

Что такое «Королёв»?
22 августа 2017 года Яндекс официально заявил о запуске нового поискового алгоритма «Королёв» (назван в честь города, как и большинство предыдущих поисковых алгоритмов). В его основе лежит механизм распознавания сложных запросов, который работает по принципу самообучаемой нейронной сети. Это значит, что Яндекс должен определять подходящие по смыслу документы, даже если они не содержат слов из запроса.
Чем он отличается от «Палеха»?
Ещё в ноябре 2016 года Яндекс запустил предшественника «Королёва» — поисковый алгоритм «Палех». Основное отличие нового алгоритма, помимо улучшения технической реализации, — возможность распознавать схожие «смыслы» по всему документу, а не только заголовку (Title), который появляется в окне браузера.
Для чего внедрили алгоритм «Королёв»?
В Яндексе давно задумывались над проблемой определения релевантных документов по большому пулу низкочастотных запросов, которые задаются не совсем естественным языком. Это большой список запросов типа:
— [на какой картине плавятся часы]
— [где придумали одеколон]
— [в каком фильме писатель сходит с ума отеле]
Основная проблема — подходящие документы могли не содержать слов из запроса. Чтобы её решить и показывать более подходящую выдачу, было задумано создание алгоритма «Королёв» — самообучающейся нейронной сети. Как заверяют в самом Яндексе, нейронная сеть на основе машинного обучения будет совершенствоваться в понимании «смыслов», которые подразумевает человек при вводе запросов.
Как работает этот алгоритм на практике?
Описанный Яндексом подход звучит, конечно, хорошо, но гораздо интереснее посмотреть на конкретные результаты в выдаче.
Для начала возьмём запрос, который сам Яндекс рекламировал:
[картина где небо закручивается]
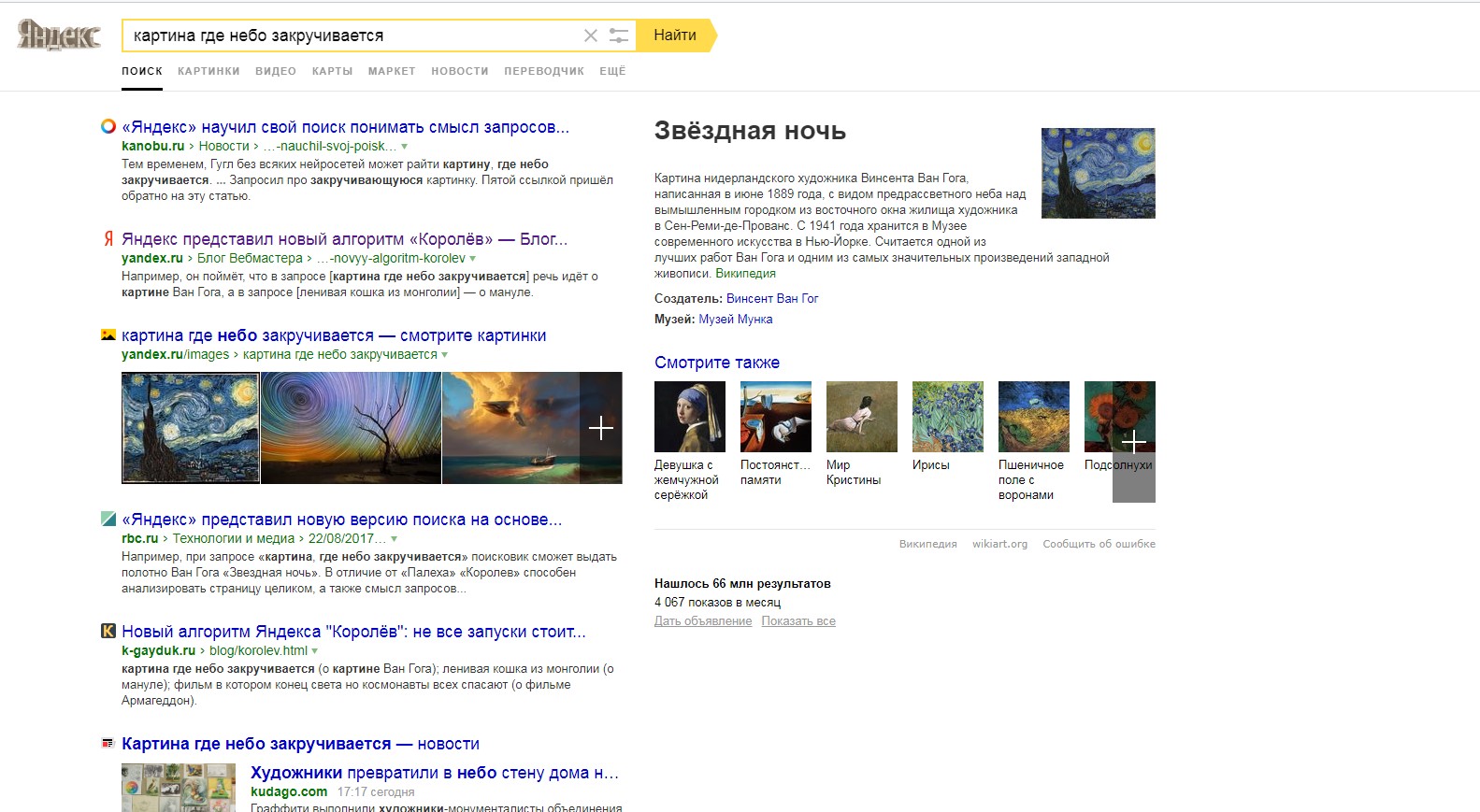
В объектных ответах справа Яндекс правильно определил, что мы подразумевали своим запросом. Он также указал верные ответы в Яндекс.Картинках. Остальная выдача состоит из новостей о новом алгоритме. Становится очевидным: в данной ситуации Яндекс пользуется традиционными методами определения релевантности и для выдачи алгоритм «Королёв» не работает.
