

- Как выделить трафик карточек товара в Яндекс.Метрике
- Как выделить трафик английской версии сайта в Яндекс.Метрике
- Как исключить брендовый трафик в Яндекс.Метрике
- Парсинг данных с помощью регулярных выражений в Netpeak Spider
- Регулярные выражения при работе с семантикой в Key Collector
- Онлайн-сервисы для проверки регулярки
Регулярные выражения в SEO помогают решать рутинные задачи быстрее и эффективнее. Поскольку спектр применения их не ограничивается построением различных отчётов в метриках, мы на живых примерах наших проектов покажем, где и как применять регулярку, чтобы максимально упростить себе жизнь.
Как выделить трафик карточек товара в Яндекс.Метрике
Регулярные выражения в Яндекс.Метрике незаменимы при формировании всевозможных отчётов, а в некоторых случаях без них и вовсе не обойтись при выделении трафика различных видов страниц. Такие отчёты очень просто построить, если на сайте присутствует уникальный идентификатор вложенности, например, для карточки товара это может быть /tovar/, /product/, /item/ и др., о чём расскажем позже.
Но когда URL карточки товара имеет вид /catalog/avtobagazhniki/89522/320419, то без регулярных выражений уже никуда. В таких случаях URL карточки имеет два последних уровня вложенности, которые состоят только из цифр.
Для построения регулярного выражения нам пригодятся следующие операторы:
- «\» – экранирование;
- «\d» – любой символ цифры;
- «+» – один или более предыдущих символов;
- «$» – конец строки.
Получаем следующее регулярное выражение:
\/\d+\/\d+$
Далее используем это выражение при создании отчёта: Отчёты – Стандартные отчёты – Источники – Поисковые системы.
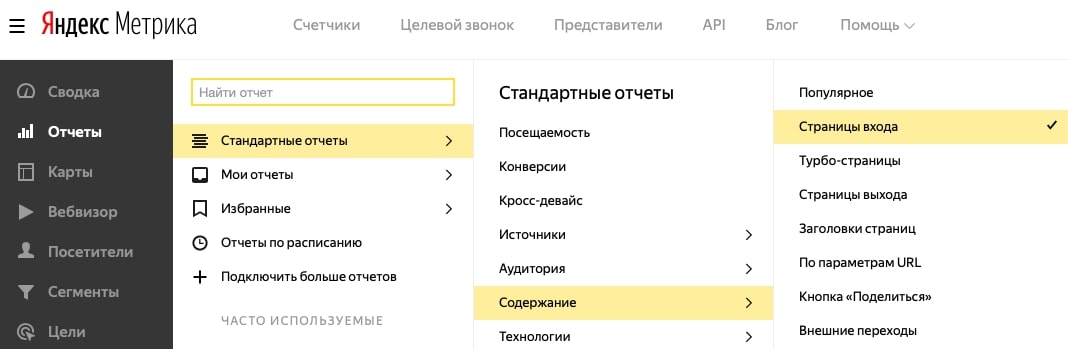
Добавляем сегмент: Визиты в которых – Поведение – Страница входа.
В поле после знака «~» вводим наше регулярное выражение.
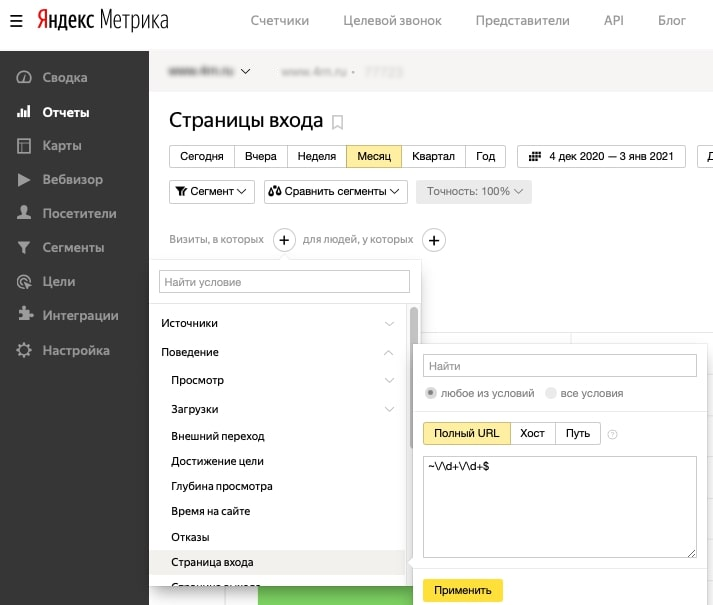
В итоге имеем отчёт по трафику карточек товара.
Как выделить трафик английской версии сайта в Яндекс.Метрике
Если на сайте присутствует уникальный идентификатор вложенности английской версии сайта, например, /en/, тогда для построения регулярного выражения нам нужны следующие операторы:
- «\» – экранирование;
- «.» – любой символ;
- «*» – любое количество предыдущих символов;
- «$» – конец строки.
\/en\/.*$
Используя предыдущий алгоритм построения отчёта, мы можем выделить трафик страниц, имеющих вложенность /en/.
