
- (Обновлено: ) Евгений Аралов

Предлагаем вам авторский перевод исследования Яндекса, представленного на конференции ECIR-2014 в Амстердаме. В докладе идет речь о том, полезно ли использовать персонализированные характеристики в улучшении качества агрегированного поискового ранжирования.
Мы подготовили для вас адаптированный перевод доклада Яндекса (Personalizing Aggregated Search), представленный в апреле на конференции ECIR-2014 (Амстердам). В докладе идет речь о том, насколько полезно использование персонализированных характеристик для улучшения качества агрегированного поискового ранжирования.
Авторы исследования: Станислав Макеев (stasd07@yandex-team.ru), Андрей Плахов (finder@yandex-team.ru), Павел Сердюков (pavse@yandex-team.ru).
1. ВВЕДЕНИЕ
Современные поисковые системы часто предоставляют доступ к специализированным поисковым сервисам или вертикальному поиску, что позволяет интернет-пользователям получить результаты различного формата (Картинки, Видео) или относящиеся к определенной сфере (Новости, Погода). Впрочем, по некоторым запросам результаты вертикального поиска могут быть включены в стандартную поисковую выдачу. В последнее время это становится все более привычной практикой ведущих поисковых систем, и именно такой подход, как правило, называют агрегированным (или интегрированным) поиском.
Основные преимущества такого подхода следующие:
Первое – у пользователя есть возможность получить релевантные результаты определенного типа непосредственно на странице результатов поиска (SERP).
Второе – на одной странице результатов предоставляется большое разнообразие информации самого различного типа, что особенно важно при работе с поисковыми запросами, которые не дают четкого понятия о том, что именно необходимо пользователю.
Оба этих преимущества можно наблюдать на скриншоте (см. ниже). Вот как выглядит страница результатов поиска по запросу «Metallica». Обратите внимание, что наряду с традиционной текстовой выдачей здесь присутствуют результаты вертикального поиска (Видео, Фото).
Насколько нам известно, ни одна из предыдущих работ не была посвящена оценке ценности индивидуальной релевантности вертикальных результатов поиска для каждого конкретного пользователя. В своей работе мы предлагаем извлечь подобную информацию из журнала истории поисковых запросов пользователя и использовать ее для формирования различных вариантов агрегированного вертикального поиска.
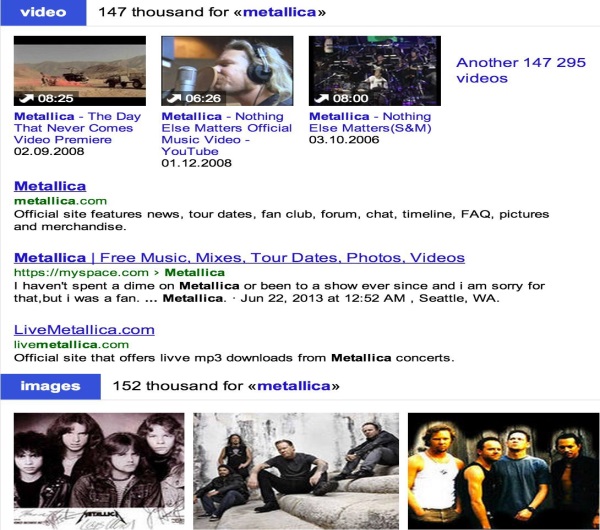
Рис.1. SERP с результатами вертикального поиска Картинки и Видео
Главная ценность данной работы заключается в следующем:
- Новаторская работа по персонализированному агрегированному поиску.
- Содержит в себе персонализированную функцию машинного осмысления ранжирования вертикалей, которая значительно улучшает показатели стандартного ранжирования вертикалей.
- Предлагается три класса персонализированных характеристик, которые должны улучшить ранжирование вертикалей, а также дается сравнительный анализ их влияния.
- Оценка влияния персонализированного метода на качество вертикального ранжирования для различных типов поисковых запросов и пользователей.
