёты» → «Поисковые запросы».
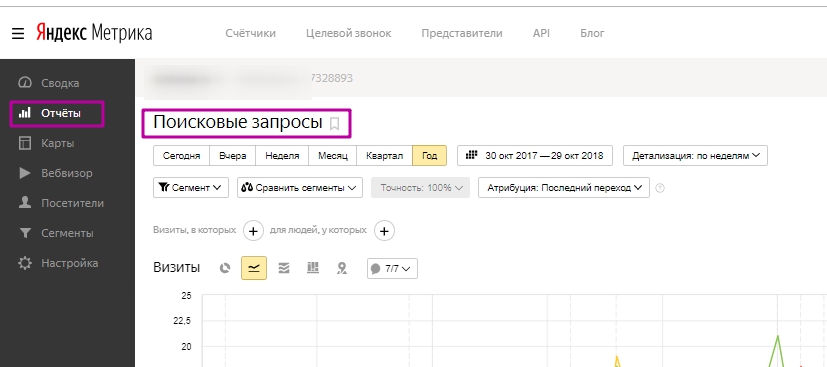
2. Cбор облака запросов
Собрав и утвердив список маркеров, можете приступать к следующему этапу – сбору облака запросов. Не забывайте собирать подсказки – это хороший источник трафика. ПС формируют их из настоящих запросов пользователей.
Сбор левой колонки и подсказок по большому списку маркеров может занять сутки.
Как ускорить
Несколько потоков в Key Collector
Для этого нужно купить дополнительные прокси и зарегистрировать несколько аккаунтов в Яндекс.Директе. Укажите их в пункте «Настройки» → «Yandex.Direct».
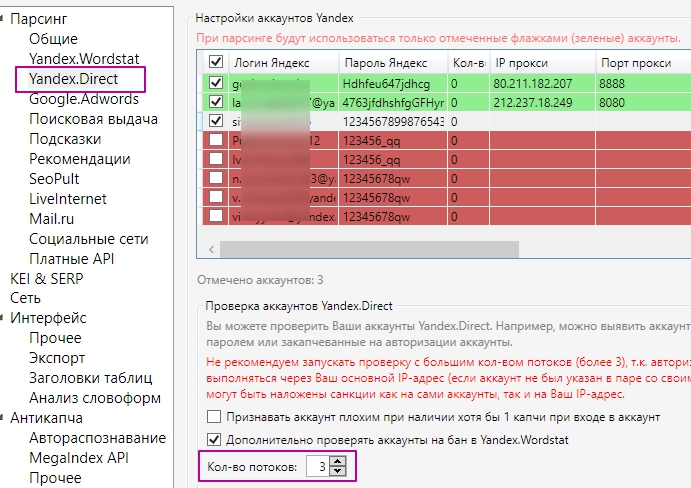
Для каждого аккаунта Яндекса назначьте отдельный прокси (как показано выше). Это нужно, чтобы запросы со всех потоков не производились через один аккаунт.
Разработчики программы не рекомендуют устанавливать более одного потока на один IP. Поэтому суммируем количество прокси и свой основной IP, записываем количество потоков в соответствующее поле.
Подробнее – в справке программы.
Антикапча
Нужна, чтобы не вводить коды проверок вручную. Как минимум сбор будет проходить в фоновом режиме и не потребует вашего внимания.
3. Чистка запросов
Пришло время чистить ядро. Для этого можно найти готовый список стоп-слов по вашей тематике в интернете. Однако его придётся проанализировать, удалить неподходящие фразы. Это можно сделать, перечитав все запросы, или …
Как ускорить
Лемматизатор
Можно выгрузить все слова в онлайн-лемматизатор, вычитать список на предмет мусора и убрать окончания мусорных слов – получим список стоп-слов для этой семантики.
Нужно аккуратно удалять запросы, чтобы не потерять полезные.
«Анализ групп» в Key Collector
Ещё один способ – анализировать готовую семантику прямо в Key Collector.