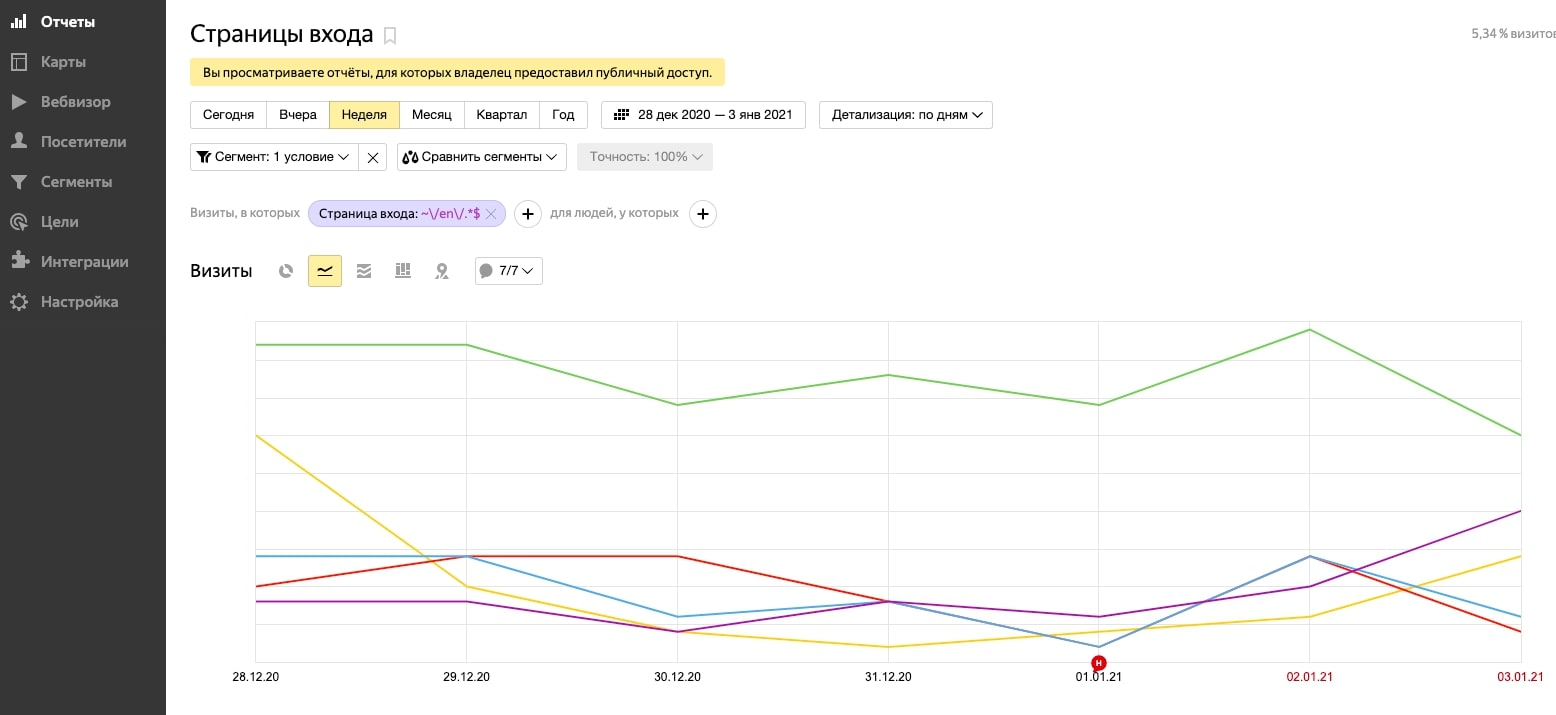
Примечание: большинство интернет-магазинов используют уникальные идентификаторы вложенности для листингов (/catalog/, /shop/ и др.) и карточек товара (/tovar/, /product/ и др.), что позволяет выделять данным способом трафик для различных видов страниц сайта, немного откорректировав регулярное выражение:
- \/catalog\/.*$
- \/shop\/.*$
- \/product\/.*$ и т. д.
Если уникального идентификатора нет – придётся написать индивидуальное регулярное выражение, как мы показывали в предыдущем примере.
Как исключить брендовый трафик в Яндекс.Метрике
В первую очередь нам необходимо составить список различных вариантов написания названия сайта, которые будут включать как правильные, так и неправильные раскладки клавиатуры. Например, для интернет-магазина gazonov.com брендовые запросы будут следующие:
- gazonov – правильное написание;
- газонов – правильное написание кириллицей;
- газоновком – вариант правильного написания кириллицей;
- пфящтщм – название с неправильной раскладкой;
- ufpjyjd – название с неправильной раскладкой;
- ufpjyjdrjv – вариант названия с неправильной раскладкой.
Нам пригодятся следующие операторы:
- «|» – «ИЛИ»;
- «$» – конец строки.
Получаем следующее регулярное выражение:
gazonov|газоновком|пфящтщм|ufpjyjd|ufpjyjdrjv$
Из данного выражения мы специально исключаем фразу «газонов», которая часто присутствует в не брендовых запросах, обыграем её позже.
Также могут встречаться всевозможные варианты запросов с учётом доменной зоны, чтобы учесть это, нам нужны следующие операторы:
- «\» – экранирование;
- «\s» – пробельный символ;
- «.» – любой символ.
Получаем следующее регулярное выражение:
\.com|\.com\s|\scom\s|\.ком\s|\sком\s|газонов\scom|газонов\sком$
Объединив оба выражения, получаем:
gazonov|газоновком|пфящтщм|ufpjyjd|ufpjyjdrjv$|\.com|\.com\s|\scom\s|\.ком\s|\sком\s|газонов\scom|газонов\sком$
Далее используем это выражение при создании отчёта: Отчёты – Стандартные отчёты – Источники – Поисковые запросы.