2. РАБОТЫ ПО СХОЖЕЙ ТЕМАТИКЕ
Хотелось бы отметить, что все эти работы рассматривались отдельно либо в контексте персонализированного веб-поиска, либо в контексте агрегированного поиска. И ни одна из предыдущих работ не исследовала ценность персонализированных данных в контексте агрегированного поиска. В подразделе №2.1 можно найти информацию о некоторых общих подходах в решении проблемы ранжирования вертикальных результатов поиска, а в подразделе №2.2 дается краткий обзор работ, посвященных персонализации поисковых результатов.
2.1. Выбор вертикалей
Одними из самых сложных вещей в агрегированном поиске являются определение релевантных вертикалей к пользовательскому поисковому запросу и размещение соответствующих результатов должным образом на странице результатов поиска (SERP). Традиционно эта проблема решается за счет обучения модели машинного осмысления на основе характеристик, которые должны определять вертикальную релевантность к запросу. В этом разделе мы бы хотели привести обзор таких характеристик.
Классификация носит достаточно условный характер, т.к. некоторые характеристики могут быть одновременно отнесены к разным группам.
Данные запросов [1,2,11,12]. Характеристики этого типа предоставляют некоторую информацию о вертикальной релевантности за счет использования лишь текста запроса.
Один из наиболее распространенных подходов к этой проблеме заключается в измерении вероятности запроса, заданного вертикальными моделями языка. Эти модели, как правило, основаны на вертикальных документах или запросах, для которых вертикаль была последним местом, куда кликнул пользователь.
Этот тип включает в себя также несколько простых характеристик, основанных на тексте запроса, например, таких, как: длина запроса, запросы, состоящие из регулярных выражений и т.д.
Данные вертикали [1,2,11,12]. Обычно вертикаль начисляет баллы, оценивающие актуальность по запросу, основанную на свойствах своей индексированной коллекции документов.
Например, для текстовых коллекций предусмотрены такие характеристики, как текстовая релевантность или текстовая схожесть между поисковым запросом и документом, находящимся в топе выдачи.
Данные по переходам. Эти характеристики основаны на поисковой поведенческой истории пользователя, включают в себя данные по его переходам, прокрутке страниц и т.д. Здесь заложен огромный потенциал, например, для калибровки существующих классификаторов поиска [7,8]. В своей работе Jawahar Ponnuswami и др.[11] используют CTR как характеристику для изучения модели, а также попарно используют для этих целей данные по кликам и движению курсором мыши.
Веб-данные [11]. Эту группу характеристик можно выделить отдельно. Сюда относятся характеристики, полученные из результатов органического веб-поиска, как, например: текстовая релевантность, переходы по веб-документам и т.д. Данные характеристики могут очень пригодиться для определения корректного размещения вертикальных результатов в отношении результатов веб-поиска.
Насколько нам известно, ни одно из предыдущих исследований не использовало хоть какую-либо персонализированную пользовательскую информацию для построения системы вертикального ранжирования.
2.2. Персонализация
Персонализация результатов поиска всегда подразумевает расширение контекста поиска за счет учета данных истории поиска конкретного пользователя. Например, Bennet и др. [4] используют в своей работе географические данные для расширения контекста поиска, а Харитонов и др. [10] предложили использовать данные о гендерной принадлежности пользователя для устранения неоднозначности поискового запроса.
3. НАШ ПОДХОД
Персонализация ранжирования вертикалей была осуществлена по тому же принципу, что и в работах [4],[6] или [10]. Оригинальный алгоритм ранжирования представил 10 веб-результатов и целый ряд внедренных между ними вертикальных результатов. Под «вертикалью результатов» мы будем подразумевать блок, состоящий из не менее 1 вертикального «документа».
Оригинальные страницы поиска имеют следующие ограничения:
Во-первых, на них может присутствовать не более чем один вертикальный результат, вставленный для каждой вертикали.
Во-вторых, вертикальные результаты могут отображаться только в четырех слотах:
- над первым результатом выдачи;
- между 3 и 4 результатом выдачи;
- между 6 и 7 результатом выдачи;
- после 10 результата выдачи.
