
- Андрей М.
- 7 минут
- Мануал

- Что такое индексация сайта
- Что следует закрывать на сайте
- Какие данные закрывать не стоит
- Как закрывать от индексации контент, страницу или весь сайт
- Инструменты удаления страниц из индекса
- Подводя итог
Что такое индексация сайта
Индексация – это процесс сканирования сайта поисковыми роботами и внесение полученной информации в базу данных поисковика. Для получения статуса проиндексированного ресурсу необходимо, чтобы на него зашёл поисковый бот. Такие боты заносят в систему информацию и о сайте, и обо всех его страницах, и о материалах (видео, тексты, картинки), доступных для поиска.
В интересах владельца сайта, чтобы его целевая аудитория могла быстро найти конкретный веб-ресурс в выдаче. Цель же поисковой системы – предоставление пользователю ценной и релевантной информации. А значит, чтобы выполнялись и цели владельца сайта, и цели поисковика, стоит позаботиться о корректной индексации. А для этого открываются только те данные, которые будут полезны и уместны в результатах поиска.
Причины, по которым запрещается сканирование страницы или отдельной информации на ней:
- для обеспечения уникальности – важно, чтобы информация, считываемая поисковыми ботами, была неповторима и полезна, это повышает позицию сайта в выдаче;
- для экономии краулингового бюджета – чтобы не тратить его на ненужную информацию, второстепенные данные лучше скрыть.
В то же время важно убедиться, что страницы с уникальной, важной и полезной для пользователя информацией открыты для индексации.
Что следует закрывать на сайте
Скрыть от поискового бота можно как часть контента, так и полную информацию на странице или весь сайт. Разберёмся, какие из данных можно закрыть:
- Размещённый контент.
- Страницы.
- Весь сайт.
Рассмотрим коротко каждый из пунктов.
Размещённый контент
Нередко данные, размещаемые на сайте, дублируются на разных страницах. Например, это может быть дополнительное меню или блок текста, или ссылка на другие ресурсы. Иногда для оптимизации сайта такую информацию стоит закрыть от поисковиков, но делать это мы рекомендуем только в исключительных случаях либо не делать вовсе.
Страницы
Здесь подразумеваются страницы разного типа. В перечень таковых включаются:
- дубли – даже если контент листингов товара интернет-магазина уникален, одни и те же страницы могут быть сформированы в нескольких вариантах, например, при работе с фильтрами и сортировками;
- страницы для оформления заявки, заказа, корзина или список желаний пользователей, а также страницы аккаунта пользователя – не несут смысловой нагрузки для поисковика, засоряя систему;
- страницы с результатами поисков непосредственно на сайте, сюда же относятся результаты сравнения цен и характеристик (если такая опция присутствует);
- генерируемые страницы с utm-метками, например, из Яндекс.Справочника;
- страницы печати, если они являются копией основной версии.
Весь сайт
Например, если ресурс находится в процессе разработки, лучше скрыть его на этапе создания и наполнения, чтобы в поисковую базу не попала некорректная информация о сайте.
Какие данные закрывать не стоит
Увлёкшись закрытием информации, владельцы сайтов нередко «перегибают палку». Так, есть ряд данных, сокрытие которых может больше навредить, чем принести пользу в поисковой выдаче. К таковым относятся:
- Шапка сайта на странице – содержит важную информацию о компании и её работе.
- Меню и дополнительные возможности: сортировка, фильтры, строка поиска. Эти опции показывают, насколько проработан и комфортен для пользователей ресурс.
- Информация о способах оплаты и наличии доставки также указывают на заботу о клиентах, а потому не должны прятаться от поискового бота.
Другими словами, надо тщательно рассмотреть вопрос распределения открытых и скрытых от индексации страниц. Разобравшись с этим, переходим к инструментам для выполнения задачи.
Как закрывать от индексации контент, страницу или весь сайт
Обсудим набор инструментов для корректного закрытия данных сайта от поискового бота. К ним относятся:
- файл настроек robots.txt;
- применение тегов и метатегов Robots;
- конфигурационный файл .htaccess;
- с помощью JavaScript.
Рассмотрим, как работать с каждым из них.
