
- (Обновлено: ) Александр Я.

Поисковые алгоритмы постоянно развиваются, часто уже сами могут определить дубли страницы и не включать такие документы в основной поиск. Тем не менее, проводя экспертизы сайтов, мы постоянно сталкиваемся с тем, что в определении дублей алгоритмы еще далеки от совершенства. Вот что пишут о дублях представители Яндекса:
 Я думаю, не стоит надеяться, что в вашем случае алгоритм оценит все страницы правильно и его выбор совпадет с вашим 😉 – лучше самому избавиться от дублей на сайте.
Я думаю, не стоит надеяться, что в вашем случае алгоритм оценит все страницы правильно и его выбор совпадет с вашим 😉 – лучше самому избавиться от дублей на сайте.
Почему нужно избавляться от дублей?
Предлагаю для начала рассмотреть, чем опасны дубли страниц.
Ухудшается индексация сайта
Если в вашем проекте несколько тысяч страниц, и на каждую из них создается по одному дублю, то объем сайта уже «раздувается» в два раза. А что, если создается не один дубль, а несколько? В прошлом году мы проводили экспертизу новостного портала, в котором каждая новость автоматически публиковалась в семи разделах, то есть каждая страница сразу создавалась еще с шестью дублями.
Неправильно распределяется внутренний ссылочный вес
Часто дубли на сайте появляются в результате неправильных внутренних ссылок. В итоге страницы-дубли могут считаться более значимыми, чем основная версия. Не стоит забывать и про пользовательские факторы. Если посетитель попал на дубль страницы, то, соответственно, измеряются ее показатели, а не оригинала.
Изменение релевантной страницы в поисковой выдаче
Поисковый алгоритм в любой момент может посчитать дубль более релевантным запросу. Смена страницы в поисковой выдаче часто сопровождается существенным понижением позиций.
Потеря внешнего ссылочного веса
Пользователя заинтересовал ваш товар или статья, и он решил поделиться информацией и поставить на страницу ссылку. Если он был на странице-дубле, то сошлется именно на нее. В итоге вы потеряете полезную естественную ссылку.
Как найти дубли?
Теперь давайте рассмотрим, как можно найти внутренние дубли на сайте.
1. Анализ данных Google Webmasters
Пожалуй, самый простой из способов. Для того чтобы найти страницы дублей, вам будет достаточно зайти в панель инструментов, выбрать вкладку «Вид в поиске» и перейти по ссылке «Оптимизация html»:
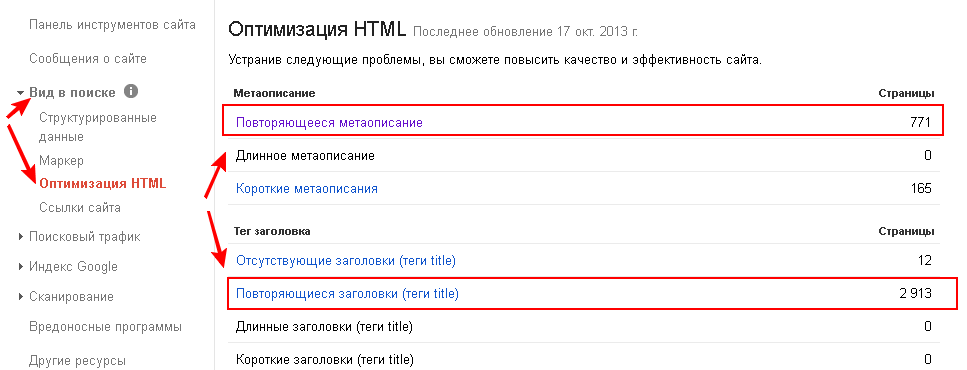
Наша цель – это пункты:
— «Повторяющееся метаописание». Здесь отображены страницы с одинаковыми описаниями (description);
— «Повторяющиеся заголовки (теги title)». В этом пункте находится список страниц с одинаковыми заголовками (Title).
Дело в том, что на страницах обычно совпадает не только контент, но и мета-данные. Проанализировав список страниц, отображаемых в этих вкладках, легко можно выявить такие дубли. Мы рекомендуем периодически проверять вышеупомянутые вкладки панели инструментов на наличие новых ошибок.