Аналогичные ограничения были описаны в ряде предыдущих работ, как, например, в [1]. На рисунке №1 четко видно, что страница результатов поиска полностью соответствует данным ограничениям.
В своих экспериментах мы пытались решить более обширный вопрос, позволяющий нашим функциям переранжирования объединять стандартные и вертикальные результаты поиска в любом желаемом порядке, т.е. в случае необходимости нарушать вышеописанные ограничения.
Для этого мы рассматривали только те запросы, по которым был представлен как минимум один вертикальный результат. В своих экспериментах мы работали со следующим набором вертикалей: Картинки, Видео, Музыка, Новости, Словари, События и Погода. Хотелось бы отметить, что наш подход может быть легко применен к любым другим наборам вертикалей.
Для того чтобы осуществить переранжирование функций, мы составили многомерные вектор-функции φ (q,u,ri) для каждого результата ri, соответствующего запросу q от пользователя u. Обратите внимание, что под результатом ri может подразумеваться как стандартный веб-результат, так и вертикальный результат для любой вертикали. Если результат поиска отвечал требованиям запроса пользователя (т.е. был релевантен), мы помечали его вектор «1» (единицей), если нет – «0». После этого мы использовали точечный подход для составления модели ранжирования и переранжировали все результаты в соответствии с данными модели.
3.1. Базовые характеристики
Здесь мы опишем принцип построения не зависящей от поведения пользователя базовой вектор-функции – φB (q,r).
Данные запросов. Для каждой вертикали мы построили вертикальную статистическую языковую модель. Каждая модель была построена на основе запросов, для которых результат по вертикали рассчитывается как количество кликов за время пребывания пользователя на документе по запросу (dwelltime) более чем за 30 секунд.
Для построения своих моделей мы предпочитали использовать тексты запросов, нежели тексты документов, т.к. некоторые из наших вертикалей работали с нетекстовым контентом, а мы бы хотели рассматривать вертикали последовательно. Другой причиной является то, что модели, построенные таким образом, обладают очень схожей семантикой, по характеристикам, с ключевыми словами, а это ведет к тому, что и наши функции переранжирования обладают сигналом этого же типа. В качестве характеристики мы также добавили сюда длину поискового запроса.
Данные вертикалей и данные Веб (т.е. данные стандартных результатов поиска). В качестве первой характеристики сюда можно отнести позицию результата в оригинальном рейтинге поисковой выдачи. Здесь в качестве характеристики используется показатель релевантности результата, оцениваемый оригинальным алгоритмом ранжирования, который применяется только для веб-документов. Обратите внимание на то, что наш базовый набор характеристик включает в себя характеристики, необходимые для получения неперсонализированной версии показателя вертикальной релевантности. Именно поэтому для корректного сравнения данных персонализированного и неперсонализированного подходов мы предельно точно и подробно определяем и соотносим релевантность вертикалей этих двух методов.
Данные журнала поиска. Следующие характеристики, которые мы использовали, были основаны на пяти кликовых функциях.
3.2. Характеристики персонализации
Мы предлагаем ввести три класса персонализированных характеристик, которые, на наш взгляд, улучшат алгоритм вертикального ранжирования.
Потребность агрегированного поиска. Предполагается, что данный набор функций будет сообщать, заинтересован ли в целом пользователь в агрегированных результатах поиска и предпочитает ли он их стандартным результатам веб-поиска. Обозначим вектор этих функций как φa(u).
Предпочтение конкретных вертикалей. Этот набор свойств описывает требования пользователя для получения результатов определенного типа по всем поисковым запросам. Мы считаем, что данная характеристика тесно связана с интересами пользователя и ее добавление в пользовательский персонализированный профиль может помочь в устранении некоторой неоднозначности запросов для каждого конкретного пользователя.
Первая характеристика данного класса выражает разницу между пользовательской статистической языковой моделью (строится по запросам пользователя в течение изучаемого отрезка времени) и языковой моделью для результатов вертикали.
