
- (Обновлено: ) Ксения П.
- 8 минут

В этой статье мы рассмотрим:
- Что такое robots.txt?
- Все директивы файла:
- Использование спецсимволов
- Как проверить корректную работу файла
- Часто допускаемые ошибки
- Примеры robots.txt для различных CMS:
Что такое robots.txt?
Robots.txt — это текстовый файл, который содержит в себе рекомендации для действий поисковых роботов. В этом файле находятся инструкции (директивы), с помощью которых можно ограничить доступ поисковых роботов к определённым папкам, страницам и файлам, задать скорость сканирования сайта, указать главное зеркало или адрес карты сайта.
Обход сайта поисковыми роботами начинается с поиска файла роботс. Отсутствие файла не является критической ошибкой. В таком случае роботы считают, что ограничений для них нет и они полностью могут сканировать сайт.
Файл должен быть размещён в корневом каталоге сайта и быть доступен по адресу https://mysite.com/robots.txt.
Инструкции стандарта исключения для роботов носят рекомендательный характер, а не являются прямыми командами для роботов. То есть существует вероятность, что даже закрыв страницу в robots.txt, она всё равно попадёт в индекс.
Указывать директивы в файле нужно только латиницей, использовать кириллицу запрещено. Русские доменные имена можно преобразовать с помощью кодировки Punycode.

Что нужно закрыть от индексации в robots.txt?
- страницы с личной информацией пользователей;
- корзину и сравнение товаров;
- переписку пользователей;
- административную часть сайта;
- скрипты.
Как создать robots.txt?
Составить файл можно в любом текстовом редакторе (блокнот, TextEdit и др.). Можно создать файл robots.txt для сайта онлайн, воспользовавшись генератором файла, например, инструментом сервиса Seolib.
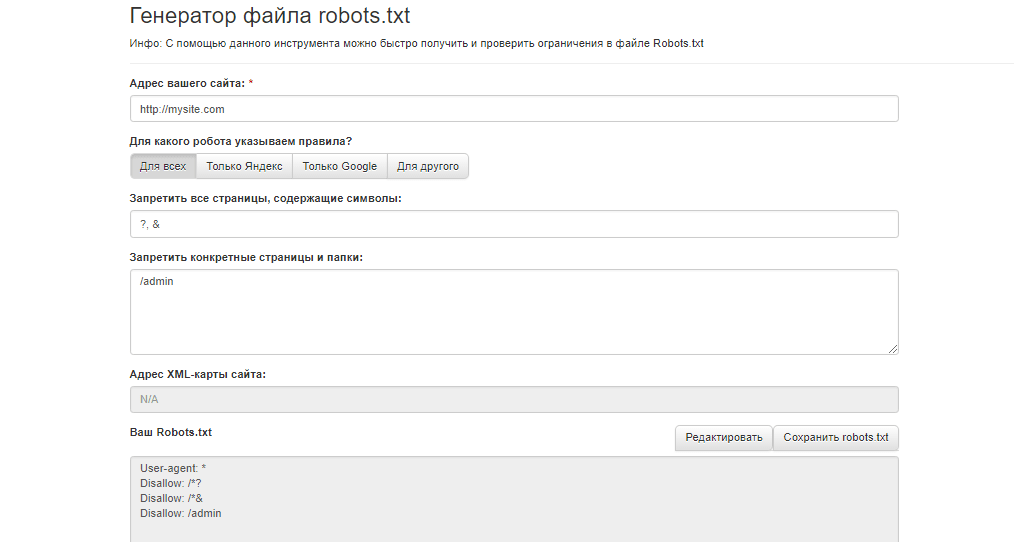
Нужен ли robots.txt?
Прописав правильные инструкции, боты не будут тратить краулинговый бюджет (количество URL, которое может обойти поисковый робот за один обход) на сканирование бесполезных страниц, а проиндексируют только нужные для поиска страницы. В дополнение, не будет перегружаться работа сервера.
Директивы robots.txt
Файл роботс состоит из основных директив: User-agent и Disallow и дополнительных: Allow, Sitemap, Host, Crawl-delay, Clean-param. Ниже мы разберём все правила, для чего они нужны и как их правильно прописать.
User-agent — приветствие с роботом
Существует множество роботов, которые могут сканировать сайт. Наиболее популярными являются боты поисковых систем Google и Яндекса.
Роботы Google:
- Googlebot;
- Googlebot-Video;
- Googlebot-News;
- Googlebot-Image.
Роботы Яндекса:
- YandexBot;
- YandexDirect;
- YandexDirectDyn;
- YandexMedia;
- YandexImages;
- YaDirectFetcher;
- YandexBlogs;
- YandexNews;
- YandexPagechecker;
- YandexMetrika;
- YandexMarket;
- YandexCalendar.
В директиве User-agent указывают, к какому роботу обращены инструкции.
Для обращения ко всем роботам достаточно прописать следующую строку в файле:

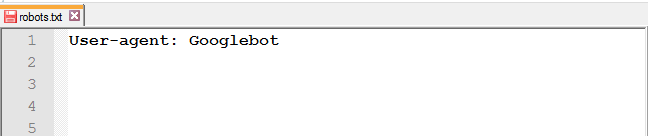
Для обращения к определённому роботу, например, к Google, нужно прописать в этой строке его имя:
В отличие от Google, дабы не прописывать правила для каждого робота Яндекса, в User-agent можно указать следующее:
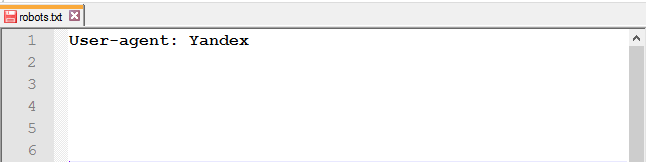
В Рунете принято прописывать инструкции для двух User-agent: для всех и отдельно для Яндекса.
Директивы Disallow и Allow
Чтобы запретить роботу доступ к сайту, каталогу или странице, используйте Disallow.
Как применять правило Disallow в различных ситуациях
Закрыть от индексации весь сайт: используйте слеш (/), чтобы заблокировать доступ ко всему сайту.
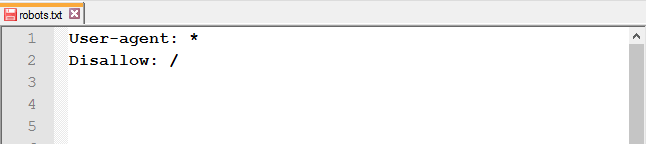
Полностью закрывать доступ роботам стоит на ранних этапах работы с сайтом, чтобы в поисковой выдачи он появился уже готовым.
Закрыть доступ к папке и её содержимому: используйте слеш после названия папки.
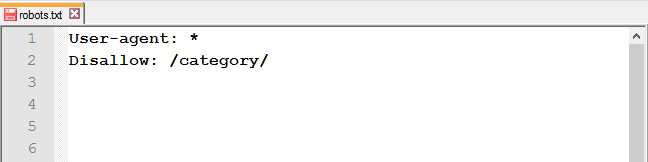
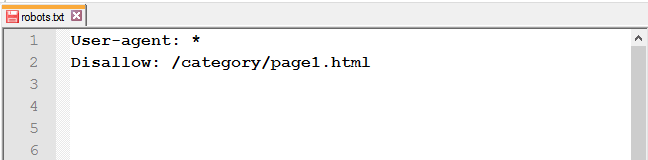
Закрыть определённую страницу или файл: укажите URL без хоста.
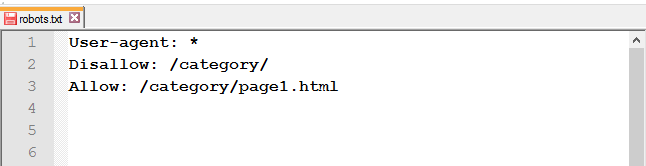
Открыть доступ к странице из закрытой папки: после Disallow используйте правило Allow.
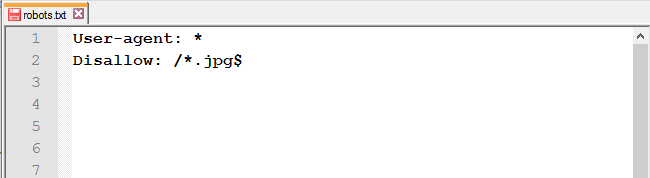
Запретить доступ к файлам одного типа: чтобы запретить к обходу однотипные файлы, воспользуйтесь специальными символами * и $.
Адрес Sitemap в robots.txt
Если на сайте есть файл Sitemap, укажите в соответствующей директиве адрес к нему. Если же карт сайта несколько, пропишите все.