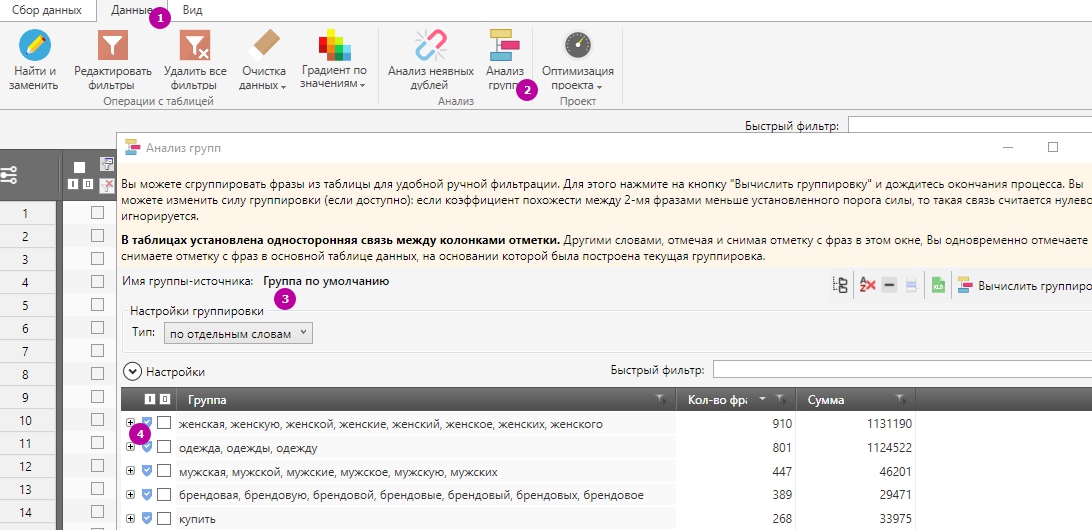
1 – «Данные».
2 – «Анализ групп».
3 – «Настройка группировки» → «По отдельным словам».
4 – Выносим лишнее в стоп-слова.
В этом случае видно, каких слов в ядре больше, какова суммарная частота запросов с ними. Можем сразу добавить их в стоп-слова.
4. Группировка готовой семантики
Группировка ядра или кластеризация (не по ТОПу) – наиболее трудоёмкий этап задачи. Группировка вручную – долгий и мучительный процесс, который в итоге может уступать по качеству.
Как ускорить
Seo-excel
Это надстройка для SEO-специалистов, которая преображает собранное ядро за несколько секунд. Она позволяет группировать семантику по интенту (то есть по намерению пользователя).
Например, есть семантика для сайта женской и мужской брендовой одежды старых коллекций, которая продаётся по скидкам. Нам нужно объединить эти запросы по намерению пользователя. Убираем слова, которые могут встречаться во всех запросах. Для семантики брендовой одежды старых коллекций, которая продаётся по скидкам, это:
- купить;
- цена;
- интернет;
- магазин;
- заказать;
- москва;
- фото;
- стоимость;
- бренд;
- дизайнерская;
- аутлет;
- дискон;
- скидки;
- распродажи.
Эти слова и нужно «выжать» из семантики.
Для этого используем инструмент «Выжимка»:

1, 2 – Создаём два одинаковых столбца с запросами.
3 – Записываем слова, от которых нужно избавиться (без окончаний).
4 – Указываем предлоги, от которых тоже нужно избавиться.
5 – Если оставить все галочки, получим названия кластеров транслитом (на латинице), в инфинитиве и алфавитном порядке.
6 – Колонка с названиями кластеров.
7 – Выполнить.
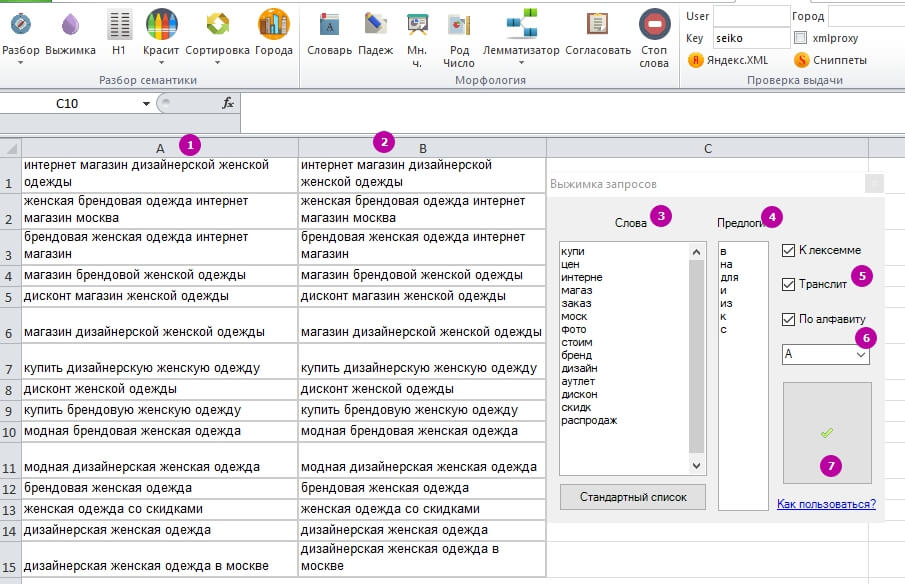
В результате получим колонку A с названиями кластеров и колонку B с запросами.