Еще одним способом выразить вышеописанную мотивацию можно за счет использования данных информации по кликам. Для этого мы используем специальные функции. Вектор-функция для этих характеристик обозначается как φc (u,ri).
Вертикальная навигационность. Необходимо помнить, что порой пользовательские потребности могут не совпадать с его общими предпочтениями по некоторым специфичным поисковым запросам. Например, результаты поиска по вертикалям Новости или Погода могут быть более актуальными, чем результаты из вертикали Картинки для пользователя из Амстердама по запросу [Амстердам], даже если ранее этим пользователем отдавалось предпочтение вертикали Картинки. Вектор-функция для этих характеристик обозначается как φn (q,u,ri).
Также мы добавили абсолютные значения соответствующих кликов и отобразили каждый из них на вектор-функциях. Таким образом, нашим моделям был сообщен уровень пользовательской активности, касающийся вертикальных результатов, что также могло представлять ценность для работы алгоритма обучения. Обратите внимание, что эти векторы функций имеют смысл только для вертикальных результатов.
3.3. Функции переранжирования
Мы «обучили» целый ряд функций переранжирования, отличающихся друг от друга набором используемых характеристик. Для обучения своих моделей мы отдали предпочтение оригинальной версии алгоритма дерева принятия решений GBDT (GradientBoostedDecisionTrees-basedalgorithm), которая настроена на минимизацию MSE (MinimizeMeanSquaredError (MSE) – минимизация среднего квадрата ошибки (разности между действительными и предсказанными значениями)) (аналогичные GBDT-алгоритмы применялись в работах [3,11]).
Базовая вектор-функция RB была обучена при помощи вектора функций φB(q,r). Эта вектор-функция включает в себя позицию результата в оригинальном рейтинге поисковой системы Яндекса. С другой стороны она также включает в себя типовой набор характеристик, ранее описанных в подразделе №2.1. Так что данные функции предоставляют нам для работы достаточно серьезный набор базовых характеристик.
Для того чтобы по достоинству оценить потенциал персонализации для улучшения результатов агрегированного поиска и выяснить, какой именно класс характеристик персонализации обладает наибольшим влиянием, мы обучили еще 4 функции ранжирования. А именно:
- Racn – была обучена на соединение вектор-функций φB, φa, φc, φn
- Rac – была обучена на соединение вектор-функций φB, φa, φc
- Ran – на соединение вектор-функций φB, φa, φn
- Rcn – на соединение вектор-функций φB, φc, φn
3.4. Набор данных и протокол эксперимента
Для проведения своих экспериментов мы воспользовались данными пользовательских сессий, взятых из журналов поиска Яндекса. По каждому запросу в журналах содержались следующие данные: сам запрос, топовые результаты поиска по данному запросу, информация о кликах по результатам.
Всем пользователям поисковой системы был назначен анонимный UID (идентификатор пользователя), куки, данные о котором также хранятся в журналах, что позволило нам выделять действия, совершаемые различными пользователями.
Мы рассматривали набор пользовательских сессий, взятых за промежуток в восемь недель, т.е. те, что были зафиксированы с мая по июнь 2012 года. При этом мы брали во внимание только те результаты поиска, которые содержали в себе по крайней мере один вертикальный результат.
Поскольку мы собирались дать оценку персонализированным характеристикам, для нас не представлялось возможным воспользоваться данными асессоров, поэтому нам пришлось извлекать информацию о релевантности результатов из журналов поиска. Мы считали результат релевантным поисковому запросу, если по нему было щелкнуто при показателе dwelltime> 30 секунд или если клик по данному результату был последним действием пользователя в его сессии. Во всех других случаях мы считали изучаемый результат нерелевантным.
Для того чтобы в ходе своих экспериментов получить непредвзятые результаты, мы строго следовали протоколу, который описан в работе [5]. Для построения обучающих и тестовых наборов мы воспользовались данными сессий, взятых за седьмую и восьмую неделю соответственно. При этом мы выстроили наборы данных таким образом, чтобы не тестировать модели по сессиям одного и того же периода. Сделано это было по той причине, что данные сессий, используемых для обучения, могли бы предвзято повлиять на конечные результаты.