Проверить страницы на совпадающие заголовки можно даже в том случае, если доступа к панели у вас нет. Для этого вам нужно будет воспользоваться расширенным поиском поисковой системы или сразу ввести в поисковую строку соответствующий запрос.
Для Яндекса:
site: siteclinic.ru title:(анализ сайтов)
Для Google:
site: siteclinic.ru intitle:анализ сайтов
Разумеется, необходимо подставить свой домен и часть заголовка, дубль которого вы ищете.
2. Анализ проиндексированных документов
Анализ в первую очередь лучше проводить в той поисковой системе, в индексе которой находится больше всего страниц. В большинстве случаев это Google. С помощью оператора языка запросов «site» легко получить весь список проиндексированных страниц. Вводим в строку поиска:
site:siteclinic.ru (не забудьте указать имя своего домена) и получаем список проиндексированных страниц.
В конце списка вы увидите ссылку «Показать скрытые результаты». Нажмите на нее, чтобы увидеть более полный список страниц:

Просматривая выдачу, обращайте внимание на нестандартные заголовки и url страниц.
Например, вы можете увидеть, что в выдаче попадаются страницы с идентификаторами на конце, в то время как на сайте настроены ЧПУ. Нередко уже беглый анализ проиндексированных страниц позволяет выявить дубли или другие ошибки.
Если на сайте большой объем страниц, то при анализе может помочь программа Xenu. Об использовании этого инструмента можно прочесть на блоге Сергея Кокшарова.
3. Поиск дублей по части текста
Два предыдущих способа помогают выявить дубли в тех случаях, когда на страницах совпадают мета-данные. Но могут быть и другие ситуации. Например, статья на сайте попадает сразу в несколько категорий, при этом в title и description автоматически добавляется название категории, что делает мета-данные формально уникальными. В этом случае ошибки в панели инструментов мы не увидим, а при ручном анализе сниппетов страниц такие дубли легко пропустить.
Для того чтобы выявить на сайте подобные страницы, лучше всего подойдет поиск по части текста.
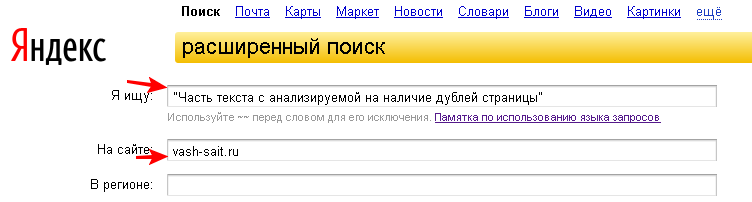
Для этого нужно воспользоваться инструментом «расширенный поиск» и произвести поиск на сайте по части текста страницы. Текст вводим в кавычках, чтобы искать страницы с таким же порядком слов и формой, как в нашем запросе.
Так выглядит расширенный поиск в Яндексе:
А вот так в Google:
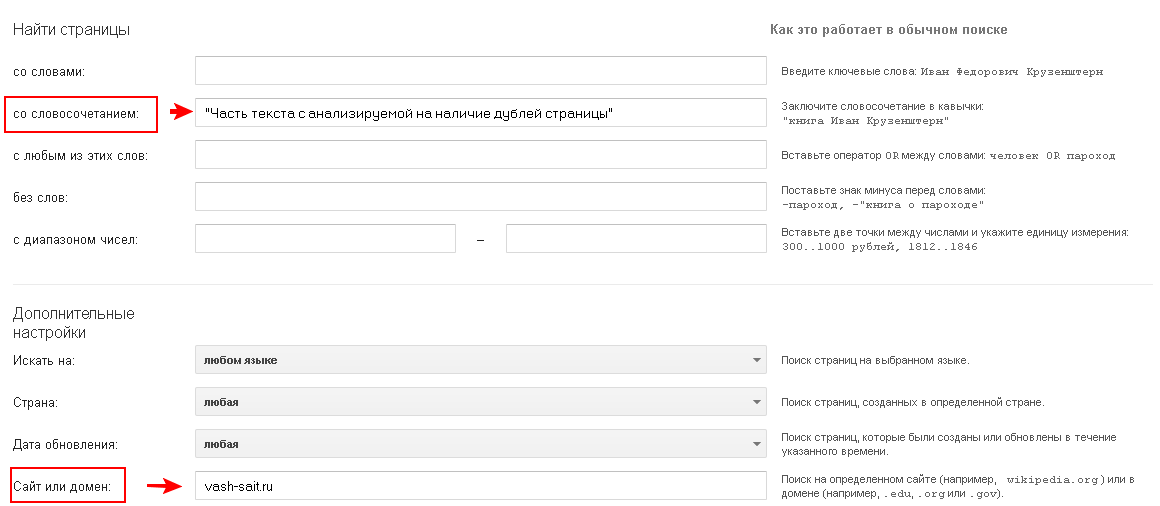
На сайтах может быть много сотен или даже тысяч страниц. Разумеется, не нужно анализировать все страницы. Их можно разбить по группам. Например, главная, категории, товарные карточки, новости, статьи. Достаточно будет проанализировать по 2-3 страницы каждого вида, чтобы выявить дубли или убедиться, что на сайте все в порядке.