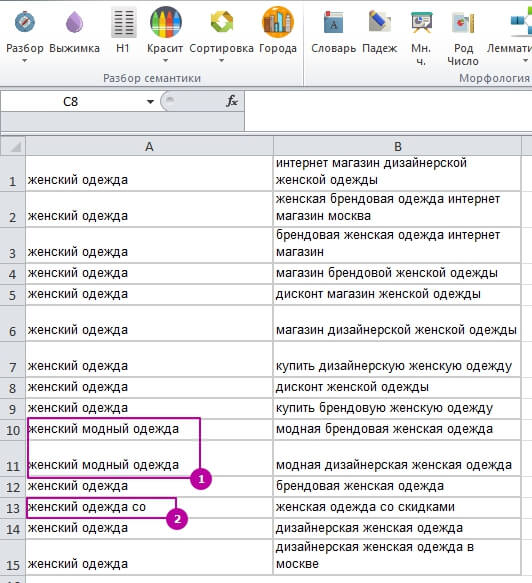
1 – В отдельный кластер вынесено запросы с «модная», так как мы не добавили это слово в список выжимки.
2 – Та же ситуация, только с предлогом «co».
Смотрим, какие ещё есть лишние слова, при необходимости меняем/дополняем список выжимки.
Таким образом, мы получим семантику, разбитую на кластеры.
Для удобства можно покрасить кластеры и отсортировать запросы по частоте (самый частотный кластер будет в начале).
Для этого используем «Красит» и «Сортировка»:
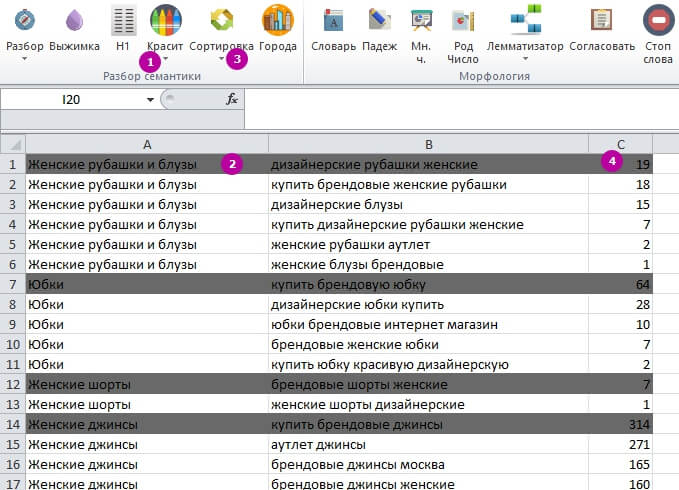
1 – «Красит» → «Красит все столбцы».
2 – Закрашивает всю строку, ориентируясь на кластер в колонке А.
3 – «Сортировка» → «Строки в кластере».
4 – Получаем сортировку запросов в одном кластере по убыванию.
Смотрим, какие кластеры есть, выгружает их отдельным списком с помощью инструмента «Разбор»:
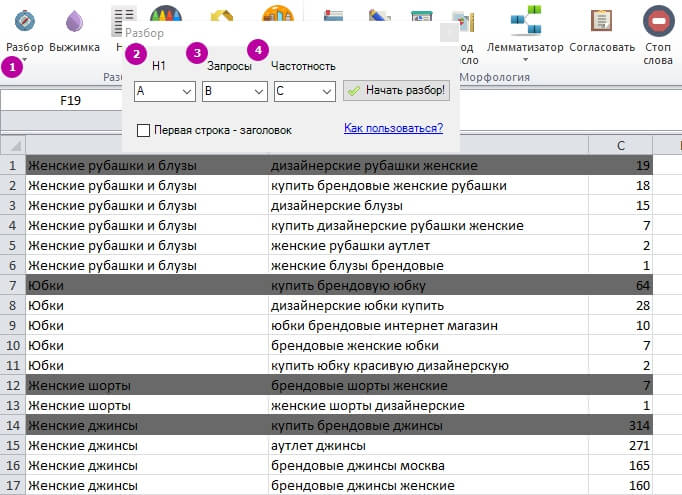
1 – «Разбор» → «Начать разбор».