По обоим наборам данных мы рассматривали только те запросы, у которых хотя бы один результат имел положительную оценку, а вертикальный результат при этом считался «замеченным». Чтобы построить функции на основе информации из поисковых журналов (как персонализированных, так и неперсонализированных), для обучающего набора мы воспользовались данными сессий, взятых за промежуток в 1-6 недель, а для тестового набора – за 2-7 недель (т.е. у них был равный объем данных).
И наконец, наш пользовательский набор (UP) состоит из пользователей, которые просмотрели результат из любой вертикали не менее 5 раз в течение двух изучаемых периодов времени по наборам функций (т.е. за 1-6 недель и 2-7 недель).
В конечном счете, у нас «на руках» оказались данные около 3 млн пользователей, а также обучающие и тестовые наборы, содержащие в себе результаты поиска по примерно 7 млн запросов.
Все функции ранжирования были обучены, а затем оценивались с помощью пользовательской специфичной версии пятикратной перекрестной проверки, которая была создана специальным образом. Данный тип проверки позволил нам быть уверенными в том, что полученные результаты не искажались в сторону пользовательских данных, используемых для обучения.
4. РЕЗУЛЬТАТЫ
Качество переранжирования было измерено с помощью макроусредненной средней точности (MeanAveragePrecision – MAP) переранжированных документов по запросам в каждой тестовой части, а затем усреднено по частям.
Мы также измерили производительность наших моделей по отношению к целому ряду параметров запроса с точки зрения их потенциала по улучшению данных персонализации. Еще мы адаптировали общую кликовую энтропию к потребностям агрегированного поиска, т.е. мы не использовали кликовую вероятность для каждого результата. Вместо этого мы использовали агрегированные вероятности клика по всем веб-результатам и вероятность клика по каждой вертикали.
4.1. Общая производительность
Наша Racn функция переранжирования повлияла на 29% всех поисковых запросов в каждой тестируемой части. А по всем запросам MAP возрос на 18%. Таким образом, с помощью своих функций переранжирования мы улучшили поисковую выдачу на 62%.
Все 4 персонализированные модели значительно улучшили качество ранжирования. И степень этого улучшения варьируется по различным классам запроса, также она значительно возрастает с ростом кликовой энтропии, что полностью соответствует результатам предыдущих исследований.
Что касается силы персонализированных характеристик, то игнорирование такой характеристики, как «вертикальное предпочтение», ведет к значительному ухудшению производительности модели. А вот исключение двух других типов характеристик ведет к меньшему снижению качества, но, тем не менее, также ухудшает производительность модели по всем поисковым запросам и для большинства подклассов.
4.2. Анализ уровня запроса
Во-первых, мы бы хотели более детально изучить зависимость влияния персонализированного подхода от изменений в кликовой энтропии. На рисунке №2 показаны улучшения MAP как функции адаптированной кликовой энтропии. Этот график показывает, что в целом рост энтропии ведет к увеличению силы влияния персонализации на ранжирование вертикалей. Более того, положительный эффект наблюдается даже на запросы с низким показателем энтропии.
Как уже было сказано выше, наша функция переранжирования повлияла на 29% всех поисковых запросов в каждой тестируемой части, что примерно составляет 1,2 млн запросов. С другой стороны, в каждой тестируемой части содержится примерно 680000 уникальных запросов; наша функция переранжирования повлияла на 32% из них, при этом 61% изменений носил положительный характер. Необходимо обратить внимание на то, что один и тот же запрос, введенный разными пользователями, в поисковой выдаче мог быть ранжирован по-разному или вовсе отсутствовать на странице результатов поиска.