Файл robots.txt
Robots.txt представляет собой служебный файл текстового типа, содержащий набор рекомендаций для работы ботов-поисковиков. Расположен в корневой папке сайта и именно с него начинается изучение ресурса поисковой системой. В документ включён перечень директив, за счёт которых ограничивается доступность определённых частей сайта для роботов.
Так, добавив к тегу Disallow наименование раздела или папки, получится закрыть их от сканирования. Подробнее о настройке файла robots.txt можно прочитать здесь.
Пример:
Disallow: /название папки/ Disallow: /название раздела/
При этом важно проверить отсутствие внешних ссылок, ведущих к этому участку сайта.
Способ отличается удобством, скоростью выполнения и простотой применения. Но использование только этого инструмента не гарантирует отсутствия индексирования по выбранным страницам.
Применение тега Noindex и метатега Robots
Метатег Robots используется для задания детальных настроек на уровне страницы. От такой настройки зависит и индексация страницы, и её отображение в результатах поиска. В разделе < head > страницы следует размещать метатег robots.

Тегом noindex запрещается демонстрация поисковиками страницы в результатах поиска. Значение robots, задаваемое для атрибута name, говорит о том, что директива касается каждого поискового робота. Если нужно закрыть доступ только одному из ботов, вместо robots указывается другое значение атрибута name – наименование определённого робота.
Отдельных поисковых ботов также называют агентами пользователя (роботом используется агент пользователя при запросе страницы). Для примера: агентом пользователя стандартного поискового робота Google называется Googlebot. Запрет сканирования страницы только им оформляется изменением тега таким образом:
<meta name="googlebot" content="noindex"/>
Этот инструмент почти со 100% гарантией выполняет поставленную задачу.
Тег noindex используют также в HTML-коде страницы для закрытия части контента страницы от индексации. Однако тег не гарантирует того, что контент не будет проиндексирован.
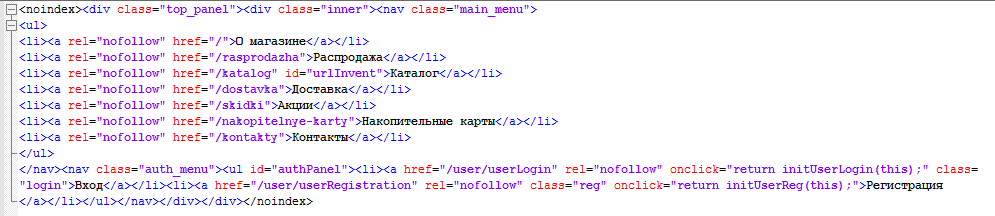
Можно также использовать JavaScript для этой цели, так как тег noindex игнорируется ботами Google (он распознается только Яндексом). При использовании данного метода текст, блок, код, ссылка или любой другой контент кодируется в Javascript, а далее скрипт закрывается от индексации при помощи Robots.txt. Но следует помнить, поисковики настаивают на том, чтобы информация для пользователей и для роботов была идентичной.
Конфигурационный файл .htaccess
В файле, ответственном за дополнительную конфигурацию, .htaccess можно установить ограничения на права доступа к разделам ресурса при помощи пароля. Причём в документе .htpasswd отдельно вводится перечень пользователей, которые имеют допуск к закрытой информации. А путь к документу .htpasswd указывается в .htaccess при помощи специального кода.

Таким способом полностью закрывается доступ поисковикам к контенту сайта. Однако наличие пароля делает сайт труднодоступным для сканирования на наличие ошибок. Это происходит из-за того, что не у всех сервисов проверки есть опция ввода пароля.
С помощью JavaScript
Например с помощью скрипта Ajax можно не столько скрывать дублирующие и «мусорные» страницы, сколько исключить сам факт их создания. То есть содержание страницы меняется без изменения в URL, даже когда пользователь вводит при помощи фильтра определённые параметры товаров интернет-магазина.