Попробуем по-другому и зададим следующий запрос:
[где появился первый парламент]
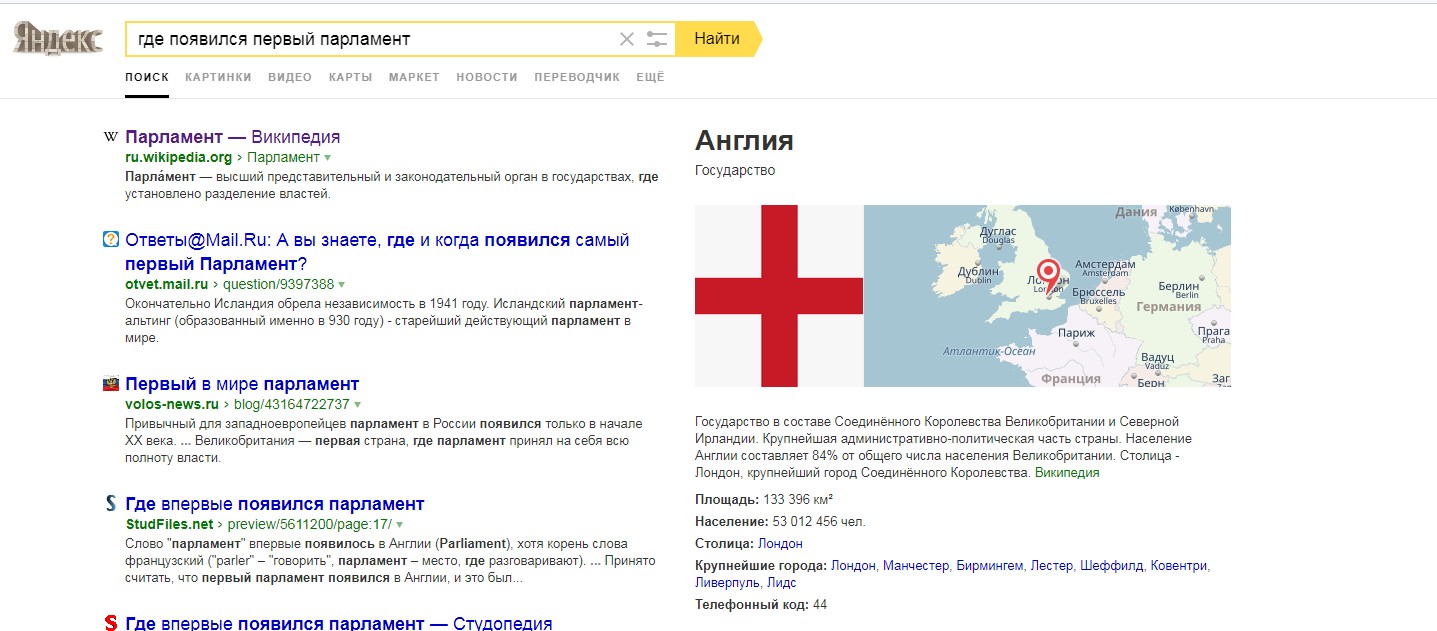
В данном случае можно увидеть интересную выдачу. В объектных ответах появилось значение «Англия». В самой же выдаче есть разные сайты, которые содержат слова из запроса.
Алгоритм в объектных ответах работает, если мы хотим знать:
— где появилось слово «парламент»;
— где появился первый представительный и законодательный орган, который называется «парламент».
Алгоритм не работает:
— если мы хотим знать, где появился вообще первый законодательный орган.
Принято считать, что первый парламент появился в Исландии, но назывался он не «парламент», а «альтинг». В выдаче (на скриншоте выше) можно увидеть и правильный ответ на наш запрос. Он появился только потому, что в заголовке статьи есть слова из запроса.
Важно понять:
поисковик может понять запрос, только если каждое слово обладает одним понятным смыслом.
Если слово обладает несколькими смыслами, как в нашем случае «парламент», могут возникать проблемы.