2 – Указываем колонку с названием кластера.
3 – Указываем, в какой колонке запросы.
4 – Указываем колонку с частотой.
В итоге получаем список кластеров на отдельном листе.
Проверка состояния посадочных страниц
Иногда оптимизатор хочет посмотреть, сколько товаров есть на посадочных страницах по готовому ядру. Ведь ассортимент – один из факторов ранжирования, влияющих на продвижение.
Как это сделать? Ответ очевиден: открывать каждую страницу и считать.
Как ускорить
Счётчик товаров на странице, выгрузка значений в Google Sheets
Если на странице есть счётчик товаров, можно выгрузить их количество в Google Sheets:
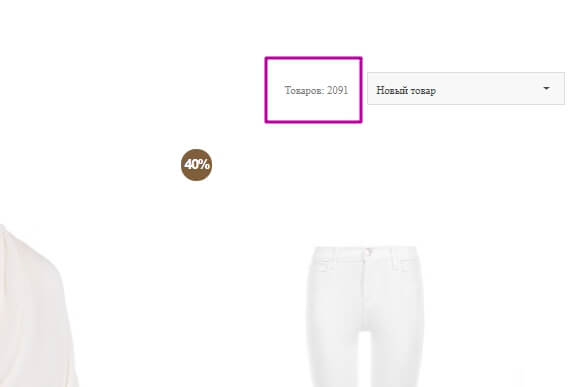
Для этого потребуется формула =IMPORTXML.
В этом случае ищем тег, уникальный для этого счётчика, с помощью языка Xpath прописываем путь к нему:
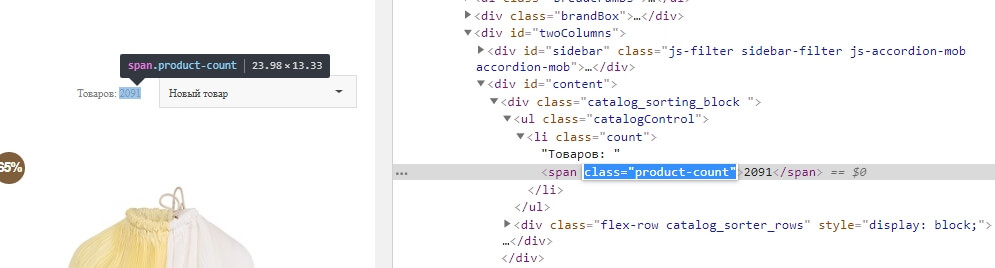
Например, для этого сайта подошла формула:
=IMPORTXML(J488;"//span [@class='product-count']") где через «//» мы прописали относительный путь к тегу и к его классу «product-count»
В итоге получаем данные класса «product-count» в документе:
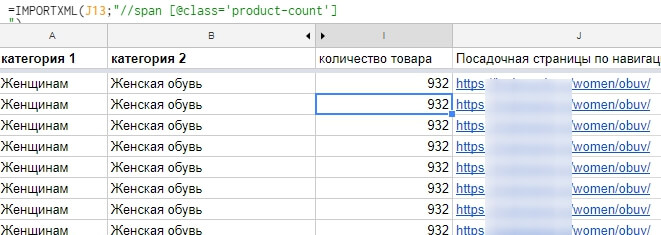
Как пользоваться =IMPORTXML и другими полезными функциями, рассказано в статье «20 возможностей Google Sheets, которые сэкономят время SEO-оптимизатору: функции, плагины, макросы».
Подсчёт количества товаров на странице
Часто на сайте нет счётчика товаров. В этом случае остаётся считать карточки. Это можно сделать по такому же принципу. Выбираем уникальный идентификатор для карточки товара (в нашем случае это itemName), добавляем его в формулу, считаем количество таких идентификаторов на странице через =COUNTA или =СЧЁТЗ.