Разберём на примере. Вот страница без фильтра:
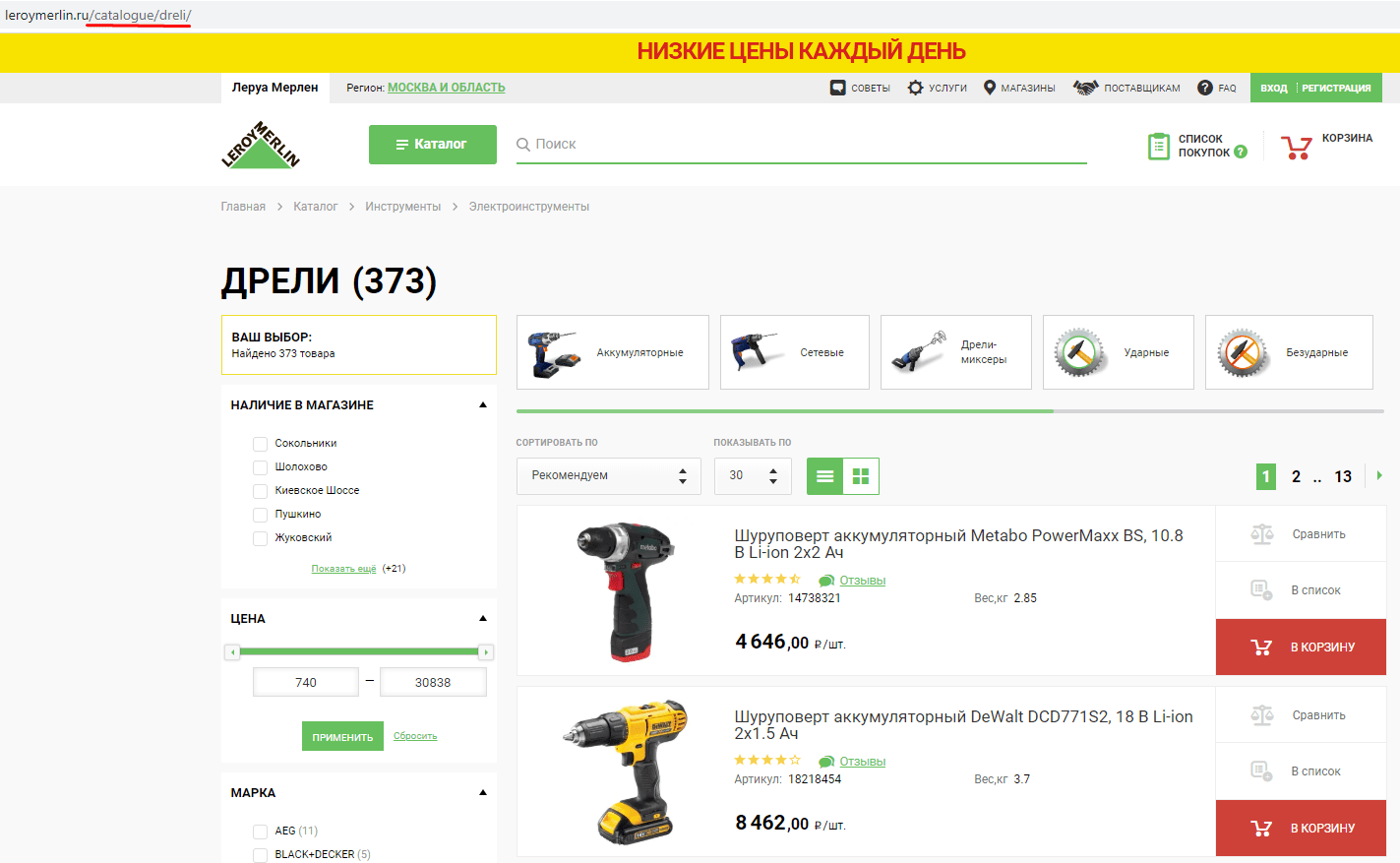
Вот та же страница с выбранным фильтром:
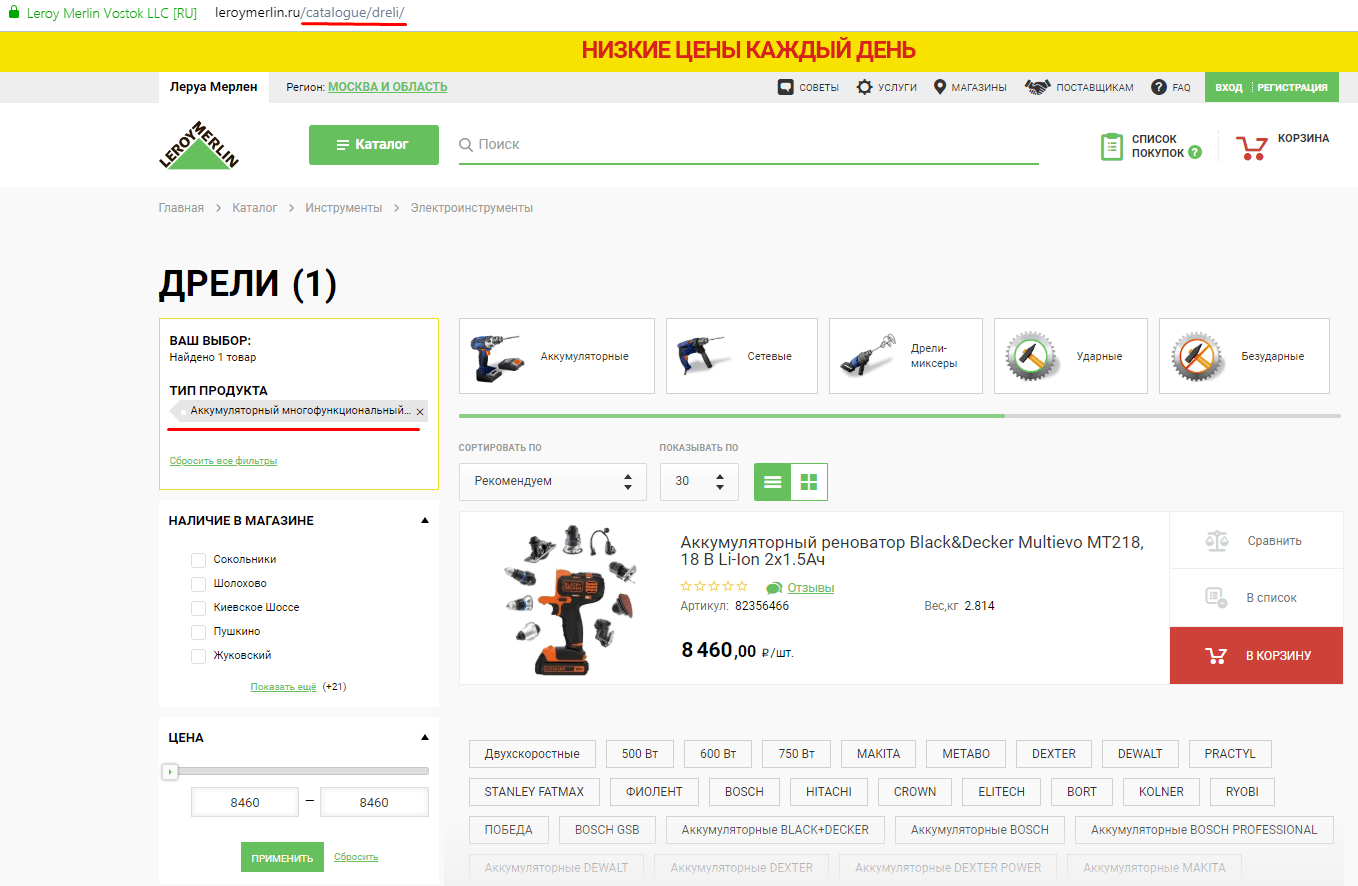
Как видим, в последнем примере были выбраны фильтры, подгружены товары, однако URL страницы не поменялся.
Метод эффективный, но трудоёмкий. К тому же его не получится применить ко всем параметрам сайта, которые необходимо скрыть от индексации.
Инструменты удаления страниц из индекса
Иногда «ненужным страницам» всё же удаётся обойти запреты и попасть в индекс. Их оперативное устранение улучшит положение сайта в рейтинге поисковой системы.
Это актуально как для Google, так и для Яндекса.