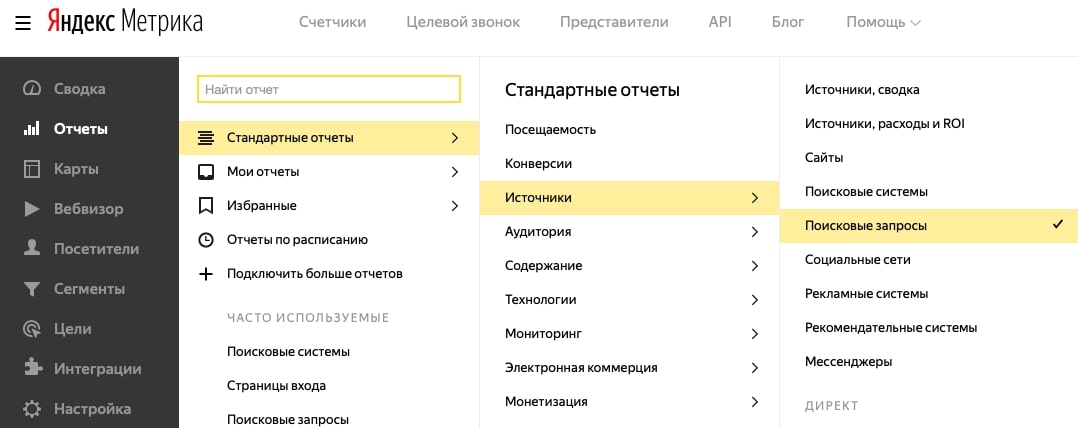
Добавляем сегмент: Визиты в которых – Источники – Последний значимый источник – Поисковая фраза.
В поле указываем начало отрицания «!» (мы ведь исключаем брендовый трафик), а после знака «~» вводим наше регулярное выражение.
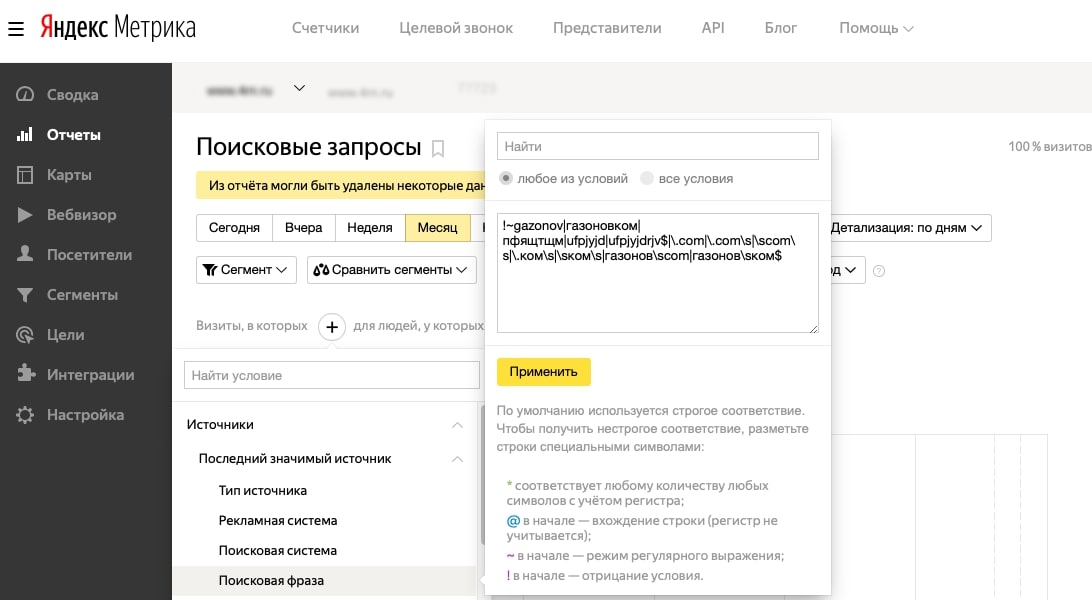
В итоге имеем отчёт, из которого исключён брендовый трафик.
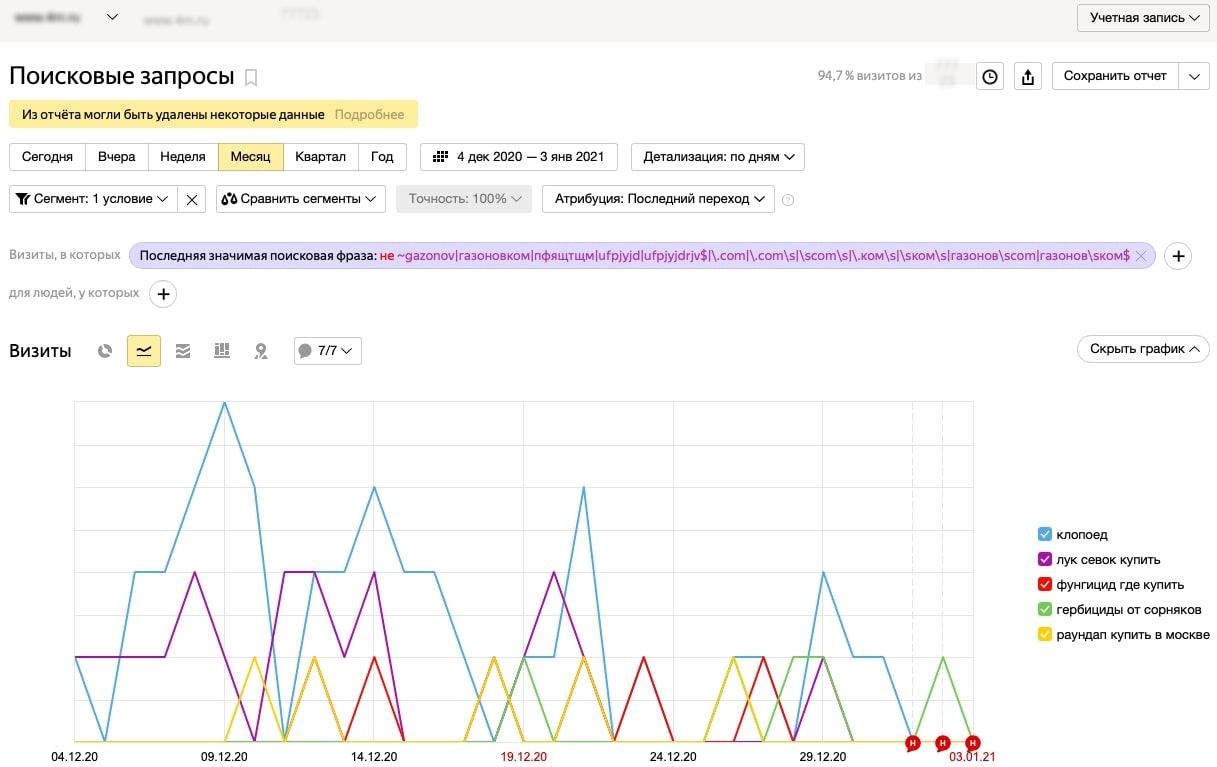
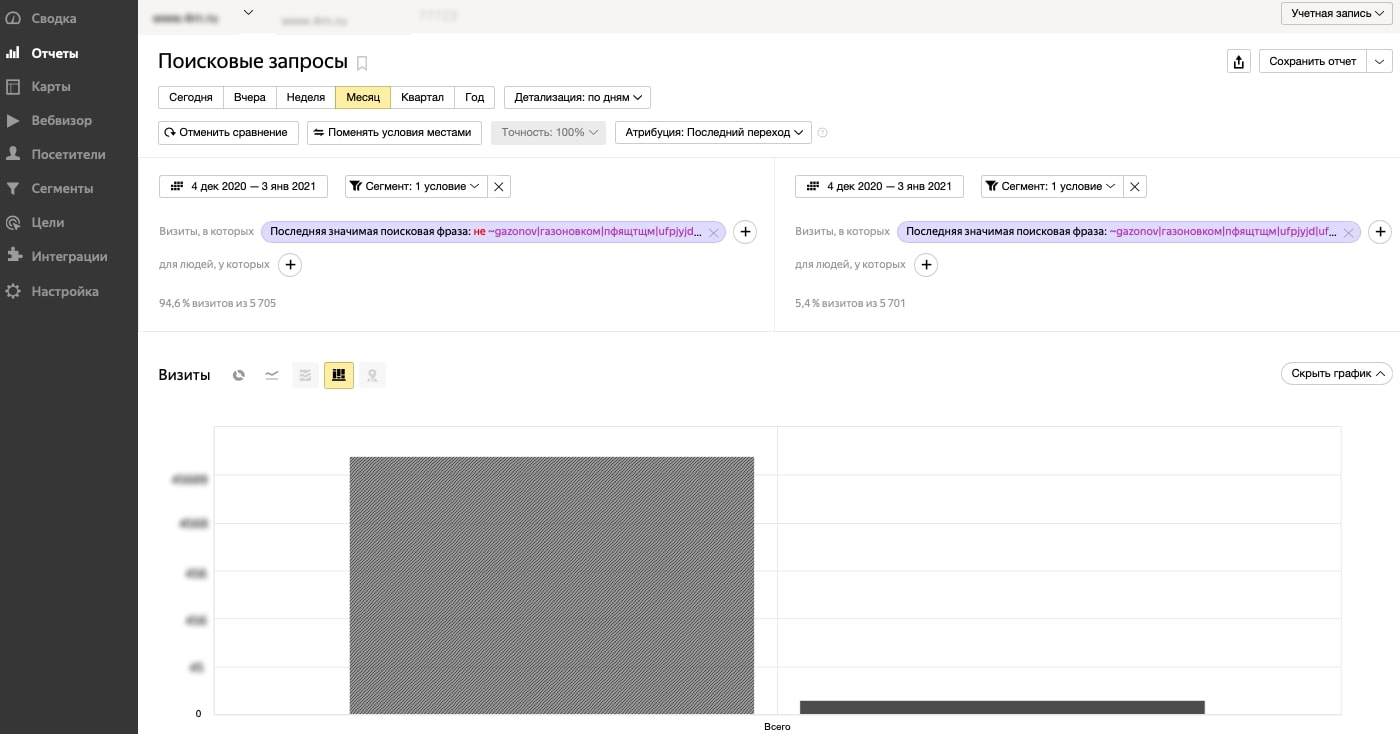
Для наглядности можно сравнить объёмы брендового и не брендового трафика на сайте.
Парсинг данных с помощью регулярных выражений в Netpeak Spider
При парсинге с помощью Netpeak Spider присутствует возможность извлекать данные со страниц с использованием регулярок. Это может быть полезным в случае ребрендинга сайта или приведения в порядок написания названия компании, если оно в разное время существования сайта писалось по-разному.
Для этого в настройках Netpeak Spider выбираем «Парсинг», а вид парсинга «RegExp». В поле вводим наше регулярное выражение. Не забываем при необходимости учитывать регистр и задавать название поля для извлечённых данных.