=СЧЁТЗ(IMPORTXML(E49;"//span[@class='itemName']"))
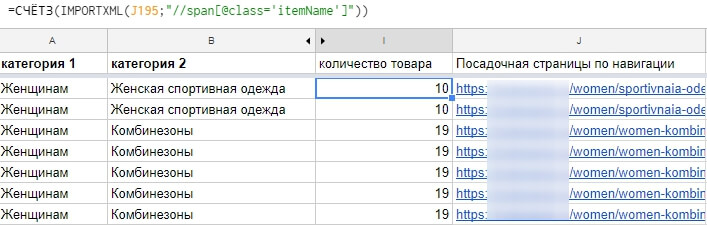
Важно! Учитывайте пагинацию и блоки рекомендованных товаров. Формула считает количество идентификаторов только на указанной странице (первой в пагинации). Если в категории слишком много товаров, которые разбросаны на 2, 3, 4 и т. д. страницах, умножьте полученное число на количество страниц пагинации. Учитывайте, что в категории могут выводиться блоки «Вы смотрели» и «Рекомендованные товары». Формула их тоже посчитает.
Проверка индексации
Продвигаемые страницы как минимум должны быть в индексе. Как известно, самый верный способ узнать, в индексе страница или нет, – проверить её сохранённую копию в ПС.
Вручную проверять каждую страницу – долго, особенно для больших сайтов. Формулы помогут вывести дату последней сохранённой копии страницы в Google Sheets.
Формула, указанная ниже, выгружает дату сохранённой копии страницы:
=IMPORTXML(
СЦЕПИТЬ("http://webcache.googleusercontent.com/search?q=cache:";J194);
"//div[@id='bN015htcoyT__google-cache-hdr']/div"
)
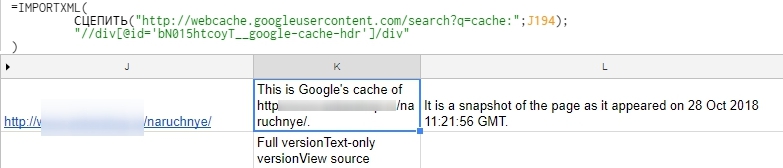
http://webcache.googleusercontent.com/search?q=cache – универсальный адрес кэша Googlе.
J194 – номер ячейки, в которой хранится анализируемый URL.
<div id=»bN015htcoyT__google-cache-hdr»> – уникальный идентификатор блока с датой на странице сохранённой копии.
Информация о дате выгружается в несколько ячеек. В нашем примере нужные данные находятся в колонке L.
Xpath вместе с =IMPORTXML не раз помогут быстро решить задачи, поэтому будет полезным ориентироваться в их синтаксисе.
Если не понимаете, почему ваш xpath-запрос не работает, проверьте его через онлайн-интерпретатор. Один из них – http://www.xpathtester.com/xpath/.
Создание метатегов
Часто джунам ставят задачу прописать метаданные для посадочных страниц. В идеале нужно внимательно прописывать уникальные метатеги для каждой страницы, однако если их несколько сотен, рекомендуем использовать хитрости.
Как ускорить
Использовать формулы
Например, =СЦЕПИТЬ поможет объединить шаблонные блоки метаданных. Создайте удачный шаблон, в котором прописаны нужные ключевые слова и спецсимволы. Как и для чего добавлять спецсимволы в Description, можно узнать в статье «Как использовать спецсимволы в Title и Description для привлечения пользователей из выдачи».
Плагин Seo-Exсel
Он предусматривает несколько шаблонов для создания Title и Description. Вся прелесть в том, что Seo-Exсel учитывает частоту запросов и вложенность всех запросов из кластера в один запрос (частотность Климова).
Плагин предлагает несколько вариантов шаблонов для Title.
Title «C разделителем»
Для этого используем семантику, разбитую на кластеры.