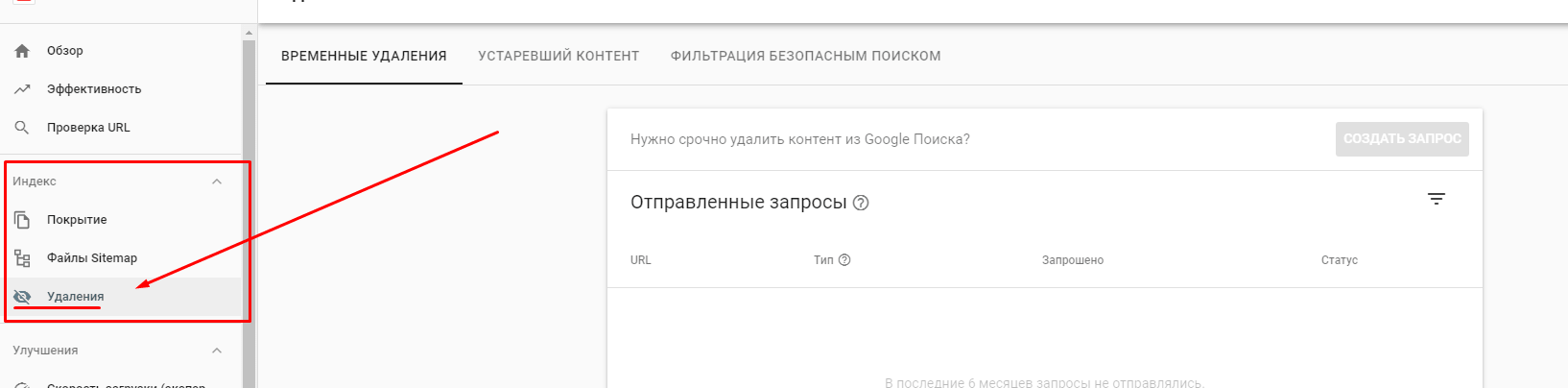
При помощи опций Google Search Console устраняются страницы из списка поисковой выдачи. Для этого вводится URL раздела в специальную форму сервиса, а также указывается причина, по которой его нужно удалить. Найти эту функцию можно в разделе «Индекс». Стоит понимать, что процесс обработки запроса займёт определённое время.
Яндекс.Вебмастер также предлагает исключения страниц: по URL и по префиксу. Найти эти способы можно в разделе «Инструменты».
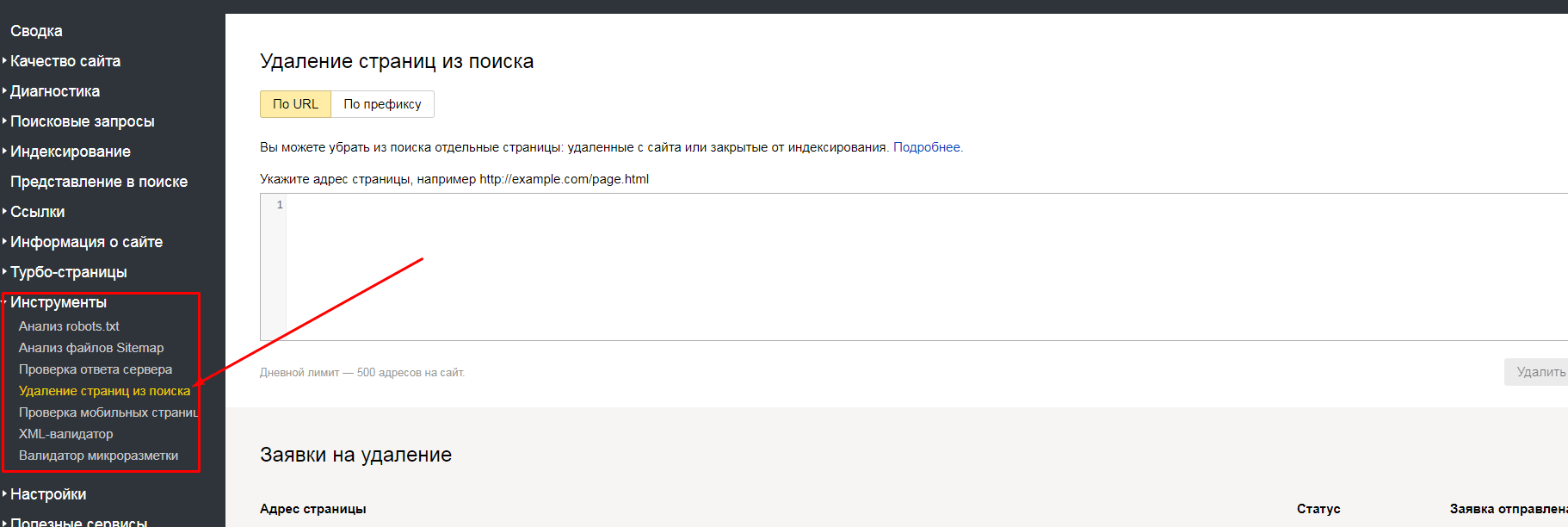
Применение методики «удаление по URL» подразумевает под собой указание в специальном окне Вебмастера списка страничек, помеченных на удаление. Если же выбран формат удаления «по префиксу», появляется возможность для закрытия всех страниц, относящихся к определённому подразделу сайта. Метод актуален для страниц, содержащих выбранный параметр.