Это правило учитывается роботами независимо от его месторасположения.
Директива Host для Яндекса
UPD: 20 марта Яндекс официально объявил об отмене директивы Host. Подробнее об этом можно прочитать в блоге Яндекса для вебмастеров.Что теперь делать с директивой Host:
- удалить из robots.txt;
- оставить — робот будет игнорировать её.
В обоих случаях нужно настроить 301 редирект.
Роботы Яндекса поддерживают robots.txt с расширенными возможностями. Инструкция Host является одной из них. Она указывает главное зеркало сайта.
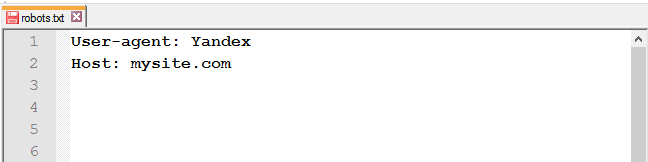
Важно:
- 1. использовать www (если так начинается адрес сайта);
- 2. использовать HTTPS (если сайт на защищённом протоколе, если нет — HTTP можно не прописывать).
Как и с Sitemap, месторасположение правила не влияет на работу робота, оно может быть указано как в начале файла, так и в конце.
Некорректно прописанная директива Host игнорируется роботом.
Crawl-delay
UPD: ПС Яндекс также отказалась от учёта Crawl-delay. Подробнее в блоге Яндекса для вебмастеров.
Вместо директивы Crawl-delay можно настроить скорость обхода в Яндекс.Вебмастере.
Директива Crawl-delay указывает время, которое роботы должны выдерживать между загрузкой двух страниц. Эта инструкция значительно снизит нагрузку на сервер, если у него есть проблемы с обработкой запросов.
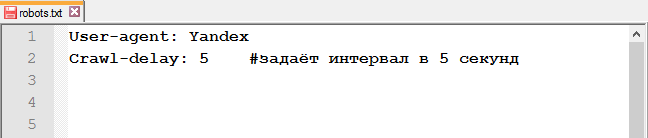
Строка с Crawl-delay должна находиться после всех директив с Allow и Disallow.
Так как Google это правило не учитывает, для гуглбота есть другой метод изменения скорости сканирования.
Clean-param
Для исключения страниц сайта, которые содержат динамические (GET) параметры (например, сортировка товара или идентификаторы сессий), используйте директиву Clean-param.
Например, есть следующие страницы:
https://mysite.com/shop/all/good1?partner_fid=3
https://mysite.com/shop/all/good1?partner_fid=4
https://mysite.com/shop/all/good1?partner_fid=1
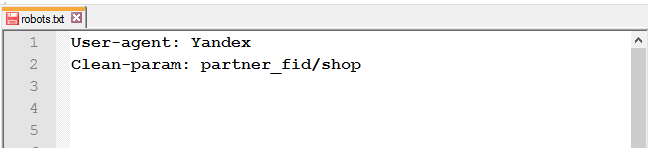
Используя данные из Clean-param, робот не будет перезагружать дублирующуюся информацию.
Спецсимволы $, *, /, #
Спецсимвол * (звёздочка) означает любую последовательность символов. То есть, используя звёздочку, вы запретите доступ ко всем URL, содержащим слово «obmanki».