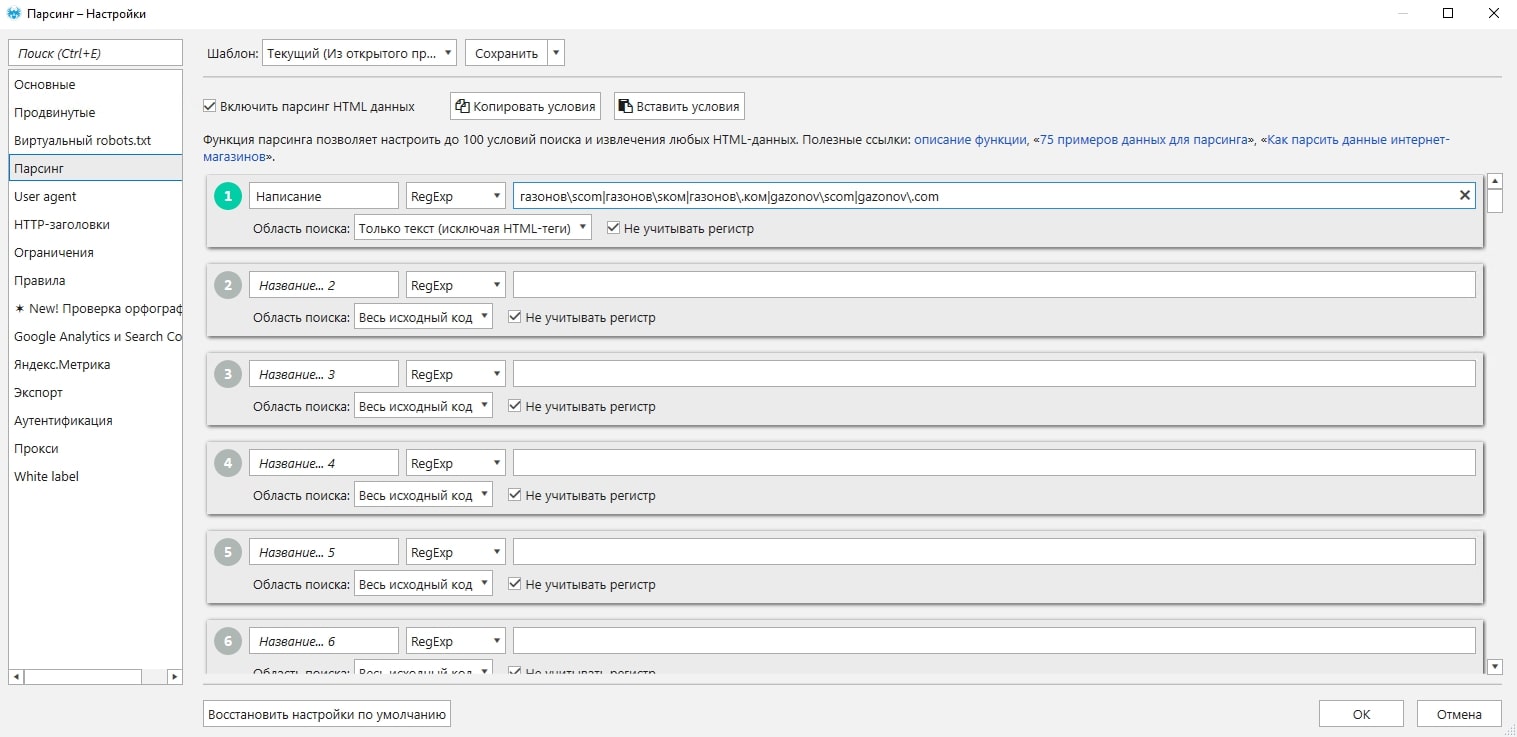
В панели параметров парсинга, помимо выбранных стандартных, появляется пункт «Парсинг», который также нужно будет отметить.
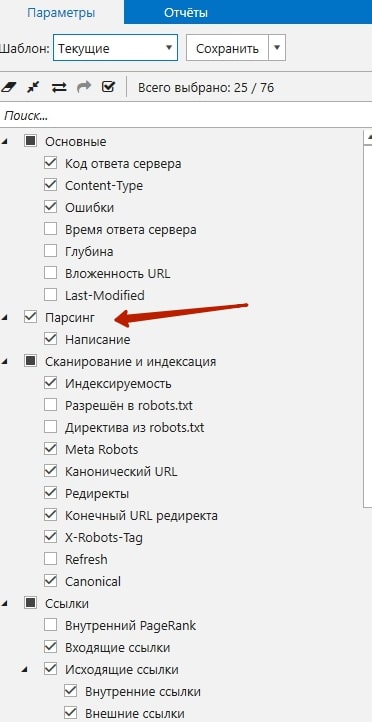
После окончания парсинга получить отчёт с извлечёнными данными можно следующим образом: База данных – Все данные парсинга.
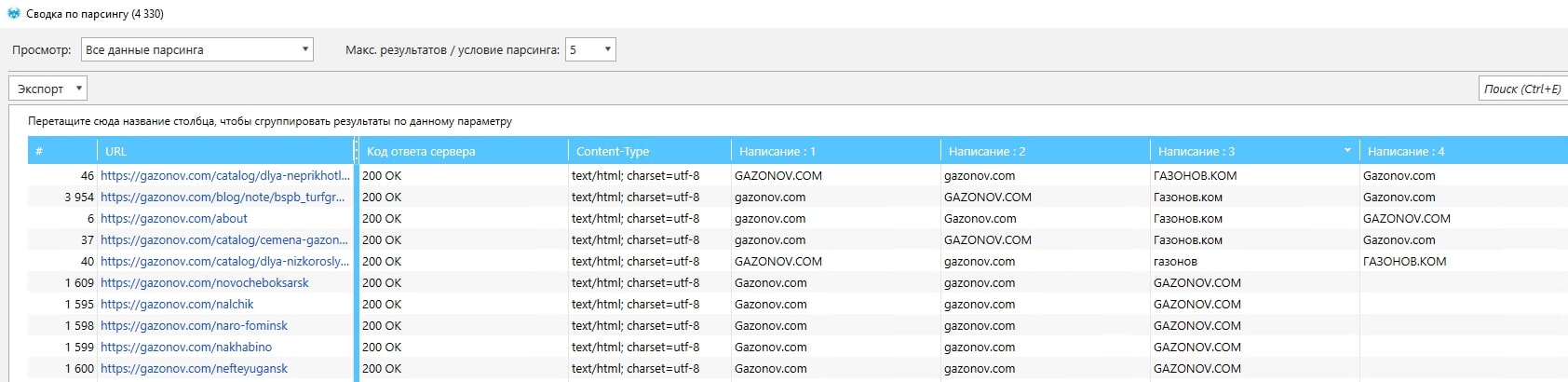
Этот отчёт будет содержать все варианты написания компании, которые удовлетворяют условию в регулярном выражении.