Проведём ещё один эксперимент:
[песня про теракт в уоррингтоне]
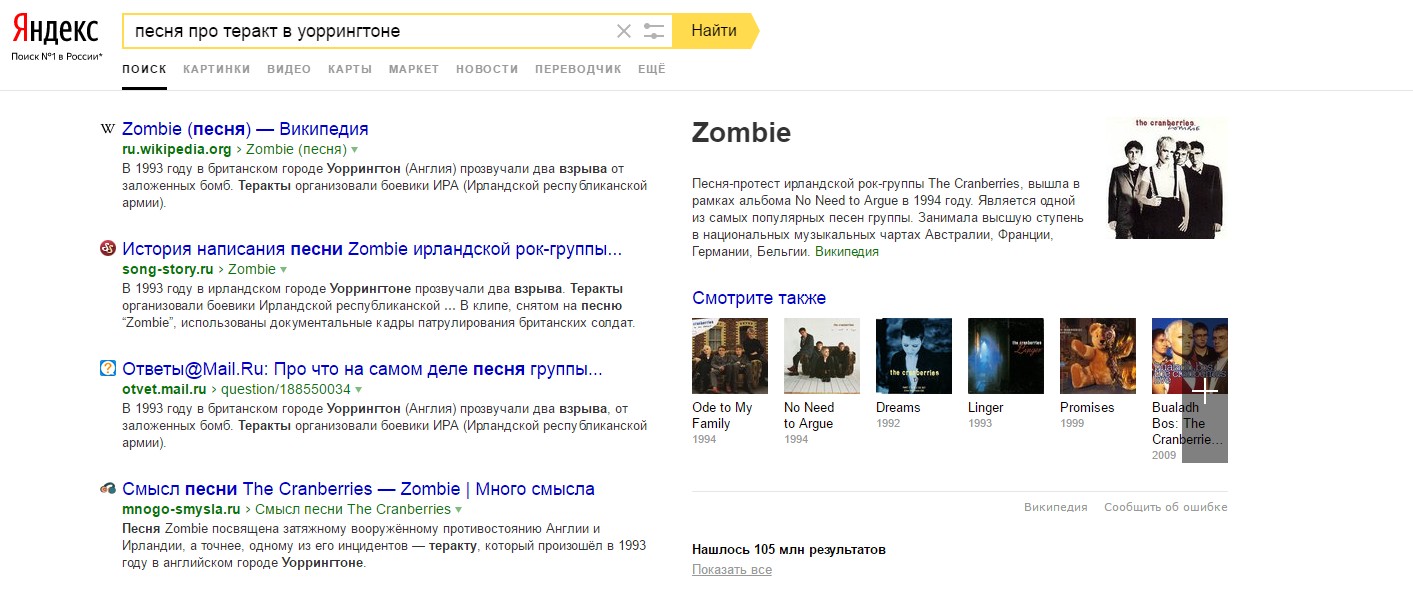
Запрос максимально конкретный и на него может быть только один конкретный ответ — песня «Zombie» группы The Cranberries.
Если немного поменять запрос и указать [песня про теракт в 1993 году], можно увидеть, что поисковик выдачу разделяет: часть ответов о