Этот спецсимвол проставляется по умолчанию в конце каждой строки.

Чтобы отменить *, в конце правила нужно указать спецсимвол $ (знак доллара).

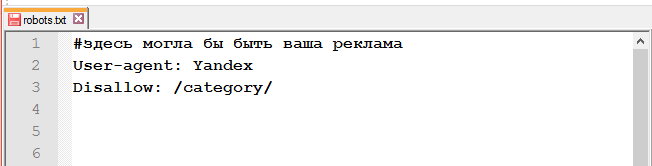
Спецсимвол / (слеш) используется в каждой директиве Allow и Disallow. С помощью слеша можно запретить доступ к папке и её содержимому /category/ или ко всем страницам, которые начинаются с /category.

Спецсимвол # (решётка).
Используется для комментариев в файле для себя, пользователей, или других веб-мастеров. Поисковые роботы эту информацию не учитывают.
Проверка работы файла
Чтобы проверить файл robots.txt на наличие ошибок, можно воспользоваться инструментами от Google и/или Яндекса.
Как проверить robots.txt в Google Search Console?
Перейдите к инструменту проверки файла. Ошибки и предупреждения будут выделены в содержании роботс.тхт, а общее количество указано под окном редактирования.
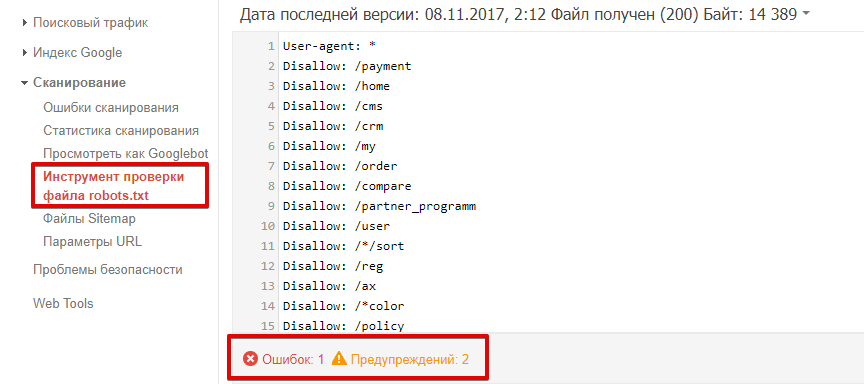
Чтобы проверить, доступна ли страница роботу, в соответствующем окне введите URL страницы и нажмите кнопку «проверить». После проверки инструмент покажет статус страницы: доступен или недоступен.