Чистим сайт от дублей
После того как дубли обнаружены, можно приступать к их удалению.
Находим и устраняем причину появления дублей
Первое, что необходимо сделать – найти причину, из-за которой дубли на сайте появляются, и постараться ее устранить.
Причины могут быть различные, например:
- ошибки в логике структуры сайта;
- технические ошибки;
- различные фильтры и поиск по сайту.
В каждом случае ситуацию необходимо рассматривать индивидуально, но если дубли функционально не полезны, то от них лучше просто отказаться.
Указываем канонический адрес страницы
Если страницы-дубли по каким-то причинам нельзя удалить, то следует указать поисковым роботам, какая страница является основной (канонической). Google ввел для этого специальный атрибут rel=»canonical» (рекомендации по использованию атрибута).
Через некоторое время его стал поддерживать и Яндекс . И на сегодняшний день это основное официальное средство для борьбы с дублями страниц.
Использование 301 редиректа
До внедрения rel=»canonical» 301 редирект был основным способом склейки страниц-дублей. И сейчас разработчики и оптимизаторы продолжают активно использовать 301 редирект для переадресации на основное зеркало сайта или со страниц с «/» или без него на конце.
Запрет к индексации в robots.txt
В файле robots.txt мы можем запретить доступ к определенным разделам или типам страниц, например, страницам, формируемым в результате поиска по сайту. Но это не избавит нас от дублей страниц в Google. Дело в том, что доступ к страницам будет запрещен, но если страницы уже попали в индекс, они после добавления запрета исключены не будут.
Приведу цитату из рекомендаций Google:
Следует отметить, что даже если вы запретите поисковым роботам сканировать содержание вашего сайта с помощью файла robots.txt, возможно, что Google обнаружит его другими способами и добавит в индекс. Например, на ваш контент могут ссылаться другие сайты.
Для того чтобы страница была удалена из индекса, на нее необходимо добавить <meta name=»robots» content=»noindex»>, но при этом важно, чтобы страница не была закрыта в robots.txt. Иначе поисковый робот на нее не зайдет.
Еще одна цитата:
Если ваша страница продолжает появляться в результатах, вероятно, мы еще не просканировали ваш сайт после добавления тега. (Кроме того, если вы заблокировали эту страницу с помощью файла robots.txt, мы также не сможем увидеть этот тег.)
В связи с этим, если дубли на сайте уже есть, robots.txt не поможет удалить их из индекса Google.
Остается пожелать оптимизаторам успехов в борьбе с дублями и развитии своих проектов.
Еще по теме:
- Как можно улучшить поведенческие факторы в Google? Подскажите, какими способами можно улучшить поведенческие факторы в Google? Ответ Чтобы улучшить поведенческие факторы в Google, как бы это банально не звучало, нужно сосредоточиться на...