песне, часть — о теракте. Яндекс не совсем понимает, о чём именно мы хотим получить информацию.
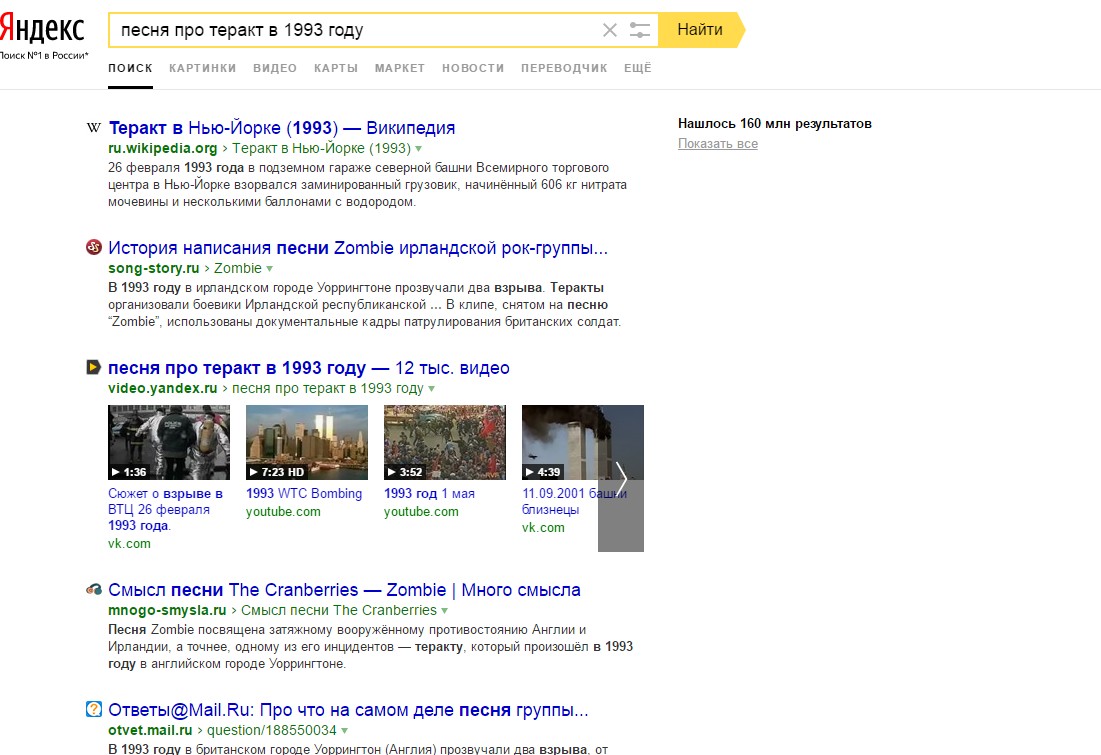
Если сделать запрос ещё более общим, то правильного ответа не будет совсем:
[песня про теракт в англии]
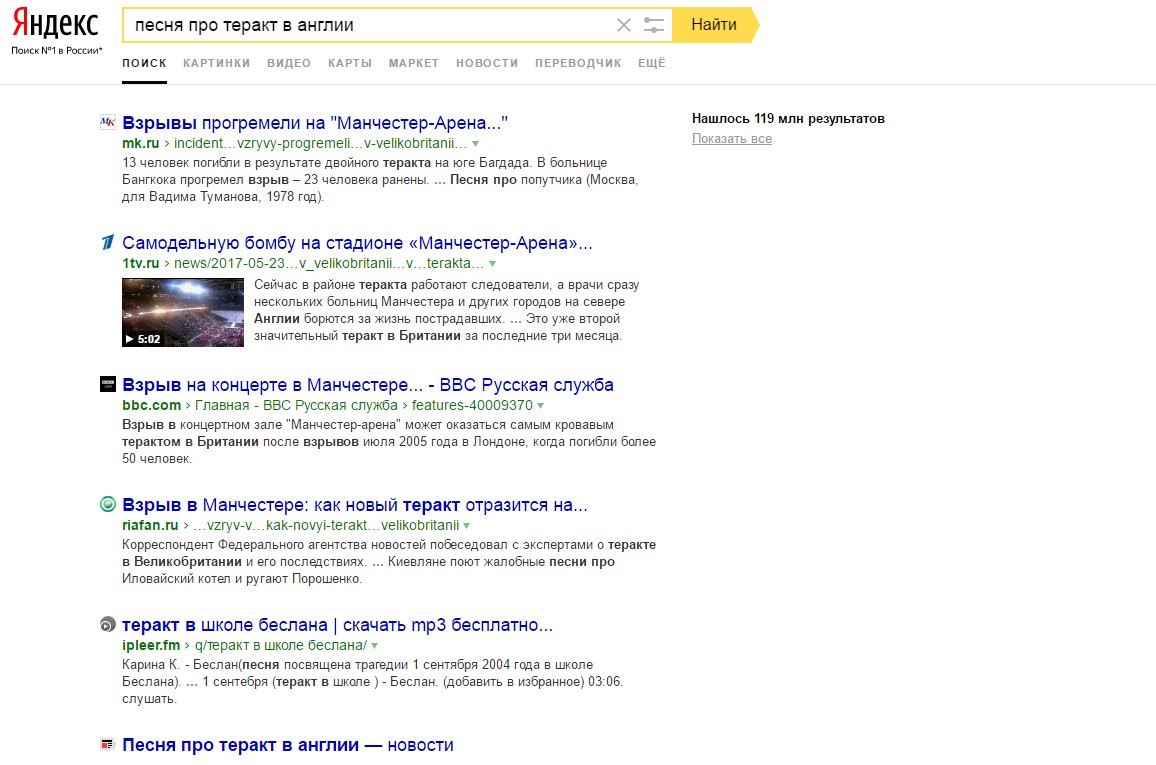
Выдача полностью состоит из новостей о теракте, а о заявленном смысле речи не идёт.