Как проверить robots.txt в Яндекс.Вебмастер?
Для проверки файла нужно перейти в «Инструменты» — «Анализ robots.txt».
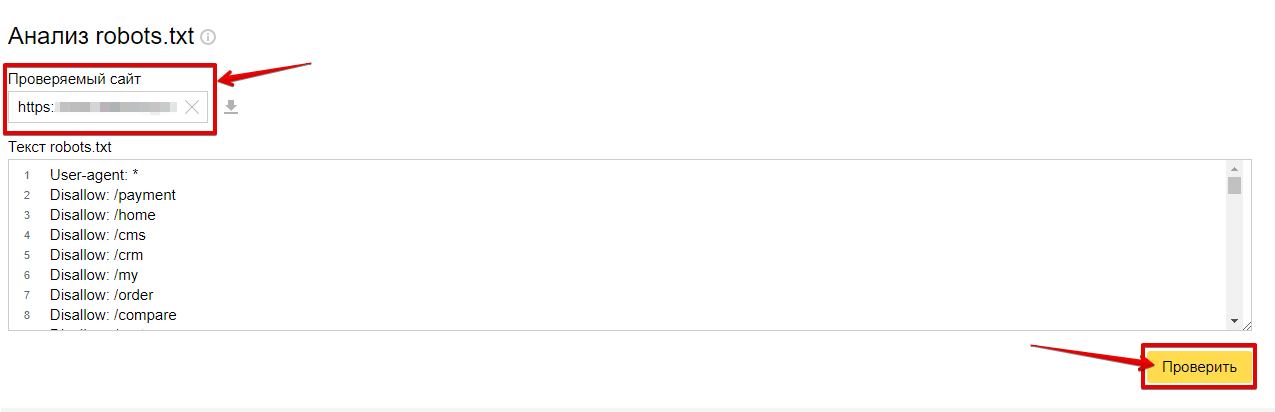
Список ошибок, возникающих при анализе роботс.
Чтобы проверить, разрешён ли доступ к странице, в соответствующем окне введите URL страницы и нажмите кнопку «проверить». После проверки инструмент покажет статус страницы: знак галочки (разрешён) или будет выведена директива, запрещающая доступ.
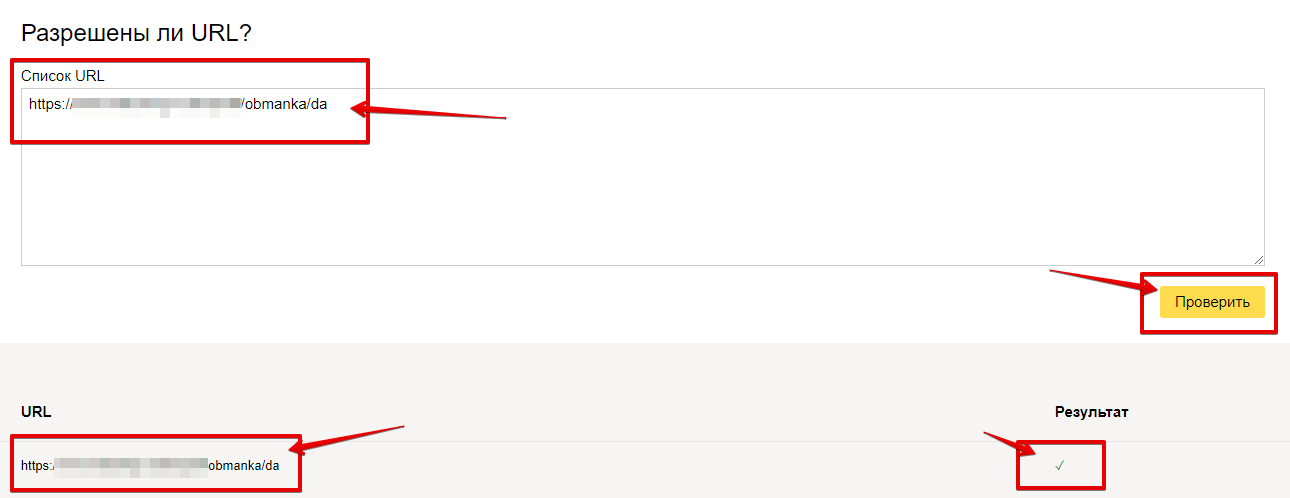
Распространённые ошибки
-
- неправильное имя файла;
Файл должен называться robots.txt. Ошибки, допускаемые в названии файла: robot.txt, Robots.txt, ROBOTS.TXT. - незаполненная строка в User-agent;
- неправильное имя файла;
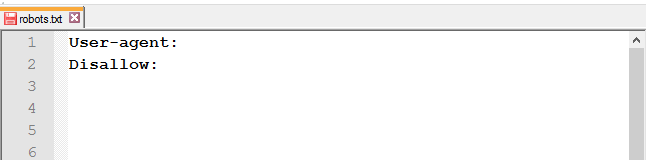
-
- перепутанные инструкции или неправильный порядок директив;