- Шеф, все пропало, или Как сделать базовый аудит сайта своими руками Сайт потерял трафик или позиции. Для того чтобы исправить ситуацию, важно понять причину. Сегодня мы расскажем, как провести первичную диагностику сайта. Статья будет полезна начинающим SEO-специалистам...
- Как лучше и правильно добавить изображения с другого сайта на свой? Нужны картинки с другого сайта. Как лучше сделать это? 1️⃣ Href на внешнею картинку. 2️⃣ Картинка на локальном сервере, с указанием активной ссылки на страницу...
- Как правильно использовать название категории в заголовках товаров и можно ли получить пессимизацию листинга при этом? Расскажите про вхождение названия категории в заголовок товара. Правильно его указывать или нет? Учитывает ли поисковая система его как остальной текстовый контент на странице? Можно...
- Как поступать со страницами сайта, которые быстро теряют свою актуальность? Есть сайт с прогнозами погоды, и под каждую неделю у нас отдельная страница. Но, как только неделя меняется, информация перестает быть актуальной, соответственно, и трафик...

Оцените мою статью:

 (8 оценок, среднее: 4,63 из 5)
(8 оценок, среднее: 4,63 из 5)Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.

Скажите пожалуйста где написать этот rel="canonical"?
На страницах сайта rel="canonical" размещается внутри раздела <head> с помощью атрибута Link
Пример: <link rel="canonical" href="канонический адрес"/>
В статье есть ссылка на рекомендации Google. Там все подробно расписано
https://support.google.com/webmasters/answer/139394?hl=ru
Очень грамотная статья!
Здравствуйте. Подскажите, пожалуйста, на сайте дубли: ЧПУ и /node/. Ноды я заблокировал в robots, но наверное поздно, так как они проиндексировались. Как я понимаю надо разблокировать их в robots и добавить rel="canonical" на страницы c указанием ссылки ЧПУ как основной(link rel="canonical" href="ЧПУ"). Но страницы ЧПУ и /nod/ это одна и та же страница. В нее и нужно прописивать этот тег? Извините за дотошность. Заранее спасибо.
Важно чтобы rel="canonical" был на странице дубле. Если при этом он будет также на основной странице не страшно. Доступ к категории нужно будет открыть в robots.txt, чтобы робот мог проиндексировать изменения.
Возможно в вашем случае лучше использовать 301 редирект (но здесь уже нужно детально анализировать ситуацию).
Мнение Мэтт Каттса: 301 редирект или canonical
Спасибо! Буду искать выход.
Здравствуйте! Я не могу понять, что имеется ввиду под словом страница или это нужно написать в зсголовке всего сайта или в каждой статье? Я и у них этого не понимаю и у вас так же написано и это непонятно где писать. Я же все равно не знаю где эти дубли, тем более редирект очень быстро срабатывает, так что их и не найти. Извените пожалуйста, у меня сайт уже год, а я это не могу понять.
Думаю сразу лучше привести пример.
site.ru/ — главная страница сайта
site.ru/katalog/ — страница каталога продукции
site.ru/katalog/tovar-1/ — страница товарной карточки
Также рекомендую почитать аналогичные рекомендации по использованию rel="canonical" Яндекса.
Если разобраться с ситуацией вам не удастся, лучше не вносите на сайт изменения самостоятельно а обратитесь за реализацией доработок к специалистам.
Ах, какая прелесть: "Если ваша страница продолжает появляться в результатах, вероятно, мы еще не просканировали ваш сайт после добавления тега. (Кроме того, если вы заблокировали эту страницу с помощью файла robots.txt, мы также не сможем увидеть этот тег.)
Спасибо, вот этого не знал. А то, что роботс — это так, ненадежный костыль, так это давно известно… Недавно сайт перескочил в хосте — был с www, стал без, хотя правильный хост был указан в роботсе, ну и ссылок с тысячу-полторы стоит с www, а вот перескочил… из-за сквозной ссылки в футере, похоже… Так что роботс — это вообще некий призрак, привидение… вроде и вот он, а особо никого не трогает…
Проверил свой сайт этим способом и честно говоря удивился, ни одного дубля страниц. Спасибо за статью, очень порадовали.
https://techaudit.site/ru/ — удобный инструмент поиска частичных дублей.