Теперь наберём запрос:
[фильм в котором писатель сходит с ума в отеле]
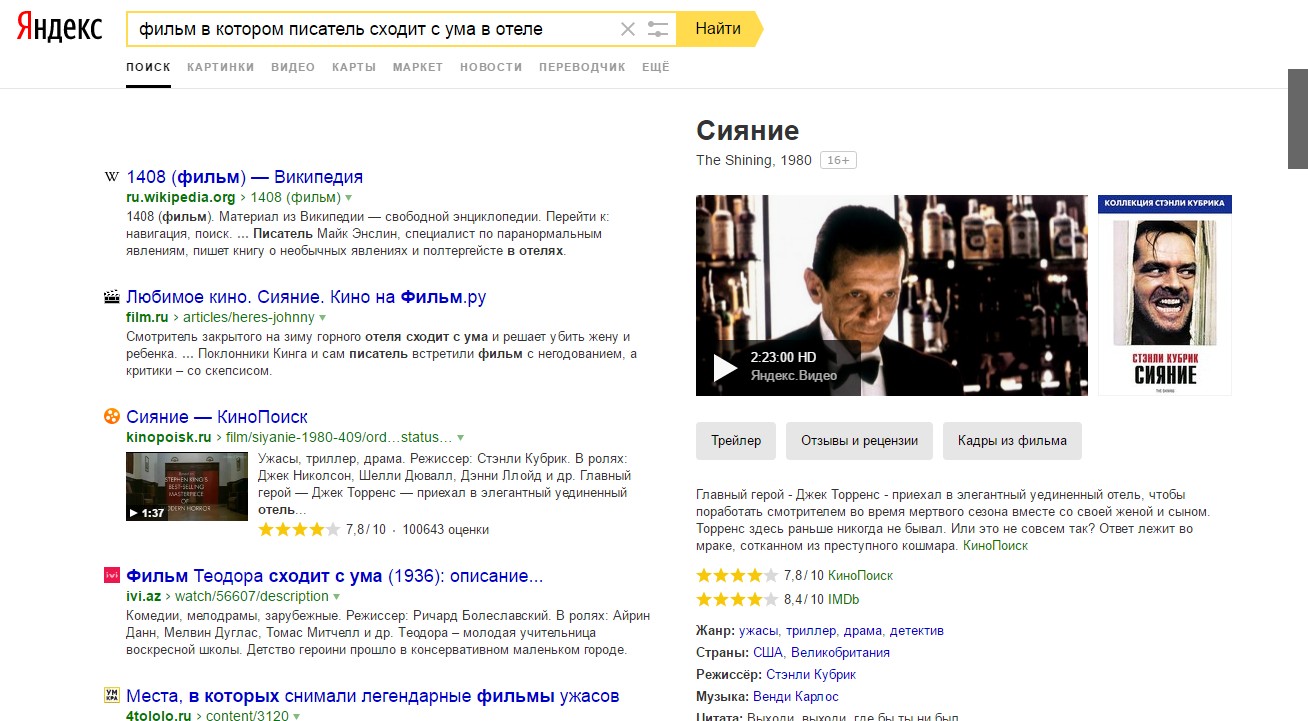
В этом случае можно увидеть, что алгоритм работает. Яндекс понимает, что мы хотим найти и, при этом, указывает, что у данного запроса есть два смысла (два интента): фильм «Сияние» и фильм «1408». Тут также важно, что слова из запроса не встречаются на страницах. В этом случае алгоритм работает.
Теперь попробуем набрать запрос:
[фильм в котором траволта танцует]
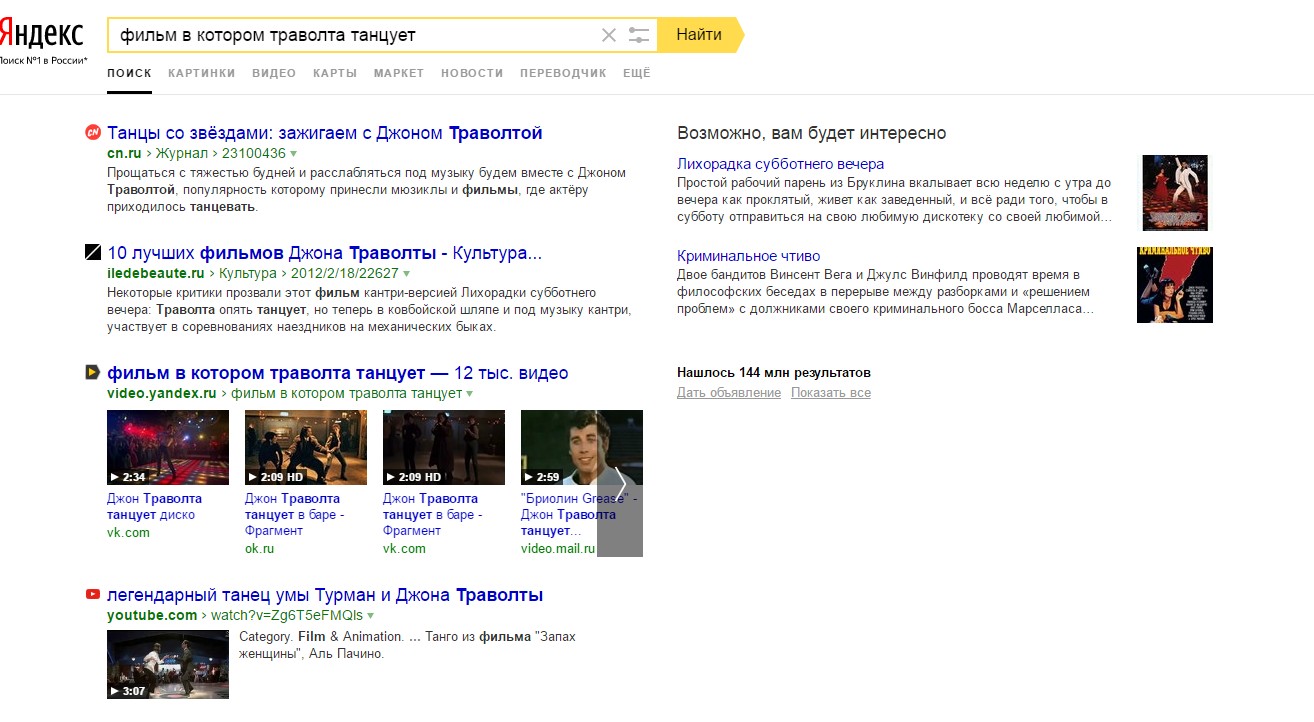
Варианты с наиболее популярными фильмами есть в объектных ответах, но не в выдаче.