или
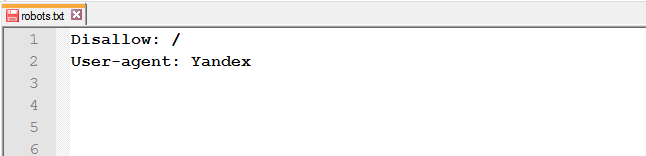
-
- пробелы, расставленные в разных местах;
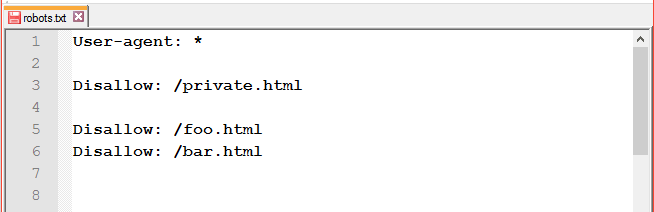
-
- использование больших букв;
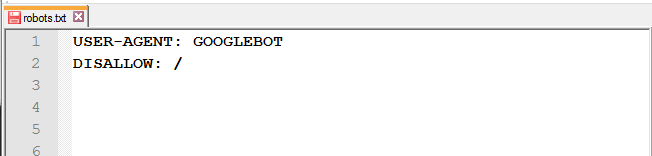
-
- Allow для индексации;
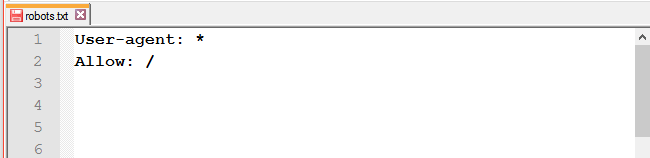 Она нужна только для переопределения директивы Disallow в том же файле robots.txt.
Она нужна только для переопределения директивы Disallow в том же файле robots.txt. - после доработок весь сайт остаётся закрытым от индексации;
- Allow для индексации;
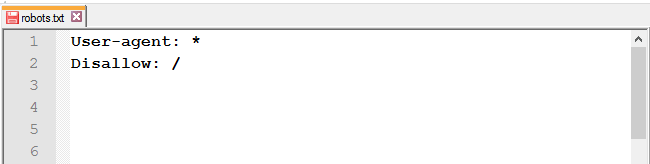
-
- закрыты от индексации CSS и JavaScript.
Часто встречаются сайты, у которых в robots.txt закрыты стили. По итогу роботы видят страницу следующим образом:
- закрыты от индексации CSS и JavaScript.
Поисковые системы не рекомендуют закрывать эти файлы от роботов.
Рекомендации Яндекса:

Рекомендации Google:

Robots.txt для различных CMS
Ниже мы предлагаем рассмотреть часто используемые директивы для различных CMS. Это не конечный вариант файла robots.txt. Этот набор правил редактируется под каждый сайт отдельно и зависит от того, что нужно закрыть, а что — оставить открытым.
Robots.txt для WordPress
Пример файла под Вордпресс:
User-Agent: * Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Allow: /wp-content/uploads/ Disallow: /tag Disallow: /category Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Allow: /wp-content/*.css* Allow: /wp-content/*.jpg Allow: /wp-content/*.gif Allow: /wp-content/*.png Allow: /wp-content/*.js* Allow: /wp-includes/js/ Host: mysite.com Sitemap: http://mysite.com/sitemap.xml
Robots.txt для Joomla
Пример роботс для Джумла:
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /components/ Disallow: /images/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Allow: /templates/*.css Allow: /templates/*.js Allow: /media/*.png Allow: /media/*.js Allow: /modules/*.css Allow: /modules/*.js Host: mysite.com Sitemap: http://mysite.com/sitemap.xml
Robots.txt для Bitrix
Пример файла для Битрикса:
User-agent: * Disallow: /*index.php$ Disallow: /bitrix/ Disallow: /auth/ Disallow: /personal/ Disallow: /upload/ Disallow: /search/ Disallow: /*/search/ Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?* Disallow: /*&print= Disallow: /*register= Disallow: /*forgot_password= Disallow: /*change_password= Disallow: /*login= Disallow: /*logout= Disallow: /*auth= Disallow: /*action=* Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*print_course=Y Disallow: /*COURSE_ID= Allow: /bitrix/*.css Allow: /bitrix/*.js Host: mysite.com Sitemap: http://mysite.com/sitemap.xml
Заключение
Файл Robots.txt — полезный инструмент в формировании взаимоотношений между поисковыми роботами и вашим сайтом. При правильном использовании он может оказать положительное влияние на ранжирование и сделать сайт более удобным для сканирования. Используйте это руководство, чтобы понять, как работает robots.txt, как он устроен и как его использовать.
P.S. В знак благодарности, что дочитали статью до конца, мы подготовили подборку неожиданных находок в файлах robots.txt.
Интернет-магазин косметики
Площадка для обмена знаниями, учебниками и ГДЗ