Регулярные выражения при работе с семантикой в Key Collector
При работе с семантикой регулярки также могут ускорить рабочий процесс. В Key Collector существует возможность фильтрации по регулярным выражениям.
Разберём на примере фильтрации фраз, которые в себе содержат лишь год. Это можно сделать и через обычный текстовый фильтр, но с помощью регулярного выражения процесс ускоряется в разы.
Для выделения фраз, которые включают слова с четырьмя цифрами, редактируем условия фильтрации с учётом следующего регулярного выражения:
\d{4}
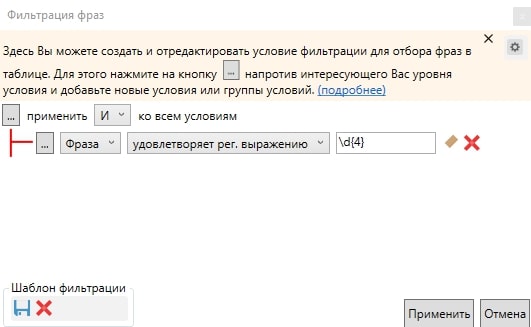
Аналогичные действия можно провести с помощью быстрого фильтра.
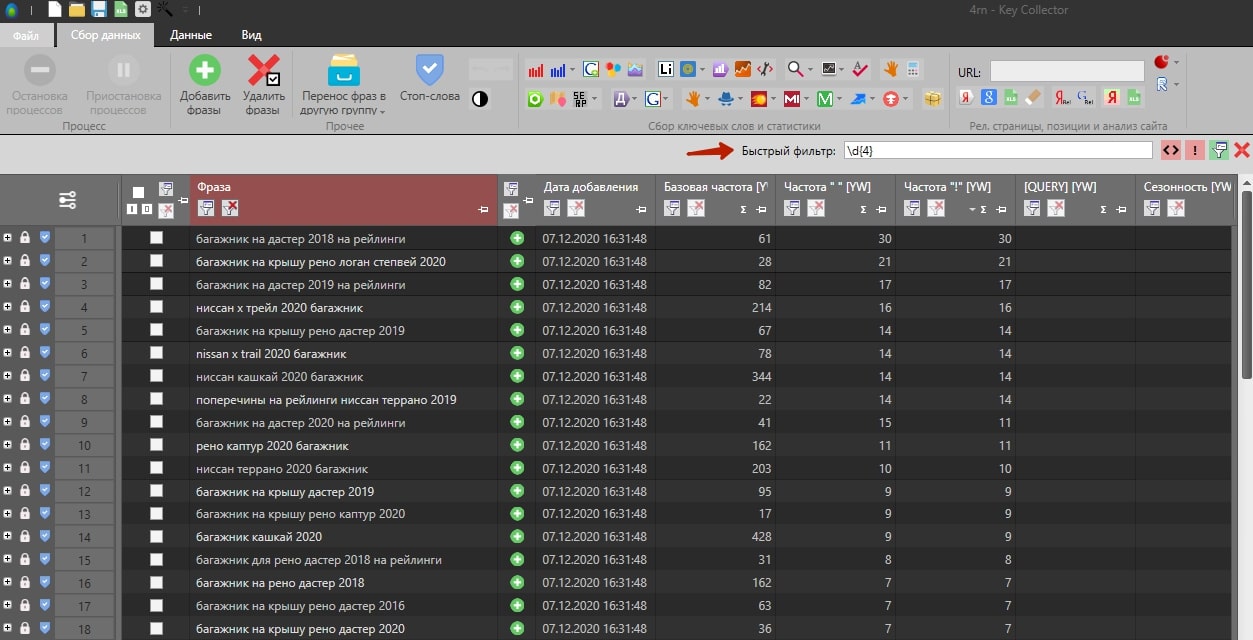