Ответы становятся более конкретными, если модифицировать запрос:
[фильм в котором траволта танцует молодой]
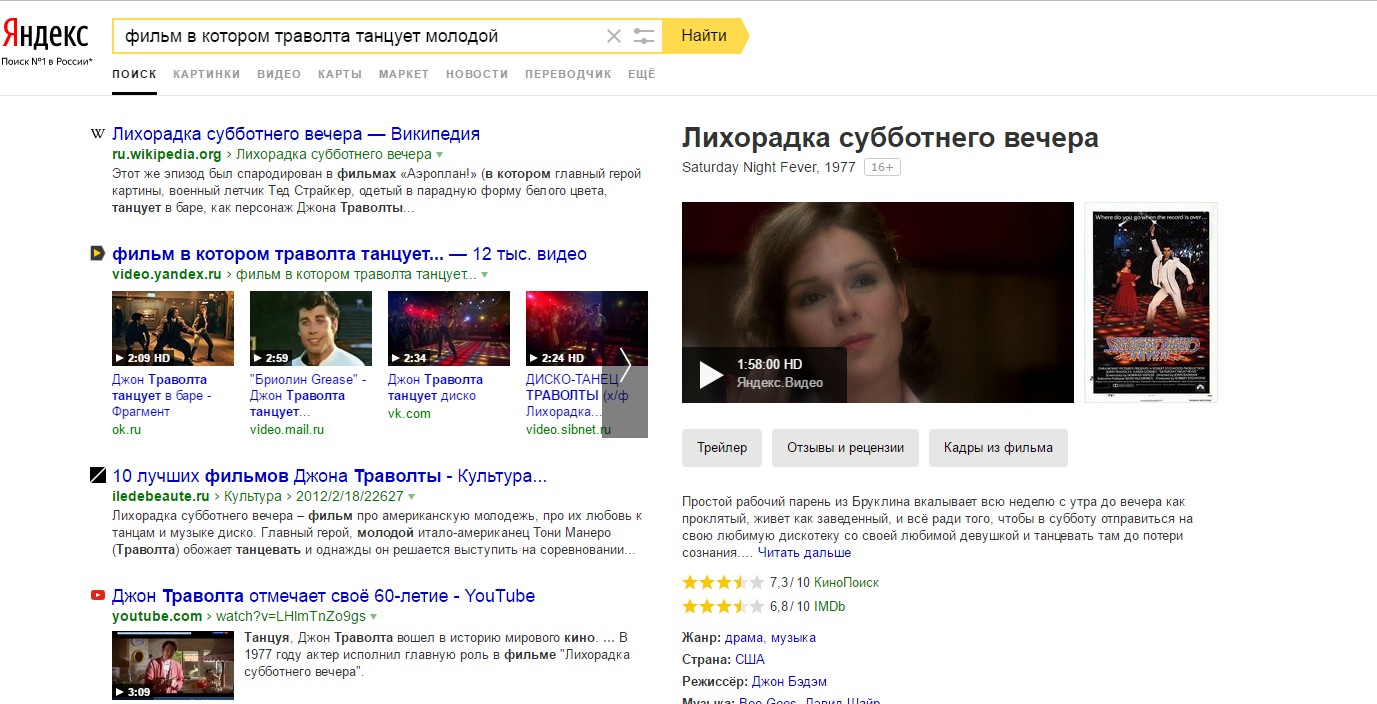
Правильный вариант можно увидеть только в виде объектного ответа и страницы Википедии. Остальная выдача далека от нужного результата.