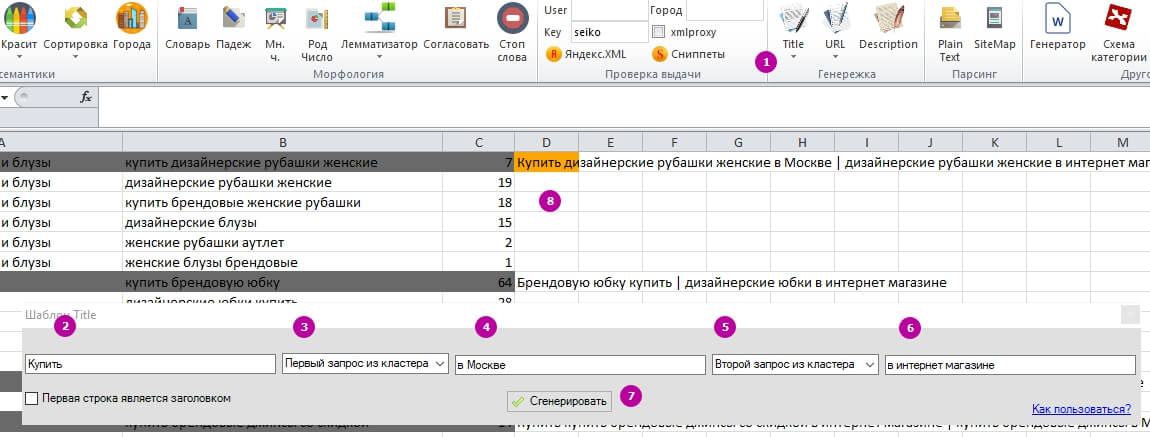
1 – Выбираем инструмент «С разделителем».
2, 4, 6 – Формируем паттерн, оставляем слова по умолчанию или записываем свой вариант.
3, 5 – Плагин указывает, какие слова из кластера он возьмёт, поэтому важно применять сортировку запросов по частоте внутри кластера.
7 – Формируем Title.
8 – Проверяем результат.
Более подробные инструкции с видео есть на сайте http://seo-excel.ru/title/.
Особая ценность этого шаблона – он удаляет дубли. Если в первых двух запросах есть «купить», плагин оставит только один. То есть, «Купить купить брендовую юбку в Москве | дизайнерские юбки купить в интернет-магазине» не будет.
Title «Скользящий»
Это второй шаблон для Title. Он также удаляет дубли слов в запросах и предлагает более широкий функционал.
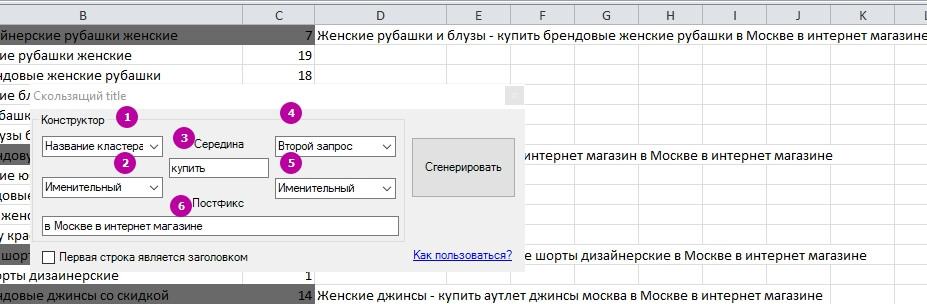
1, 4 – Выберите, какой запрос из кластера будет первым, или используйте название кластера.
2, 5 – Задайте падеж слов в запросе.
3, 6 – Задайте слова для средины и конца Title или оставьте по умолчанию.
Частотность Климова
Частотность Климова – алгоритм для расчёта «удачности» запроса. Он рассчитывает, какой запрос содержит наибольшее количество других запросов и их частот. Для расчёта лучше использовать запросы с частотой «[!]» (она учитывает и порядок слов в запросе).
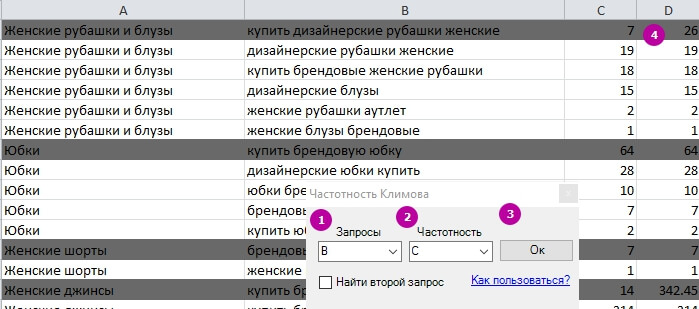
1 – Указываем, в какой колонке находятся запросы.