В итоге мы получим список фраз, которые удовлетворяют условию фильтрации и регулярному выражению.
Онлайн-сервисы для проверки регулярки
Regex101
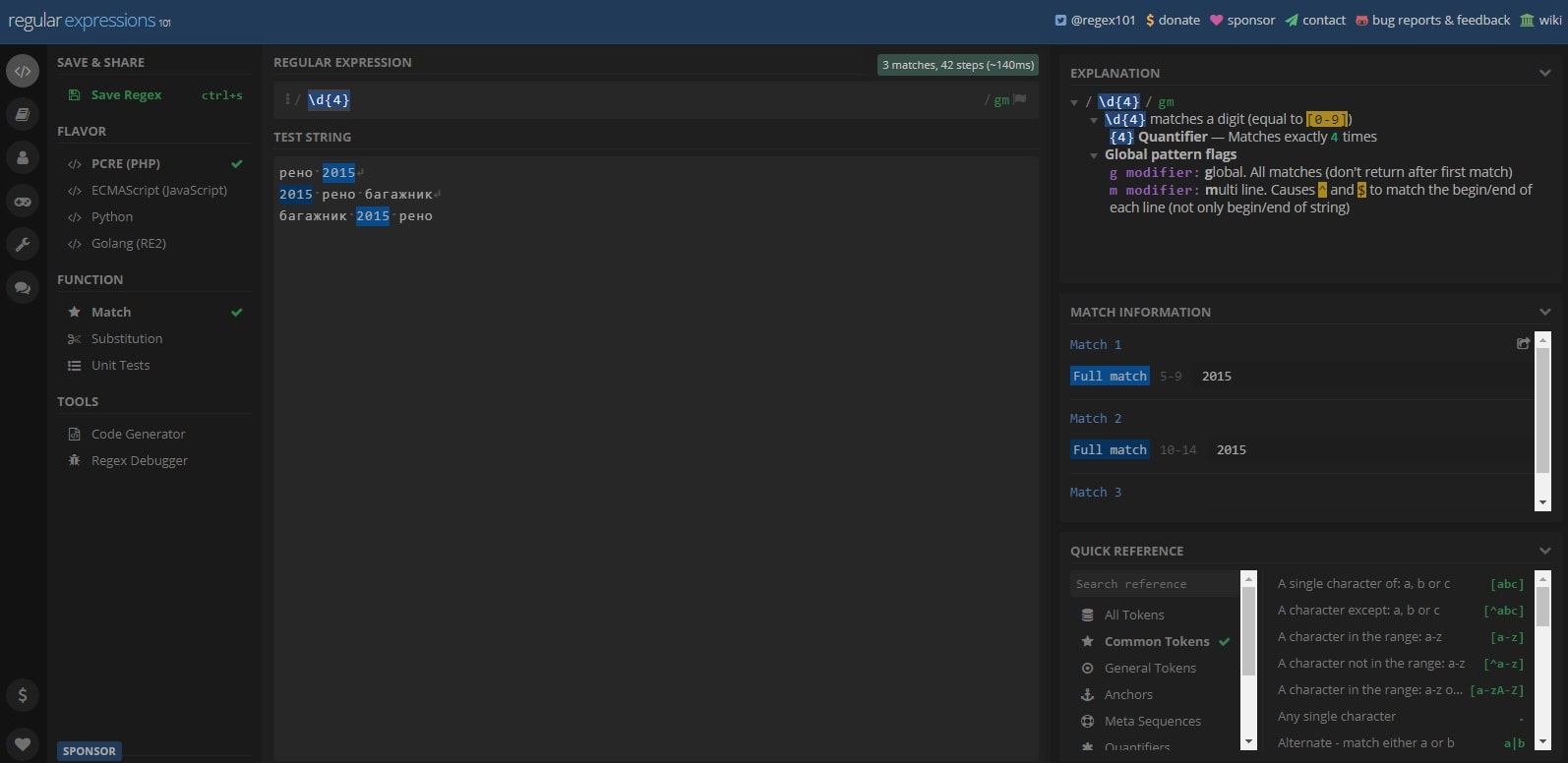
Regex101.com, пожалуй, самый удобный вариант онлайн-сервиса, где реализована проверка регулярных выражений. Предлагает поддержку нескольких языков, предусмотрен собственный справочник с детальным объяснением регулярок и подсказками, а также библиотека шаблонов.
Debuggex
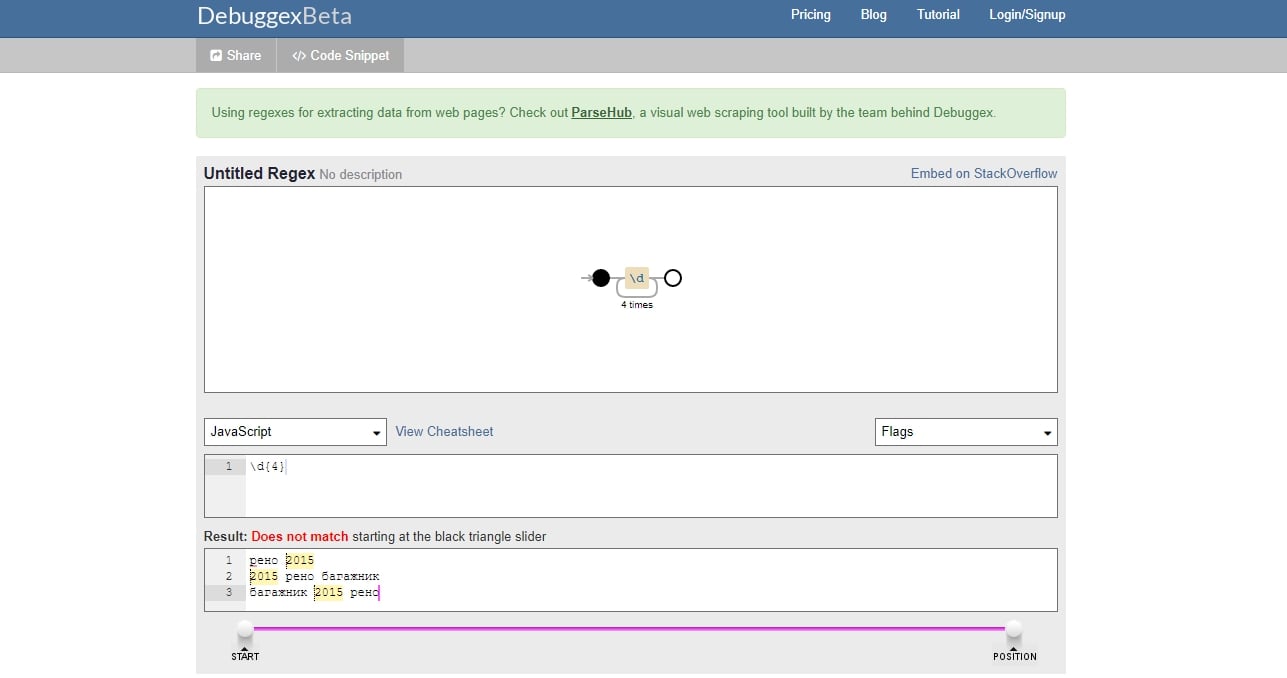
Debuggex имеет более ограниченный функционал, но позволяет визуализировать регулярное выражение в виде наглядной схемы, что позволяет лучше его понимать и в некоторых случаях более эффективно проводить отладку.