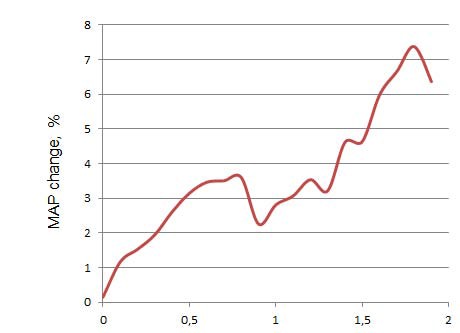
Рис. №2. Изменение MAP как функции энтропии
4.3. Анализ уровня пользователя
Еще одним важным аспектом анализа персонализированных моделей является их влияние на отдельных пользователей. Итак, у нас были данные о 3 млн пользователей (UP), которые мы разделили на 5 непересекающихся частей. Таким образом, в каждой части оказалось по 600000 пользователей. Однако в каждой части набора данных были запросы, введенные примерно 450000 пользователями, т.к. не все пользователи проявляли активность на 8 тестируемой неделе. Сессии 54% пользователей подверглись влиянию нашей функции переранжирования, и для 64% из них персонализированное переранжирование имело позитивный характер. На рисунке №4 виден средний рост MAP для части пользователей между 5-ой и 95-ой процентилями образцов пользователей, которые ввели по меньшей мере 5 поисковых запросов на 8 неделе.
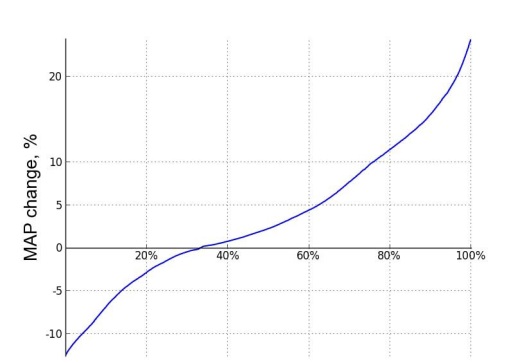
Рис. №4. Изменение MAP по пользователям (отсортированы по изменению MAP)
4.4. Анализ SERP
В ходе своей работы мы также изучили, в какой зависимости находится влияние персонализации от представленных в поисковой выдаче вертикалей. Для этого мы в первую очередь измерили, как персонализированное переранжирование изменило порядок вертикальных результатов, при условии, что страница результатов изначально содержала в себе не менее двух вертикалей. Для данной цели мы подсчитали показатель MAP, учитывая только результаты вертикалей и таким образом получили рост в 1,24.
Мы также исследовали зависимость роста показателя MAP от числа представленных вертикалей в SERP. Результаты оказались следующими: по 1 результату вертикали (а это 75% запросов) показатель роста MAP составляет 2,72%, для 2 вертикалей (22% запросов) MAP растет на 3,80%, для 3 вертикалей (2,5% запросов) – рост MAP составляет 4.31% , а для 4 вертикалей (примерно 0,5% запросов) – 3,43%. Все эти изменения достаточно ощутимы.
Мы также изучили, какие именно вертикали в большей или меньшей степени ощутили преимущества персонализированного подхода в процессе ранжирования и выяснили, что наилучшим образом данный подход повлиял на вертикали Видео и Погода (5,35% и 8,2%), а меньше всего на вертикали Словари и События.
ВЫВОД
В данной работе мы рассмотрели ранее не исследуемую проблему персонализированного агрегированного поиска и разработали структуру с тремя классами персонализированных характеристик. Это позволило нам построить беспрецедентную функцию ранжирования, которая в среднем превосходит существующую систему по MAP в 3% по всем запросам в агрегированном поиске. Разработанная нами функция переранжирования изменила результаты поисковой выдачи для 29% запросов, при этом улучшив их ранжирование на 61%. В ходе исследования мы также выяснили, что класс характеристик «конкретные вертикальные предпочтения» – это один из самых главных классов при построении конкурентоспособного персонализированного ранжирования, впрочем, два оставшихся класса также значительно влияют на ранжирование.
Персонализированный агрегированный поиск намного эффективнее и качественнее стандартного метода ранжирования.