2 – Колонка с частотами.
3 – Нажимаем «Ок».
4 – Получаем расчёт частотности.
Подробнее об алгоритме в справке.
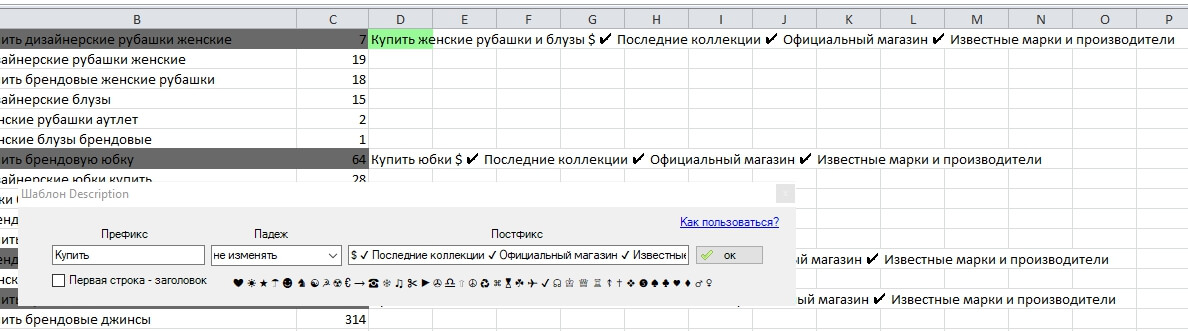
Шаблон для генерации Description
Шаблон для формирования Description не такой богатый, однако можно задать префикс и постфикс со спецсимволами, а также выбрать падеж для склонения названия кластера.
Технический аудит
Работа с парсером
Любой технический аудит начинается с парсинга. Для аудитов больших сайтов вам, скорее всего, может понадобиться сканирование отдельных карточек товаров или категорий.
Например, нужно сканировать URL категории женских товаров. Они находятся в папке /women/:
Как ускорить
Сканировать отдельную категорию, выделив её регулярным выражением
Для этого удобнее всего использовать популярные парсеры и выделять категории специальными выражениями.
Ознакомиться с популярными парсерами и найти лучший для себя можно в статье «Обзор ТОП-6 парсеров сайтов».
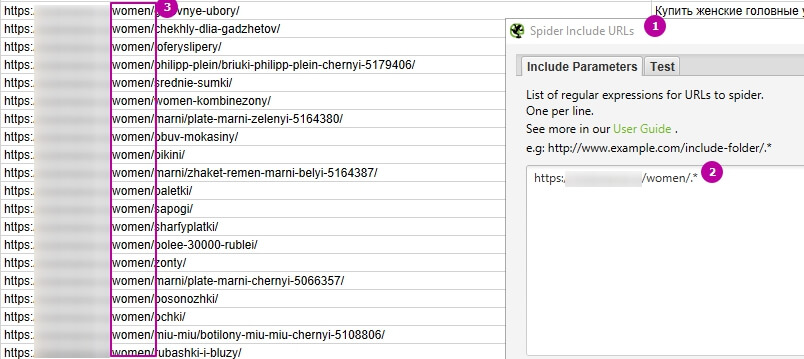
Например, перед сканированием в Screaming Frog нужно указать, какая категория нужна, в «Configuration» → «Include».
1 – «Configuration» → «Include».
2 – Простым регулярным выражением выделяем, какие URL нужно сканировать.
3 – После запуска сканирования с учётом указанных правил получим список адресов с любым содержанием после /women/.
Может пригодиться обратная функция «Configuration» → «Exclude» – исключение определённой категории при сканировании: «Configuration» → «Exclude».
Работа с Google Analytics
Во время технического аудита может понадобиться информация о страницах с Get-параметрами определённой категории. Чтобы понять, закрывать их от роботов или нет, нужно оценить трафик, который они собирают.
В этом случае нам понадобится GA и его поддержка регулярных выражений. Страницы с Get-параметрами обычно отличаются от других URL наличием «?» в адресе. Например, нас интересуют адреса такого типа: https://www.site.ru/org-biz/?cur_cc=250.
Их поможет найти формула «org-biz\/.*\?»