Tools.icoder.uz
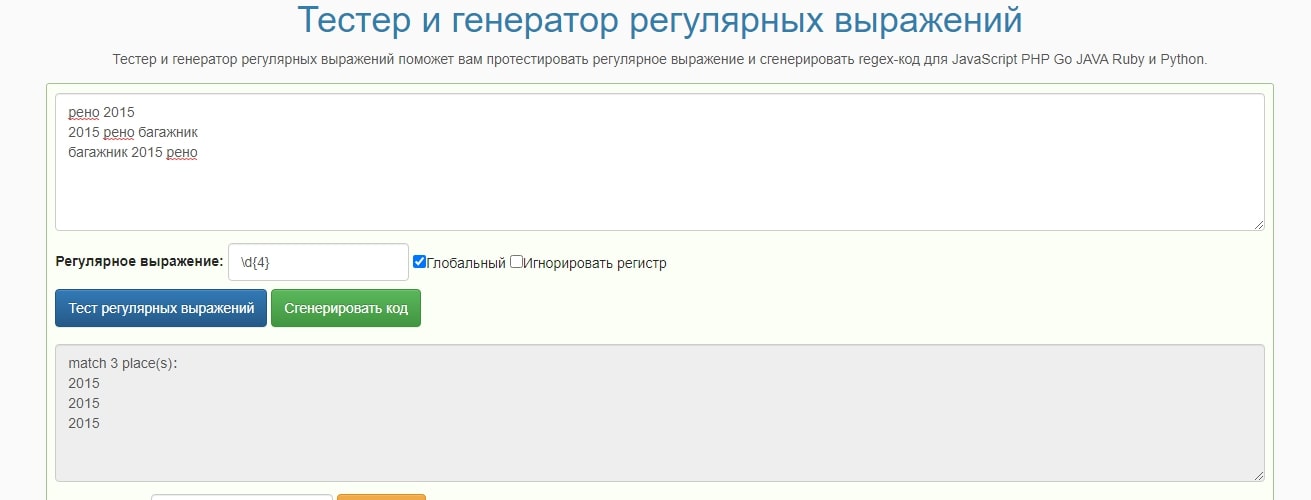
Tools.icoder.uz позволит произвести как онлайн-проверку регулярного выражения, так и замену содержимого. Имеет русскоязычный интерфейс, что станет преимуществом в сравнении с предыдущими двумя сервисами. Предусмотрена небольшая библиотека популярных шаблонов.
Бонус. Важно помнить, что одну и ту же задачу можно решить с помощью абсолютно разных регулярных выражений. Мы подготовили небольшую шпаргалку по ним.
| Якоря | Кванторы | ||
|---|---|---|---|
| ^ | Начало строки | * | 0 или больше |
| \A | Начало текста | *? | 0 или больше, нежадный |
| $ | Конец строки | ‘+ | 1 или больше |
| \Z | Конец текста | ‘+? | 1 или больше, нежадный |
| \b | Граница слова | ? | 0 или 1 |
| \B | Не граница слова | ?? | 0 или 1, нежадный |
| \< | Начало слова | {3} | Ровно 3 |
| \> | Конец слова | {3,} | 3 или больше |
| {3,5} | 3, 4 или 5 | ||
| {3,5}? | 3, 4 или 5, нежадный | ||
| Символьные классы | Специальные символы | ||
| \c | Управляющий символ | \ | Экранирующий символ |
| \s | Пробел | \n | Новая строка |
| \S | Не пробел | \r | Возврат каретки |
| \d | Цифра | \t | Табуляция |
| \D | Не цифра | \v | Вертикальная табуляция |
| \w | Слово | \f | Новая страница |
| \W | Не слово | \e | Escape-символ |
| Утверждения | Диапазоны | ||
| ?= | Вперед смотрящее | . | Любой символ, кроме переноса строки (\n) |
| ?! | Отрицательное вперед смотрящее | (a|b) | a или b |
| ?<= | Назад смотрящее | (…) | Группа |
| ?!= или ? | Отрицательное назад смотрящее | (?:…) | Пассивная группа |
| ?> | Однократное подвыражение | [abc] | Диапазон (a или b или c) |
| ?() | Условие [если, то] | [^abc] | Не a, не b и не c |
| ?()| | Условие [если, то, а иначе] | [a-q] | Буква между a и q |
| ?# | Комментарий | [A-Q] | Буква в верхнем регистре между A и Q |
| [0-7] | Цифра между 0 и 7 | ||
Расскажите, а какие у вас самые частые задачи в SEO, для которых используются регулярные выражения? Если же вы не нашли подходящих готовых решений, оставляйте комментарии – подумаем над ними вместе. 🙂
Необходим более глубокий анализ сайта? Обращайтесь к нам — мы сможем Вам помочь!
Еще по теме:
- Сливки SEO за 2018 год: лучшие руководства и сервисы в одной статье Весь год наши SEO-доктора делились опытом и полезностями, чтобы вы могли вылечить как можно больше сайтов. Если вы что-то пропустили или хотите освежить в памяти,...
- Акция: Что не так с моим сайтом? Бесплатная диагностика до 20 марта! Акция окончена Вы можете заказать платную диагностику. А чтобы не пропустить новые акции, следите за новостями: вступайте в группу в Facebook и подписывайтесь на блог....
- Новые санкции Яндекса, понижающие позиции сайта за некорректную рекламу Что произошло 24 апреля 2018 года Яндекс ввёл новый алгоритм, который понижает сайты, размещающие у себя некорректную рекламу. К ней относятся объявления, которые затрудняют восприятие...
- «Королёв»: действие алгоритма на практических примерах Что такое «Королёв»? 22 августа 2017 года Яндекс официально заявил о запуске нового поискового алгоритма «Королёв» (назван в честь города, как и большинство предыдущих поисковых...
- Как быстро продвинуть сайт (первоапрельский гайд) Создаём сайт Наполняем контентом Оптимизируем конверсии Добавляем CTR сниппетам Внешнее продвижение В заключение Прежде всего, хотим извиниться перед теми, кто удалил Яндекс.Метрику после предыдущей нашей...

Оцените мою статью:
 (6 оценок, среднее: 5,00 из 5)
(6 оценок, среднее: 5,00 из 5)Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.