Разберём пример: для оптимизации ресурса https://site.ru удалению должны подвергнуться все странички, относящиеся к разделу catalogue. Чтобы это обеспечить, в Яндекс.Вебмастере открывается вкладка по префиксу и указывается УРЛ https://site.ru/catalogue/. Всё: каждая из страниц, относящихся к подразделу, будет удалена из индекса.
Подводя итог
Ситуации, когда нужно закрыть элементы сайта от индексации, случаются часто. Важность закрытия некоторых частей сайта от индексирования поисковиками неоспорима. Ведь за счёт ограничения доступов к некоторым страницам и документам происходит экономия ресурсов поисковых систем и ускорение индексации ресурса. При этом стоит подойти к удалению страниц из поля зрения ботов-поисковиков с умом. Ведь некорректно проведённая работа принесёт вред позициям ресурса в поисковой выдаче.
Возникли проблемы с индексацией сайта — обращайтесь к нам!
Еще по теме:
- Насколько важный фактор для SEO соответствие верстки сайта стандартам w3c? Насколько важный фактор для SEO соответствие верстки сайта стандартам w3c? Ответ Соответствие верстки сайта стандартам w3c не является прямым фактором ранжирования, но косвенно действительно может...
- Да будет SEO: 4 плагина для оптимизации сайта на WordPress Рассмотрим SEO-плагины для CMS Wordpress, которые позволяют провести внутреннюю оптимизацию сайта. О некоторых плагинах я уже писала ранее. У плагинов, о которых расскажу в этой...
- Как сделать редизайн и переезд сайта без потерь позиций и трафика Вступление Делая редизайн сайта, вы, конечно же, надеетесь на улучшение позиций, трафика. Вряд ли кто-то рассчитывает увидеть после доработок такой график: На практике ситуация с...
- Зеркала сайта и объединение доменов Что такое зеркало сайта Зачем нужны зеркала Как определить зеркала сайта Как указать главное зеркало Как расклеить домены Мини-кейсы от Siteclinic 1. Как быстро восстановить...
- Вы не любите Joomla!? Вы просто не умеете ее готовить Продолжим серию обзоров популярных CMS и поговорим о Joomla: в чем её преимущества и с чем вам придется познакомиться, работая с этой CMS. Мы постарались...

Оцените мою статью:

 (7 оценок, среднее: 4,43 из 5)
(7 оценок, среднее: 4,43 из 5)Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.

Кажется, инструмент удаления у гугла не совсем для этих целей предназначен. Т.к. спустя какое-то время страницы могут вернуться обратно.
Инструмент удаления URL в GSC позволяет скрыть страницу примерно на полгода. Для полного удаления необходимы меры, в том числе и описанные в статье (например запретить сканирование контента метатегом noindex). Подробнее можно почитать в справке Google тут .
Нужно ли закрывать страницы пагинации блога? Общую пагинацию/пагинацию в рубриках?
Друзья подскажите. На сколько критично сейчас оставлять открытым облако меток?