Приглашение на работу от известного SEO-сервиса
Ещё одно приглашение, но уже в файле humans.txt
После 2166 запрещающих, направляющих и разрешающих директив, в конце файла можно обнаружить рисуночек
Хотите узнать, нет ли ошибок в robots.txt на вашем сайте, — мы можем провести технический аудит, в котором проанализируем файл и напишем инструкции по исправлению недоработок!
Еще по теме:
- Инструменты для анализа отображения сайта на разных устройствах Поисковые системы учитывают поведенческие факторы как в десктопной версии, так и на мобильных устройствах, поэтому необходимо учитывать этот факт при разработке сайта (или при его...
- Как влияет на позиции сайта неправильное расположение заголовков Н4 и Н2? То, что у нас на сайте неправильно стоят заголовки - после 2 идет сразу 4, насколько это влияет на позиции сайта и выдачу? Ответ Мы...
- Какие возможные последствия, если на сайте убрать функционал корзины и сделать форму заявки на получение оптового прайса? Есть сайт интернет-магазин, с большим каталогом товаров, нацеленный на мелкий опт(принимаются заказы только от 300-400 $). В листинге товаров, есть кнопка быстрого добавления в корзину,...
- ТЗ на разработку сайта. Коротко о главном Несмотря на то, что обычно идея создать сайт приходит одному человеку, на деле создание сайта - это коллективное творчество. В данной статье рассмотрим принципы создания...
- Влияют ли изменения структуры страницы сайта на ее восприятие Google, как новой? Правильно ли я понимаю, что если структура страницы меняется, то Google в любом случае начинает думать, что это некая новая страница, и может даже не...

Оцените мою статью:

 (20 оценок, среднее: 4,35 из 5)
(20 оценок, среднее: 4,35 из 5)Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.

Еще одно полезное замечание, с которым столкнулся в работе:
чтобы закрыть от индексации страницы типа /category/filter1/item1 , но оставить открытыми страницы типа /filter1/item2 нужно:
Allow: /filter1/*
Disallow: /*/filter1/*
Благодарим, за это полезное замечание! Думаем, что кому-то обязательно пригодится!
отличная подборка роботсов 🙂
ахаха))) с бендером круто!
Рады, что понравилось 🙂
>>скрипты.
Зачем из закрывать? гугл просить открыть css и js
Благодарю за вопрос!
Скрипты — это же не только CSS и JS. Нам стоило уточнить, что закрывать можно неважные скрипты. Google пишет: «С помощью файла robots.txt можно блокировать неважные изображения, скрипты, файлы стилей и другие некритические ресурсы страниц».
По поводу CSS и JS Вы абсолютно правы. В статье в разделе о распространенных ошибках мы писали, что файлы стилей нужно открывать.
Вот допустим я хочу чтобы весь сайт был закрыт от индексации, но разрешить индексировать только некоторые страницы код должен быть такой
User-agent: *Crawl-delay: 5
Disallow: /
Allow: stranica1
Allow: stranica2
Я правильно понимаю?
Почти. Забыли про слеш в начале.
Allow: /stranica1
Allow: /stranica2
Проверить корректно ли составили роботс можно тут: https://webmaster.yandex.ru/tools/robotstxt/
странно, что нет примера для opencart
очень распространённая CMS
Читал, что если открыть uploads для всех ботов, то в индексе появляются загруженные PDF и прочие текстовые файлы. А в яндекс вебмастере, в отчете «Исключенные страницы» появляются сообщения об ошибке при индексировании картинок, мол содержимое не поддерживается. Вот и не знаю кому верить…