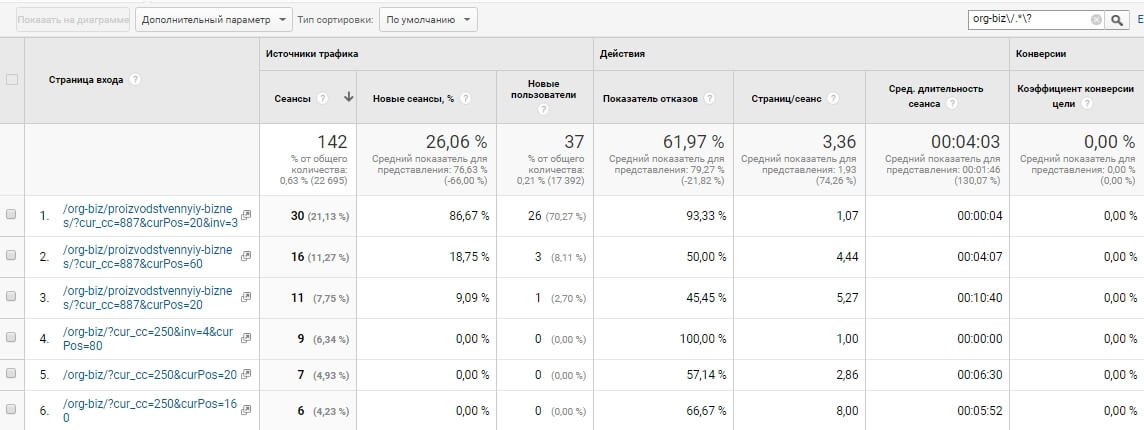
Разбираем формулу:
org-biz – категория, страницы которой нам нужны;
\/ – экранированный метасимвол «/»;
\? – экранированный метасимвол «?»;
*. – последовательность любых символов «*».
Подробнее о синтаксисе можно узнать здесь: https://support.google.com/analytics/answer/1034324?hl=ru.
Проверить правописание формулы можно с помощью https://regex101.com/.
Итог
Мир не стоит на месте и, скорее всего, уже придуманы инструменты, которые могут решить вашу задачу, даже если она кажется слишком простой, чтобы кто-то писал специальный функционал, да ещё и бесплатно. Однако стоит попробовать найти то, что сэкономит время.
В сети есть сравнитель двух текстов, конвертер формата изображений, который за несколько секунд превратит список столбцом в строчный список, разделённый запятой. Чтобы ускорить работу, достаточно всего лишь сформулировать потребность и добавить «онлайн» в поисковой строке.
Еще по теме:
- Как проверить является ли домен восстановленным дропом и узнать примерную цену выкупа? 1️⃣ Как, кроме WebArchive, проверить, что домен действительно является восстановленным дропом? Какие инструменты или сервисы вы используете для такой проверки? 2️⃣ Где можно посмотреть цену,...
- Как спрятать свои бэклинки от парсеров, чтобы конкуренты не видели сайты-доноры? Подскажите, пожалуйста, как свои бэклинки спрятать от ботов всяких там парсеров бэклинков, чтобы конкуренты не спалили мои сайты, с которых я ставлю ссылочки. Ответ Это...
- Руководство по установке и настройке Google Tag Manager для новичков Предлагаем вашему вниманию пошаговую инструкцию по установке и настройке Google Tag Manager (GTM). Здесь же мы расскажем, как с помощью GTM подключить Google Analytics и...
- Word Keeper vs Key Collector Скорость сбора фраз Количество фраз Скорость сбора частот Точность Гибкость настроек Цена Итог Для большинства SEO-специалистов Key Collector является основным инструментом по сбору семантики. Отличную...
- Каким сервисом можно отслеживать домены, которые могут выпасть в дроп? Подскажите сервис, чтобы отслеживать домены, которые могут выпасть в дроп — чтобы добавить их туда и просто ждать уведомления, когда идти смотреть. Ответ Самый популярный...

Оцените мою статью:
 (23 оценок, среднее: 5,00 из 5)
(23 оценок, среднее: 5,00 из 5)Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.

Спасибо, полезно!
Спасибо, Ольга!
Их поможет найти формула «org-biz/.*?»
*. – последовательность любых символов «*»
последовательность роли не играет?
В нашем случае последовательность не важна. При помощи «.*» мы указываем, что в искомых URL, кроме «?», должны быть любые другие символы.
Спасибо!