Ещё раз изменим запрос и наберём:
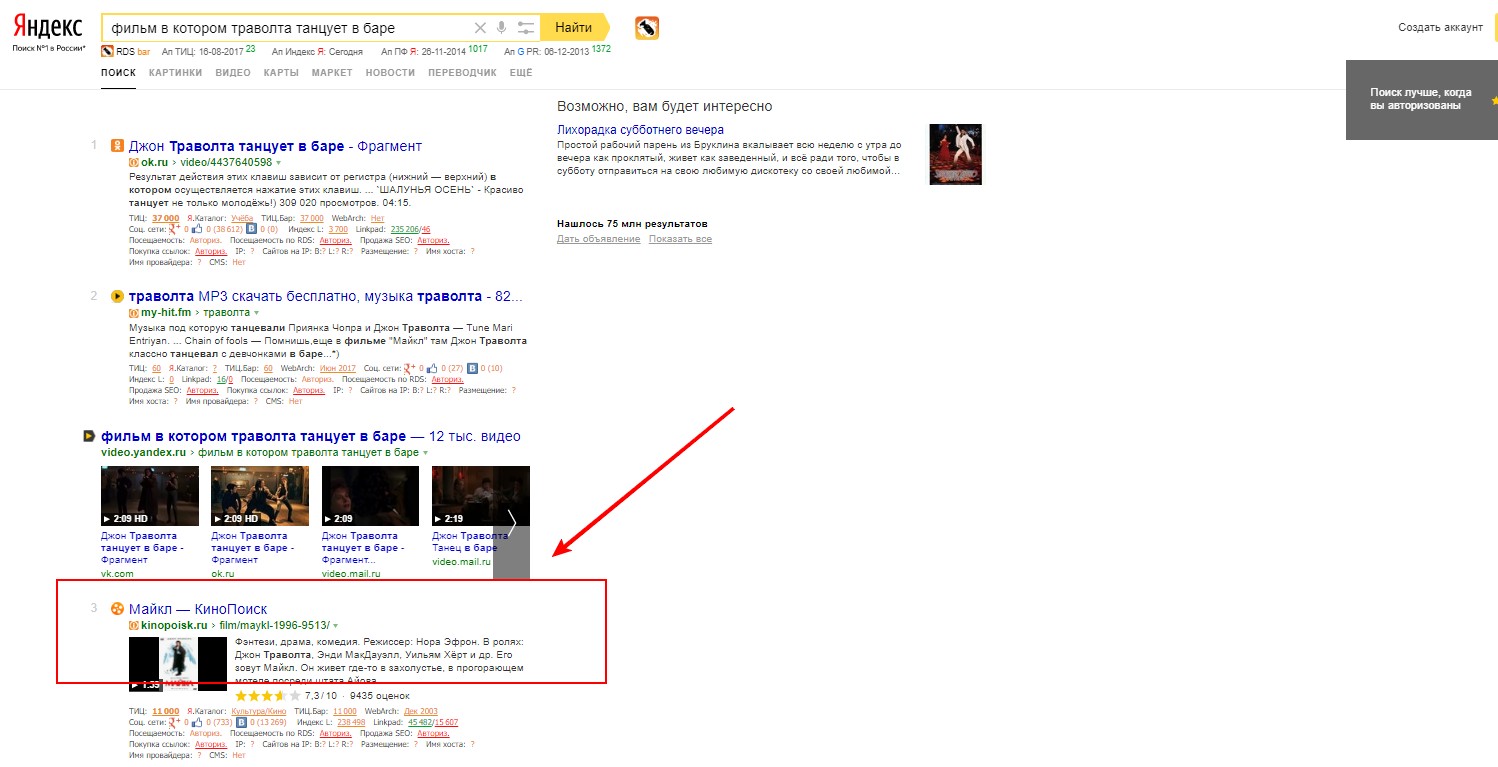
[фильм в котором траволта танцует в баре]
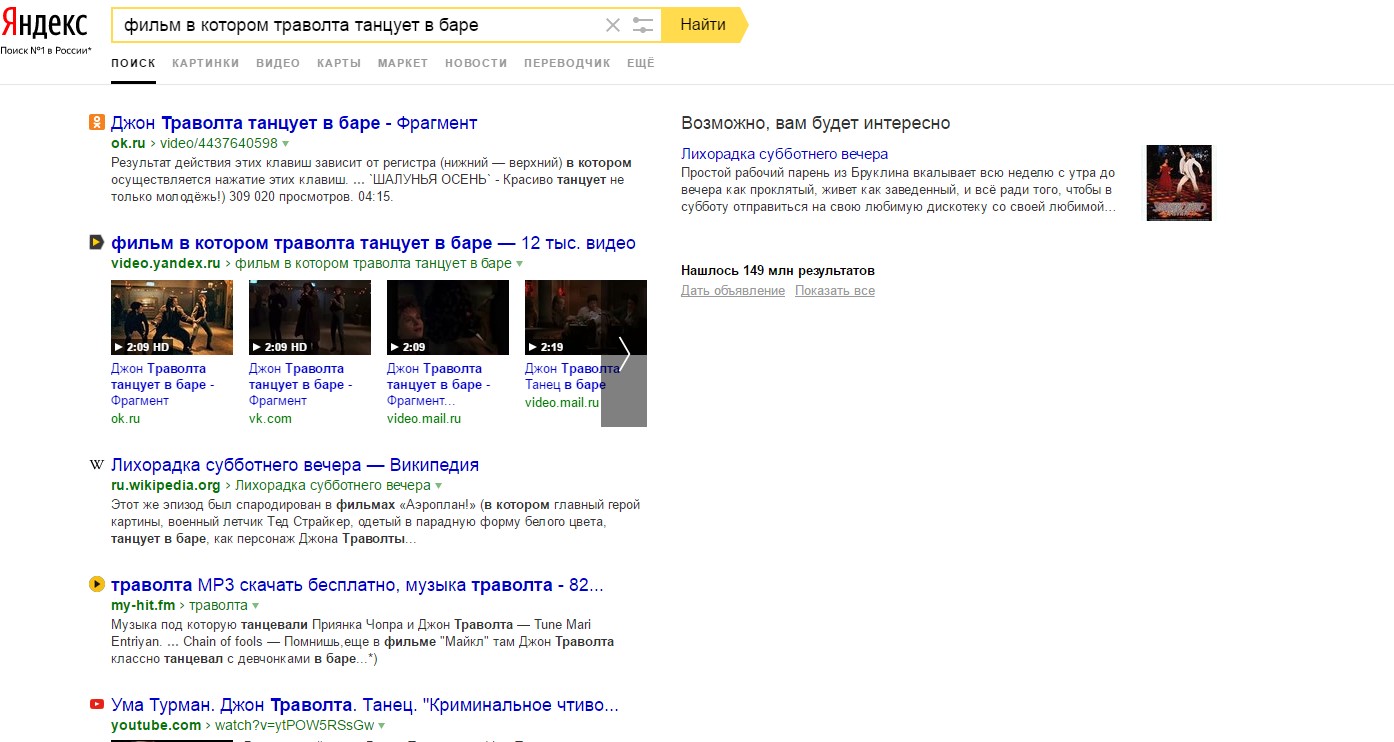
Как мы видим, алгоритм даёт сбой. Это происходит потому, что на данный запрос крайне сложно дать однозначный ответ. Например, в фильме «Криминальное чтиво» танцы происходят в ресторане, в фильме «Лихорадка субботнего вечера» — в клубе. Но есть фильм «Майкл», в котором Траволта как раз танцует в баре. Если несколько раз протестировать выдачу с целью найти необходимый фильм, начнут появляться релевантные результаты.
Какие выводы можно из этого сделать?
- Алгоритм показывает свою работу в выдаче только на страницах больших информационных сайтов (типа Википедия или Кинопоиск) и в объектных ответах.
- Алгоритм понимает только простые запросы, которые содержат один смысл.
- «Королёв» лучше работает при поиске популярной информации (например, по запросу «фильм» он покажет наиболее популярный, наиболее известный — тот, о котором информации в индексе больше всего).
- Алгоритм работает только с информационными запросами.
- Алгоритм действительно самообучаемый и при повторных обращениях результаты становятся лучше.
Для SEO алгоритм сейчас даёт мало. По большинству запросов большое значение имеет текстовый фактор. Там, где работает новый алгоритм, Яндекс отдаёт предпочтение более известным сайтам, например, Википедии. Небольшим проектам будет тяжело с ними конкурировать. Возможность высоко ранжироваться по таким запросам появится только когда у алгоритма будет более полная база знаний о желаниях и предпочтениях пользователей. Но для этого уже сейчас нужно:
— создавать текстовый контент, который содержит как можно больше слов, определяющих тематику страницы;
— улучшать поведенческие факторы, чтобы поисковик точно знал, что страница будет полезной пользователю.
Хотите получить рекомендации по улучшению контента сайта и подготовить его к работе алгоритма — обратитесь к нам.
Еще по теме:
- Аудит в январе дешевле на 20%! Принимаем заказы на январь со скидкой 20%! Пока вы будете отмечать праздники и отдыхать от повседневных забот, наши эксперты разработают инструкции по повышению трафика и...
- Tell me, please, или Почему так важен диалог с клиентом Не знаете, как оформить заявку на лечение сайта? Думаете, как аргументировать клиенту, зачем вам нужны данные статистики? В сегодняшней статье мы на примерах расскажем, к...
- Как повысить релевантность в 2019 году Что такое релевантность Как поисковые системы понимают, что страница релевантна запросу Как это делает Яндекс А что же Google Как проверить, по каким запросам поисковые...
- Размышления на тему: «Гарантии и схемы оплаты в SEO» Есть ли гарантии в SEO? От чего зависит эффективность SEO-канала и что могут предложить сегодня SEO-компании своим клиентам? В сегодняшней статье хотим поднять, а лучше...
- Топ лучших вопросов SEO-доктору выпуск #3 В нашем Telegram-канале "Дежурный SEO-доктор" уже накопилось свыше 350 вопросов от вебмастеров и SEO-специалистов, в первом и втором выпусках подборки лучших вопросов мы уже отвечали на...

Оцените мою статью:

 (11 оценок, среднее: 4,64 из 5)
(11 оценок, среднее: 4,64 из 5)Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.

Еще есть куда стремится, алгоритм еще молодой 🙂
яндекс все злее и злее
Подсказки бесят, стали всякую ерунду предлагать что мне не нужно