ЛИТЕРАТУРА
1. Arguello J., Diaz F., Callan J.: Learning to aggregate vertical results into web search result. In: Proceedings of CIKM 2011(2011)
2. Arguello J., Diaz F., Callan, J., Crespo J.F.: Sources of evidence for vertical selection. In: Proceedings of SIGIR 2009 (2009)
3. Arguello J., Diaz F., Paiement J.F.: Vertical selection in the presence of unlabeled verticals. In: Proceedings of SIGIR 2010 (2010)
4. Bennett P.N., Radlinski F., White R.W., Yilmaz E.: Inferring and using location metadata to personalize web search. In: Proceedings of SIGIR 2011 (2011)
5. Bennett P.N., White R.W., Chu W., Dumais S.T., Bailey P., Borisyuk F., Cui X.: Modeling the impact of short- and long-term behavior on search personalization. In: Proceedings of SIGIR 2012 (2012)
6. Collins-Thompson K., Bennett P.N., White R.W., de la Chica S., Sontag D.: Personalizing web search results by reading level. In: Proceedings of CIKM 2011 (2011)
7. Diaz F.: Integration of news content into web results. In: Proceedings of WSDM 2009 (2009)
8. Diaz F., Arguello J.: Adaptation of offline vertical selection predictions in the presence of user feedback. In: Proceedings of SIGIR 2009 (2009)
9. Dou Z., Song R., Wen J.R.: A large-scale evaluation and analysis of personalized search strategies. In: Proceedings of WWW 2007 (2007)
10. Kharitonov E., Serdyukov P.: Gender-aware re-ranking. In: Proceedings of SIGIR 2012 (2012)
11. Ponnuswami A., Pattabiraman K., Wu Q., Gilad-Bachrach R., Kanungo T.: On composition of a federated web search result page: using online users to provide pairwise preference for heterogeneous verticals. In: Proceedings of WSDM 2011 (2011)
12. Styskin A., Romanenko F., Vorobyev F., Serdyukov P.: Recency ranking by diversification of result set. In: Proceedings of CIKM 2011 (2011)
13. Vallet D., Castells P.: Personalized diversification of search results. In: Proceedings of SIGIR 2012 (2012)
Авторский перевод статьи — Евгений Аралов
Еще по теме:
- SEO vs PPC: почему продвижение в органической выдаче более эффективно и менее затратно? При выборе стратегии продвижения в органической выдаче или контексте лучше выбрать… оба варианта. Если, конечно, бюджет позволяет. Если нет, то в первую очередь нужно задать...
- 3 шага в Яндекс.Метрике: ищем источник падения трафика Часто вебмастера сразу начинают менять все на сайте, хотя причиной падения трафика могли стать пару запросов на одну конкретную страницу. Поэтому не нужно спешить, а...
- Конверсия сайта: как считать, от чего зависит Понятие «конверсия» довольно обширное и используется во многих областях науки: химии, микробиологии, психологии, лингвистике. Как правило, под конверсией подразумевается процесс обращения или превращения. Также понятие...
- Стоит ли бороться за попадание в блок с ответами в Google Поиске? Что вы должны знать о быстрых ответах Google a. Виды блоков с ответами b. Достоинства и недостатки c. Как запретить поисковику добавлять фрагменты сайта в...
- Анализ логов сайта с помощью Power BI: пошаговая инструкция Анализ логов сайта – важная часть технического аудита, особенно если у сайта есть проблемы с индексацией. В этой статье мы разберём, что такое логи, какую...

Оцените мою статью:
 (Пока оценок нет)
(Пока оценок нет)Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.

Не пойму, что дает сеошнику эта статья? Куча формул. Я на середине уснул и не дочитал. Что полезного я должен был узнать из статьи?
Яндекс семимильными шагами двигается к персонализированной выдаче, так, например, в 2013 году была анонсирована платформа "Атом" (https://habrahabr.ru/company/yandex/blog/195982/), которая призвана адаптировать интернет под каждого отдельного человека. Данный доклад доказывает, что персонализированный поиск эффективен. Нам, как SEO-специалистам, нужно учитывать этот факт и готовится к будущим переменам.